
【论文解读】小样本分割 | FSS1000 | CVPR2020
论文名称:“FSS-1000: A 1000-Class Dataset for Few-Shot Segmentation” 笔记作者:炼丹兄(已授权) 联系方式:微信cyx645016617 (欢迎交流,共同进步)
【预告】:近期会更新5篇CVPR2020到2021的小样本分割的文章心得

综述
文章贡献主要是两个:
提出了FSS-1000的小样本分割数据集; 并且用一个不是很创新的小样本框架来证明,在这个数据集上预训练的模型其实在各种小样本分割任务中都有不错的提升。
这里关于小样本任务的定义就不介绍啦。
FSS1000介绍
全程:Few-Shot Segmentation 1000
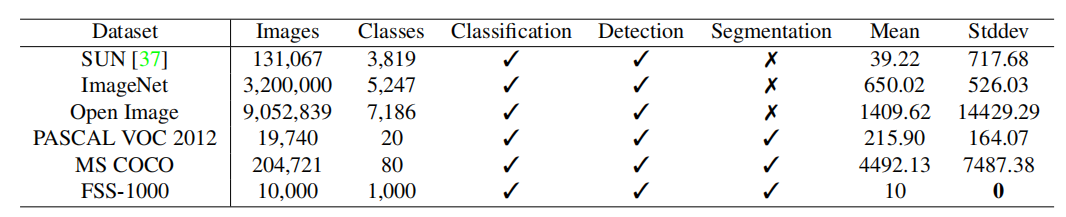
和COCO,imageNET的等数据集比较,这个FSS1000数据集包含1000个类别,每个类别包含10张带有标注的图像。1000个类别涵盖日常用到的类别,包含卡通、微小部件等。我甚至在里面发现了这个类别(颜色是BGR反序的):

数据集中的每张图像都是224x224x3的尺寸,每个图像中也只有单一的分割物体,就是说是对于单张图像是二分类,只有背景和前景的区别。
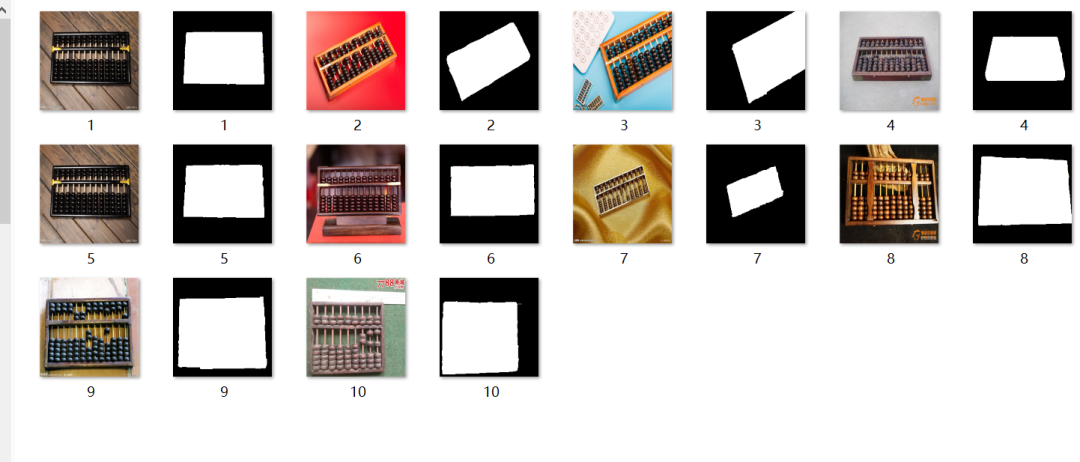
论文提出者把数据集分成了train和val,其中760类为train,240类为test。作者是使用240的test的每类的5个图片作为小样本的support set,也就是5-shot。
模型架构
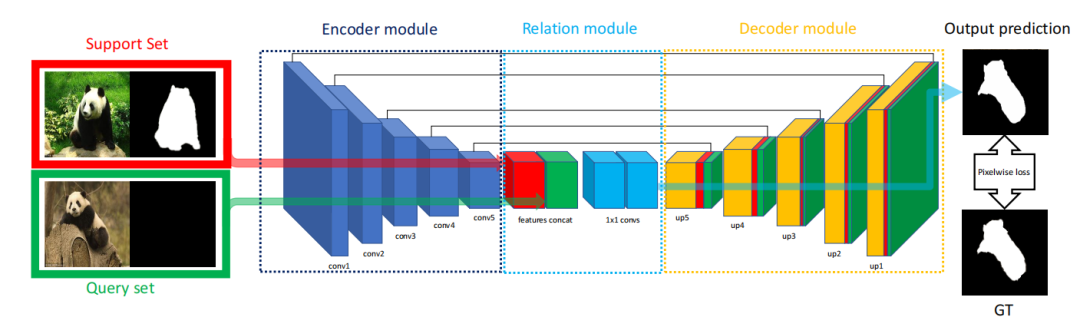
模型的结构符合常识。
小样本分割模型时要在760类物体上进行训练。而后再来一个新的物体,给你五张标注,你要能识别出来。这五张test数据集中的标注数据,是不能加入到模型的训练当中的。就是说,关键就是模型在训练的时候,就要学会比对mask,这样在test的时候,把有标注和没有标注的数据同时输入。模型自行从有标注的图像和mask中学习这次他要识别出来的物体,然后再没有标注的数据中展现。
【个人理解】:一般的分割任务是学习要分割对象的特性;小样本分割任务是要模型学习一种“照猫画虎”的能力。
模型结构包含三个部分:编码器E,相关模块R,解码器D。
输入的图像有标注的X1和无标住的图像X2经过编码器E,得到E(X1),E(X2); 对于K-shot的任务,就是有5个标注的图像的话,那五个图像都经过E,得到的结果进行平均。这样的话,不管是几shot,都可以得到一样的尺寸; 然后E(X1),E(X2)在R模块进行相关性考虑。其实作者采用的就是channel-wise的拼接; 之后这种粗糙的低分辨率的特征图,被放到decoder中还原到原图大小即可。 损失函数采用最简单的BCE二值交叉熵。
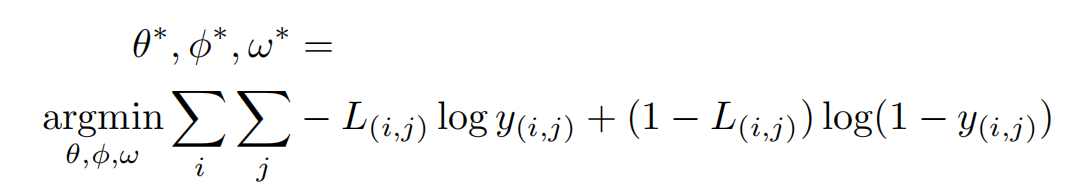
这就是整个流程了。模型结构合情合理,作为小样本分割的入门架构再合适不过了
往期精彩回顾 本站qq群851320808,加入微信群请扫码:
评论