
YOLO |多域自适应MSDA-YOLO解读,恶劣天气也看得见(附论文)


本文介绍了一种新的多尺度域自适应YOLO(MS-DAYOLO)框架,该框架在YOLOv4检测器的不同尺度上使用多个域自适应路径和相应的域分类器来生成域不变特征。
1简介
Domain Adaptation在解决许多应用中遇到的Domain Shift问题方面发挥了重要作用。这个问题的出现是由于用于训练的源数据的分布与实际测试场景中使用的目标数据之间存在差异。

本文介绍了一种新的多尺度域自适应YOLO(MS-DAYOLO)框架,该框架在YOLOv4检测器的不同尺度上使用多个域自适应路径和相应的域分类器来生成域不变特征。实验表明,当使用本文提出的MS-DAYOLO训练YOLOv4时,以及在自动驾驶应用中具有挑战性的天气条件的目标数据上进行测试时,目标检测性能得到了显著改善。
2方法
2.1 YOLO V4简述
相对于YOLO V3,YOLOv4包含了许多新的改进和新技术,以提高整体检测精度。
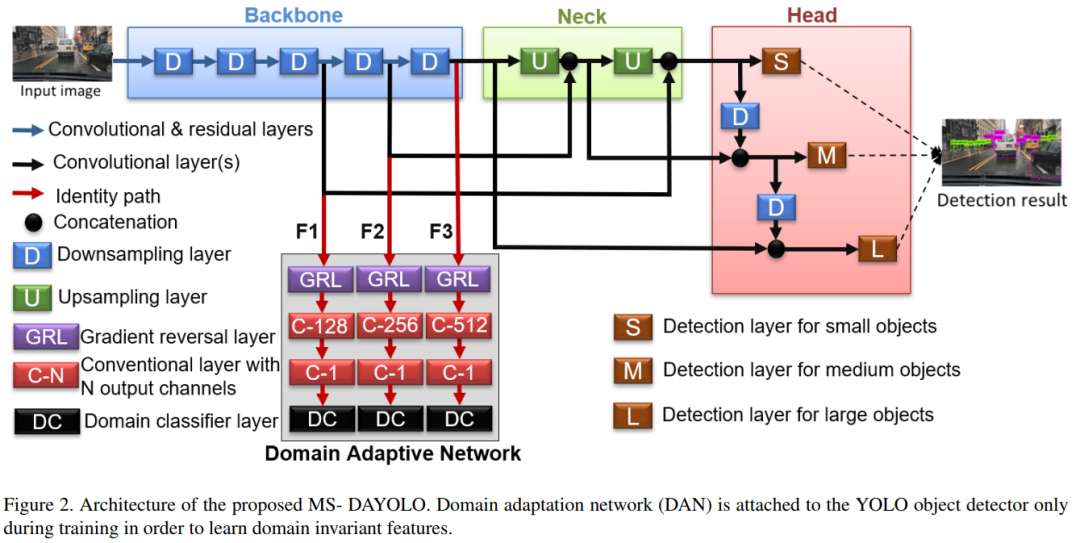
如图所示YOLOv4有3个主要部分:backbone、neck和head。
backbone负责提取不同尺度下的多层特征。
neck使用上采样层将backbone的3种不同尺度的特征聚集在一起,并将它们输入head。
最后,head预测目标周围的边界框以及与每个边界框相关联的类别概率。
本文作者的目标是将域适应应用于这3个特征(图中的F1、F2、F3),使它们对不同尺度的域变化具有鲁棒性,从而使它们在基于域适应的训练中向域不变性收敛。
2.2 Domain Adaptive Network for YOLO
提出的域自适应网络(DAN)仅在训练时附加到YOLOv4中以学习域不变特征。对于推理,在推理阶段,将使用原始的YOLOv4体系结构中使用领域自适应训练的权重(没有DAN网络)。因此,本文所提出的框架不会增加推理过程中底层检测器的复杂性。
DAN使用backbone的3个不同的尺度特征作为输入。它有几个卷积层来预测域类。然后,利用二元交叉熵计算域分类损失(Ldc):
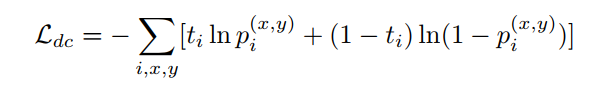
这里为第个训练图像的ground truth域标签,其中为源域,为目标域。是第个训练图像在位置的特征图。
DAN通过最小化这种上述损失来区分源域和目标域。另一方面,为了最大限度地学习域不变特征,对主干也进行了优化。因此,对于这2个域,backbone的特征应该是难以区分的。因此,这将提高目标域的目标检测性能。
为了解决联合最小化和最大化问题,作者采用了对抗学习策略。通过在backbone网络和DAN网络之间使用梯度反转层(GRL)来实现这个矛盾的目标。
GRL是一个双向算子,用于实现2个不同的优化目标。在前向传播方向上,GRL作为恒等算子。这导致了在DAN内执行局部反向传播时最小化分类错误的标准目标。另一方面,向主干网络反向传播时,GRL变成一个负标量。因此,在这种情况下,它会导致最大的二分类错误,这种最大化促进了由backbone生成领域不变特征。
为了计算检测损失(ldt),只使用源图像。因此,通过最小化ldt, YOLOv4的所有3个部分(即backbone, neck和head)都得到了优化。另一方面,利用源标记图像和目标未标记图像计算域分类损失(Ldc),Ldc通过最小化来优化DAN, Ldc通过最大化来优化backbone。因此,Ldet和Ldc都被用来优化backbone。换句话说,通过最小化以下总损失,backbone被优化了:
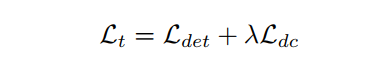
其中是GRL的一个负标量,用来平衡检测损失和域分类损失。事实上,是用来优化DAN对backbone的影响。
2.3 DAN Architecture
与在Domain Adaptive Faster R-CNN架构中只对特征提取器的最终尺度应用域自适应不同,本文分别开发了3个尺度的域自适应来解决梯度消失问题。也就是说,只对最终的尺度(F3)进行域自适应,由于之前的尺度(F1和F2)之间有很多层,存在梯度消失的问题,因此对之前的尺度(F1和F2)没有显著影响。
因此,作者采用了一个多尺度策略,将主干的三个特征F1、F2和F3通过三个相应的grl连接到DAN,如图2所示。对于每个尺度,GRL之后有2个卷积层,第1个卷积层将特征通道减少一半,第2个卷积层预测域类概率。最后,利用域分类器层计算域分类损失。
3实验
3.1 Clear=>Foggy
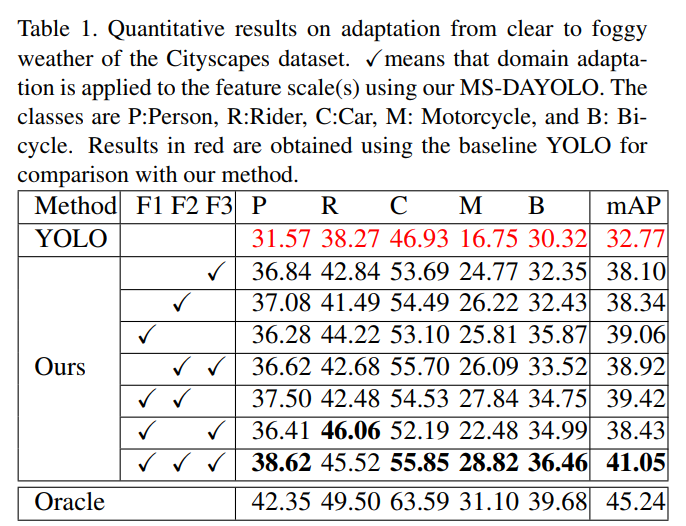
从这些结果可以看出,将域自适应应用于所有3个特征尺度提高了目标域的检测性能,取得了最好的结果。此外,作者提出的MS-DAYOLO在性能上大大优于原来的YOLOv4方法,几乎达到了理想(oracle)场景的性能。

3.2 Sunny=>Rainy
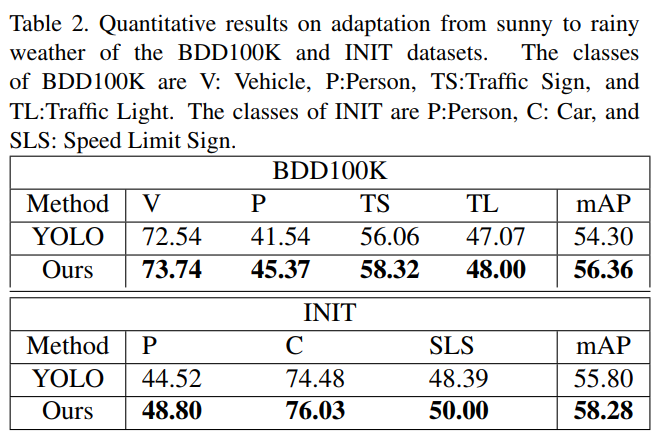
结果如表2所示。在2个数据集中,本文的方法都比原始的YOLO得到了明显的性能提升。
4参考
[1].Multiscale Domain Adaptive YOLO for Cross-Domain Object Detection
5推荐阅读

Transformer | 没有Attention的Transformer依然是顶流!!!

项目实践 | 从零开始边缘部署轻量化人脸检测模型——EAIDK310部署篇

项目实践 | 从零开始边缘部署轻量化人脸检测模型——训练篇

Google新作 | 详细解读 Transformer那些有趣的特性(建议全文背诵)

极品Trick | 在ResNet与Transformer均适用的Skip Connection解读
本文论文原文获取方式,扫描下方二维码
回复【MDA-YOLO】即可获取项目代码
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
