
如何快速从 Kubernetes 事件中找到有价值的信息

文章作者:Nate Matherson,ContainIQ 联合创始人和首席执行官
对于当今的工程团队来说,太多的监视和警报疲劳是一个真正的问题。现在有很多开源和第三方工具可以解决这些问题。这听起来总是像是真的,而且很可能是真的。但是,如果我告诉你,我最喜欢的一个替代方案就在你面前,并且几乎可以立即从 Kubernetes API 访问,你会怎么做呢?我说的是 Kubernetes 事件。
Kubernetes 事件为集群运行状况和性能提供了独特而清晰的见解。在数据太多的日子里,我发现 Kubernetes 事件在没有太多干扰的情况下提供了清晰的见解。
在本文中,我们将了解 Kubernetes 事件类型,帮助你访问和存储事件,并建议一些大多数团队(无论大小)都会觉得有用的提醒。
什么是 Kubernetes 事件?类型和例子
Kubernetes 事件是一个对象,它显示了集群、节点、pod 或容器中正在发生的事情。这些对象通常是根据 K8s 系统中发生的更改而生成的。Kubernetes API Server 允许所有核心组件创建这些事件。通常,每个事件都伴随着一条日志消息。然而,这两者是非常不同的,不会以任何其他方式影响彼此。
关于 Kubernetes 事件需要注意的一件重要的事情是,它们在默认情况下会在一段时间后被删除,通常在一个小时以内。因此,你必须在重要事件发生时观察并收集它们。
访问 Kubernetes 事件可以使用如下命令:
kubectl get event
结果是这样的:

新启动节点的事件
正如你所看到的,许多 Kubernetes 事件都是由节点状态的改变引起的。每个事件都有一个 Reason 字段。你可以使用这个字段来确定 K8s 事件对象的类型。以下是一些基于事件原因的标准分类。
失败事件
当 K8s 创建容器或其他资源失败时,将生成失败事件。这可能是由于错误的镜像、输入错误、不充分的原因,以及许多不同的原因。几乎可以肯定的是,失败事件会导致应用的功能失效;因此,监视这些类型的事件是必要的。
FailedToCreateContainer、FailedToStartContainer、FailedToPullImage、FailedToKillPod 等都是失败事件的例子。
驱逐事件
驱逐事件经常发生,因为 K8s 经常会介入并驱逐流氓容器和 pod(那些不必要地消耗大量资源的容器和 pod)。虽然这是预期的行为,但你仍然需要注意这些事件的发生。大量的驱逐表明你没有在系统中设置适当的阈值。通常情况下,K8s 可能无法确定要驱逐的最佳实体,从而导致不相关的驱逐,从而损失正常运行时间。
与节点相关的事件
许多 K8s 事件都基于节点及其生命周期活动。你可能已经注意到上面示例中的 NodeHasSufficientMemory、NoteHasSufficientPID、NodeReady 和其他事件。这些信息传递与节点相关的状态变化,在查找系统不稳定行为的来源时可以派上用场。
与存储相关的事件
所有基于云的应用都以这样或那样的方式利用存储空间。K8s 主要通过 Docker 连接 AWS、GCP 等外部服务或内部资源进行存储。在某些情况下,pod 可能无法挂载存储资源。你应该查看 FailedMount 和 FailedAttachVolume 事件,以确定错误的存储挂载情况。
调度事件
调度事件可以洞察资源管理策略的效率。如果你没有很好地管理你的资源,可能没有任何剩余来分配给新的 pod。内存或 CPU 不足通常是罪魁祸首,在大多数情况下,你会收到一个 FailedScheduling 事件,其中清楚地描述了为什么调度不能发生。
访问 Kubernetes 事件
要访问 Kubernetes 事件,可以对 pod 执行如下命令:
kubectl describe <podname>
或者,如果需要根据事件类型或其他字段查看更大的事件集合,可以执行以下命令:
kubectl get events –field-selector type!=Normal
虽然这些命令为你提供了命令行上的最新事件,但对于需要进行历史数据分析的大规模部署,它们将不会有帮助。可以使用如下命令导出 Kubernetes API 中的事件数据,进行详细分析:
kubectl get events -o json
这将导出最新的事件到一个 JSON 文件,你可以导入到你最喜欢的可视化工具,以获得更多的见解。
如何收集和存储事件
上面讨论的最后一种方法是从 Kubernetes 导出事件的最原始的方法之一。还有其他各种技术可以用来安全地收集和存储事件。下面是一些最常见的。
原生观看和导出事件
Kubectl 提供了另一个方便的命令来监视系统中发生的事件:
kubectl get events –watch
这将开始流事件到你的终端。同样,这对于分析和可视化不是很有用。因此,你应该考虑将其与第三方日志操作器(如Banzai Cloud 的[1])耦合起来进行分析。
KubeWatch
KubeWatch[2]是一个很棒的开源工具,可以观看 K8s 的活动并将其流媒体到第三方工具和网络钩子上。你可以将其配置为在 Slack 通道中发送重要状态更改的消息。你还可以使用它将事件发送到分析和提醒工具(如 Prometheus)。
你可以通过 kubectl 或 helm 等你最喜欢的 Kubernetes 工具来安装 KubeWatch。下面是 KubeWatch 的 Slack 通知的简图:
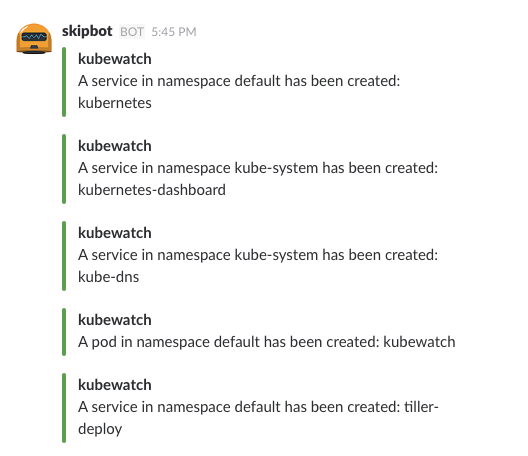
KubeWatch Slack Notifications(来源:KubeWatch)
KubeWatch 提供了简单的设置过程,但不提供独立的存储或管理功能。此外,你也没有获得任何度量或日志记录功能。
Event Exporter
Kubernetes Event Exporter[3]是 K8s 中原生观看方法的一个很好的替代方案。它允许你持续监视 K8s 事件,并在需要时列出它们。它还从收集的数据中提取了大量的指标,如事件计数、独特事件计数等,并为你提供了基本的监视设置。它安装起来非常容易,在使用一个更全面的工具之前,可以先试用它。
EventRouter
EventRouter[4]是另一个收集 Kubernetes 事件的开源工具。它可以轻松地设置和将 Kubernetes 事件流到多个目标。然而,就像 KubeWatch 一样,它也不提供查询或持久性特性。你需要将其与第三方存储和分析工具连接起来,以获得完整的体验。
一旦了解了监视目标并制定了策略,就可以考虑转向专用的付费 K8s 事件监视服务。你可以在各种平台上获得强大的查询功能和警报。
常见的警告事件
实时观察 K8s 事件对于了解系统中发生的情况至关重要。但是,你还需要设置一个可靠的警报策略,以便在异常或紧急情况下通知你。
根据经验,你应该密切关注失败事件和调度事件,因为忽略这些事件会破坏应用的功能。你可以将被驱逐的事件设置为低优先级,因为它们通常是由 K8s 的例行清理生成的。特定于节点和特定于存储的事件必须手动选择以发出警报(虽然知道 NodeReady 是一个很好的事件,但你不需要每次都为它发出警报)。
大多数工具都允许通过网络钩子或 Slack 等通用协作平台发送警报。虽然这很简单,设置起来也很容易,但是你可以更进一步,将监视工具连接到更高级的警报平台。Prometheus 中的AlertManager[5]也是一个不错的选择。你还可以考虑使用基于 SaaS 的解决方案,如ContainIQ[6],它具有专门的接口,用于创建警报条件、在广泛的平台上发送警报条件,以及将事件与其他指标关联起来的能力。
总结
Kubernetes 事件是监视 K8s 集群运行状况和活动的好方法。然而,当它们与实用的策略和广泛的工具集结合在一起时,会变得更加强大。本指南帮助你理解 Kubernetes 事件的重要性,以及如何从它们中汲取最大的价值。
参考资料
Banzai Cloud 的: https://github.com/banzaicloud/logging-operator
[2]KubeWatch: https://github.com/bitnami-labs/kubewatch
[3]Kubernetes Event Exporter: https://github.com/caicloud/event_exporter
[4]EventRouter: https://github.com/heptiolabs/eventrouter
[5]AlertManager: https://prometheus.io/docs/alerting/latest/alertmanager/
[6]ContainIQ: https://www.containiq.com/kubernetes-monitoring
本文转载自:「CNCF」,原文:https://tinyurl.com/y6a3dvya,版权归原作者所有。
有收获,点个在看
