
【论文解读】ICLR2020 | 深度自适应Transformer
作者 | kaiyuan 整理 | NewBeeNLP
一篇来自ICLR2020,facebook人工智能实验室的论文,关于改进Transformer推理速度的。
论文地址:https://arxiv.org/abs/1910.10073
写在前面
大模型在困难任务上表现非常好,而小模型也可以在比较简单的任务上表现出色。但是目前大模型在应用简单任务时的运算量同复杂任务一样,这就导致了不必要的资源浪费,此外还会导致推理速度变慢。对此,提出了一种depth-adaptive transformer,可以在推理阶段针对不同的token自动选择在合适的层进行停止并输出,在不损失模型效果的同时大大提高推理速度。
Anytime Prediction
传统的transformer decoder,所有的token都需要经过N个block,且最后的分类器是唯一的。但是一些简单的任务并不需要推理如此多步,可能在第 层模型已经得出结果了,再往上走并没有意义,于是可以选择在第 层就输出,这称为「动态计算(Dynamic Computation)」,
并且,每一层的分类器 可以选择不同或者相同。接下去就是怎么去实现上面的想法,即对于每个输入token,如何自动确定其在哪一层退出?文中提出了两种策略:
Aligned training
对齐训练会同时优化所有分类器,并假设当前状态之前的所有状态 均可以被看见,然后计算 项loss,如下图(a)
其中, 是第 层所有 损失和, 是 的加权平均(论文附录A实验说明平均加权的效果最好)。
Mixed training
但是上述对齐训练是不好实现的,因为不是所有token都在同一层输出,那么当有的token在较早的层输出后,在后续层计算时就无法看见它。解决这个问题一个直观的想法就是将已经输出的单元直接copy到上面一层即可,如下图(b)。对输入序列采样 个退出序列 ,并对每个退出序列计算损失,
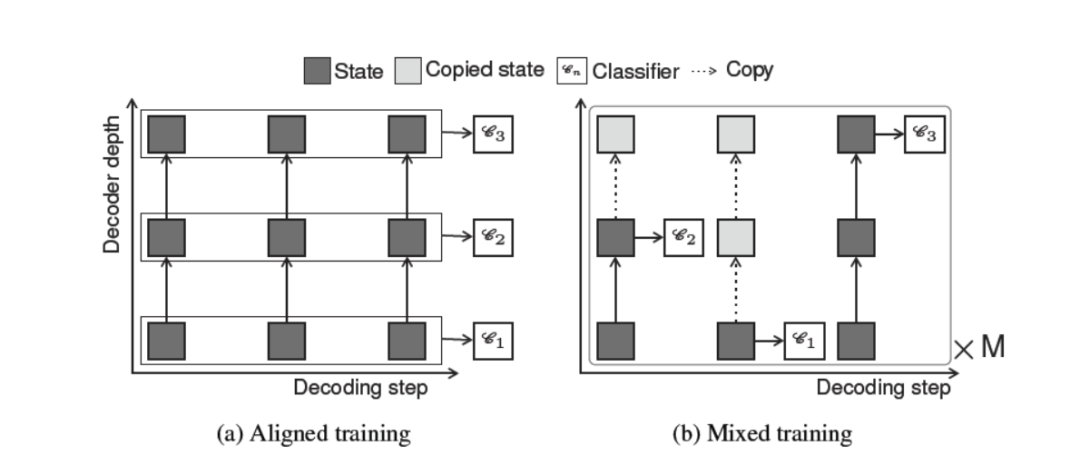
Adaptive Depth Estimation
自适应深度估计。上文还有一个问题待解决:如何采样退出序列?提出了两种策略:
「sequence-specific」:对应于 aligned training,所有token都在同一层退出;「token-specific」:对应于 mixed training,每个token可能在不同的层退出;
表示第 步对应的退出层参数分布,其中 表示 在第 层退出并得到预测 的概率, 表示真实分布,使用下式优化:
总体的损失函数为:
Sequence-Specific Depth
在该种模式下,所有token都在同一层退出,所以我们不考虑time-step 。通过将encoder输出的平均值 送到多项式分类器,我们得到分布 :
接下来怎么得到真实分布 呢?本文提出了两种策略:
「Likelihood-based」:基于每个块之后整个序列的似然性,并且以Dirac delta为中心对退出进行了优化,从而使序列似然性最高,
并且还可以加入正则项鼓励更低的退出层
「Correctness-based」:基于似然的方式无法判断最大的似然是不是正确的序列,因此基于正确性的方式选择 正确字符最大分数的最低的层。具体来说,对每个层,我们计算在该层上所有正确预测的字符数,然后选择最大正确数的一层,并同样加上正则项:
Token-Specific Depth
基于token的方式对每个token自动学习在哪一层退出,提出两种exit distribution 的计算方式:
「Multinomial」:多项分布, 表示第一层decoder的输出
「Poisson Binomial」:泊松二项分布, 表示停止概率(halting probability),其对应有一个阈值 ,当 超过这个阈值时即退出否则继续往上走直至结束
接下去也是对真实分布的计算,提出了三种策略:
「Likelihood-based」:基于似然的方式在每一步选择似然最大的层退出,
但是显然,这种方法是贪心做法,我们还想要考虑未来的字符,所以本文考虑一个光滑化(smoothed)似然,它考虑附近的几个字符:
「Correctness-based」:基于正确性的方式,
「Confidence thresholding」:基于自信度阈值,定义了一个自信度阈值 ,当当前输出 的最大得分超过阈值时,即选择退出。其中 是通过验证集确定的。
上述几种方法的示意图: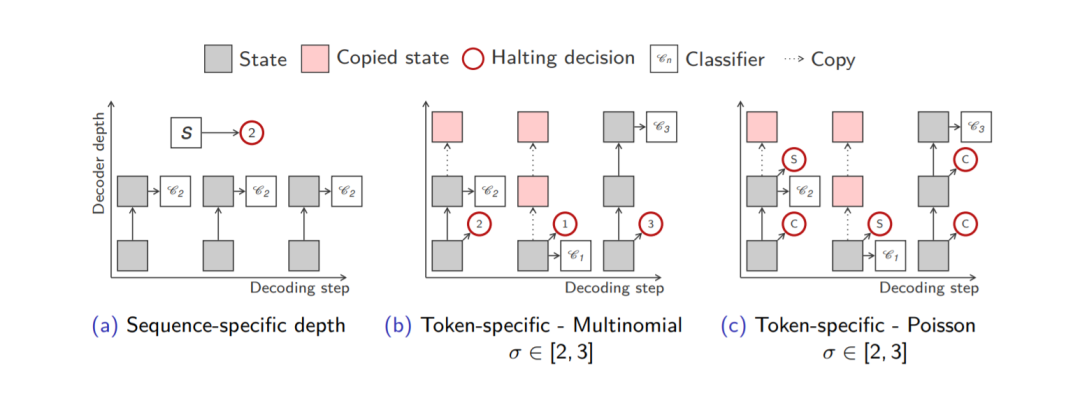
一些结论
Aligned training效果要优于Mixed training; 用对齐训练方法得到的模型,在 的时候,差不多就能超过baseline模型(传统Transformer),而Possion方法大体上比多项分布好; 更多更详细的实验分析推荐阅读reference里的作者PPT分享; 整体感觉和之前介绍过的Universal Transformer很像,都是采用dynamic computation的思想。但是很多细节还是不同,比如没有大型共享的Transformer层,并且本文主要关注动态停止策略设计等等:
There are a number of differences to universal transformer (UT): UT repeatedly applies the same layer for a number of steps, while as our approach applies different layers at every step. The dynamic computation in UT considers a single type of mechanism to estimate the number of steps (=network depth) while as we consider a number of mechanisms and supervision regimes. Moreover, dynamic computation was not actually used for the machine translation experiments in the UT paper (it was used for other tasks though), the authors used a fixed number of steps for every input instead.
Open Review[1]DAT作者PPT分享[2]
本文参考资料
Open Review: https://openreview.net/forum?id=SJg7KhVKPH
[2]DAT作者PPT分享: http://elbayadm.github.io/assets/talks/anytime/decore_04102019.pdf
- END -
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/yFQV7am
本站qq群1003271085。
加入微信群请扫码进群: