
我今天拆了公司的“烂系统”,老板:你可以另谋高就了...
Python涨薪研究所
共 6518字,需浏览 14分钟
·
2021-04-11 23:47

源 /cnblog 文/ zhanlijun
本篇文章作者给大家分享一个复杂系统的拆分改造实践!
为什么要拆分?

应用间耦合严重。系统内各个应用之间不通,同样一个功能在各个应用中都有实现,后果就是改一处功能,需要同时改系统中的所有应用。 这种情况多存在于历史较长的系统,因各种原因,系统内的各个应用都形成了自己的业务小闭环。 业务扩展性差。数据模型从设计之初就只支持某一类的业务,来了新类型的业务后又得重新写代码实现,结果就是项目延期,大大影响业务的接入速度。 代码老旧,难以维护。各种随意的 if else、写死逻辑散落在应用的各个角落,处处是坑,开发维护起来战战兢兢。 系统扩展性差。系统支撑现有业务已是颤颤巍巍,不论是应用还是DB都已经无法承受业务快速发展带来的压力。 新坑越挖越多,恶性循环。不改变的话,最终的结果就是把系统做死了。

拆前准备什么?
多维度把握业务复杂度

定义边界,原则:高内聚,低耦合,单一职责
确定拆分后的应用目标
确定当前要拆分应用的架构状态
例如,代码情况、依赖状况,并推演可能的各种异常。
给自己留个锦囊,“有备无患”
放松心情,缓解压力
改造实践
DB 拆分实践
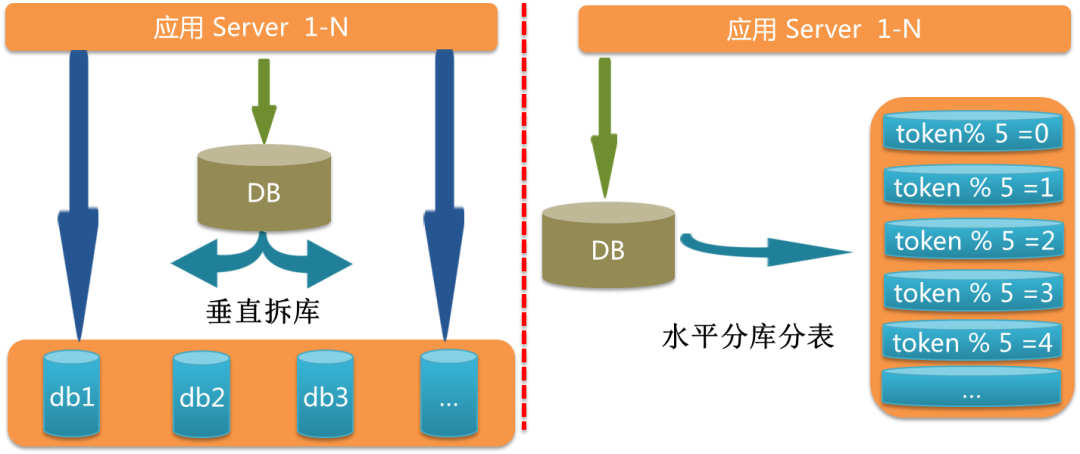
①主键 id 接入全局 id 发生器

Snowflake:非全局递增。 MySQL 新建一张表用来专门生成全局唯一 id(利用 auto_increment 功能)(全局递增)。 有人说只有一张表怎么保证高可用?那两张表好了(在两个不同 db),一张表产生奇数,一张表产生偶数。或者是 n 张表,每张表的负责的步长区间不同(非全局递增) ……
对按主键 id 排序的 SQL 要提前改造。因为 id 已经不保证递增,可能会出现乱序场景,这时候可以改造为按 gmt_create 排序。 报主键冲突问题。这里往往是代码改造不彻底或者改错造成的,比如忘记给某一 insert sql 的 id 添加 #{},导致继续使用自增,从而造成冲突。

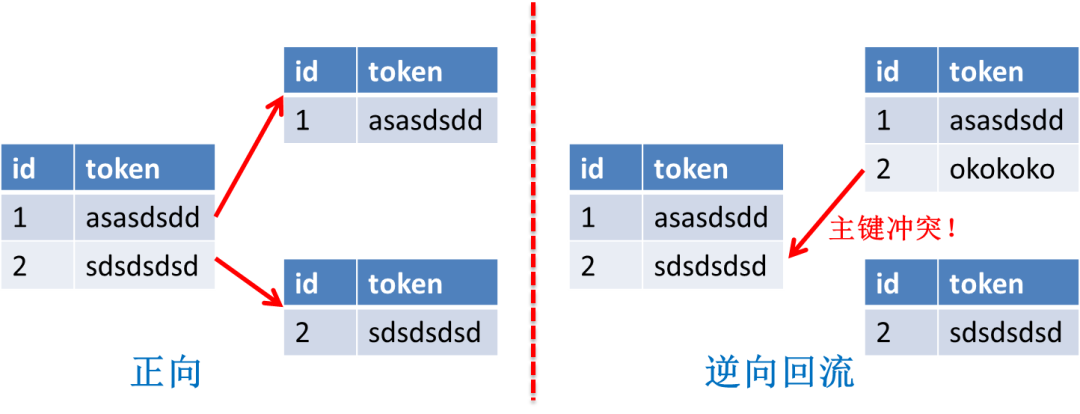
②建新表&迁移数据&binlog 同步
cannal/otter:https://github.com/alibaba/canal?spm=5176.100239.blogcont11356.10.5eNr98
https://github.com/alibaba/otter/wiki/QuickStart?spm=5176.100239.blogcont11356.21.UYMQ17
③联表查询 SQL 改造

适合 job 类的 SQL,或改造后 RPC 查询量较少的 SQL。 不适合大数据量的实时查询 SQL。

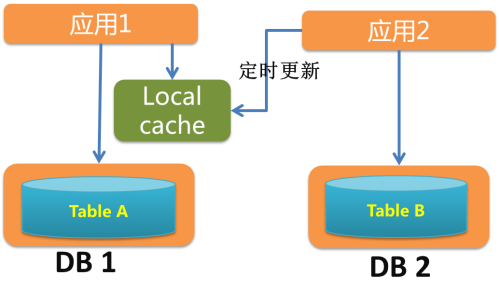
④切库方案设计与实现(两种方案)
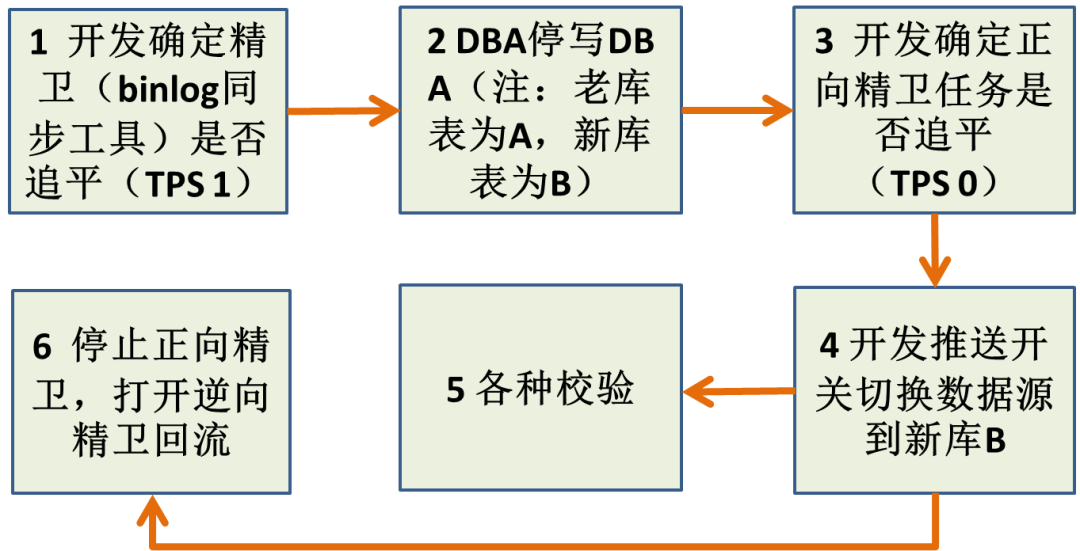
如果要回滚得联系 DBA 执行线上停写操作,风险高,因为有可能在业务高峰期回滚。 只有一处地方校验,出问题的概率高,回滚的概率高。
SQL 联表查询改造不完全。 SQL 联表查询改错&性能问题。 索引漏加导致性能问题。
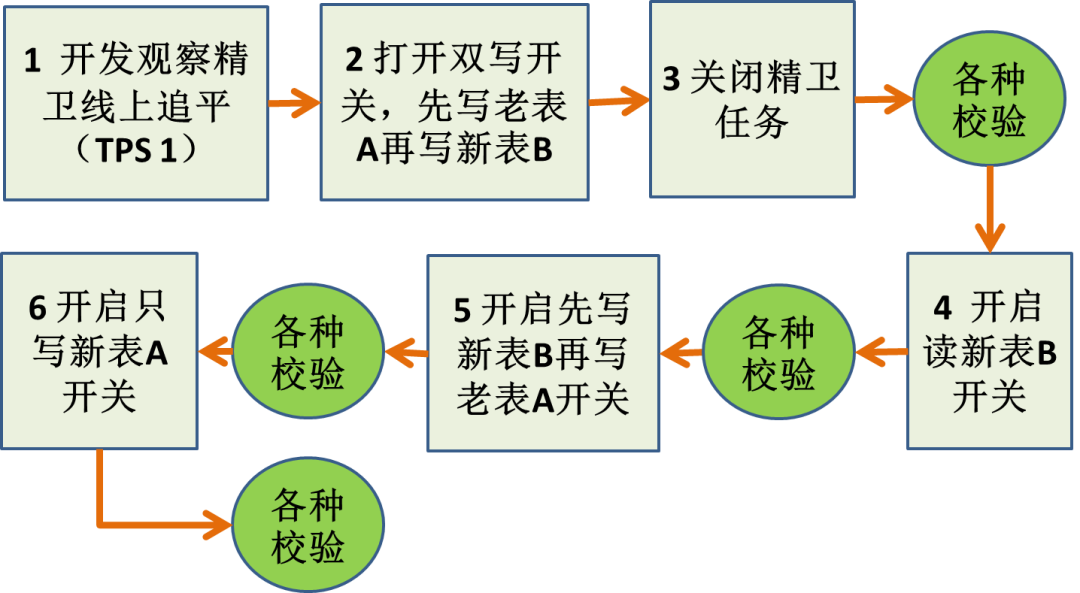
将复杂任务分解为一系列可测小任务,步步为赢。 线上不停服,回滚容易。 字符集问题影响小。
流程步骤多,周期长。 双写造成 RT 增加。
⑤开关要写好
拆分后一致性怎么保证?
分布式事务,性能较差,几乎不考虑。 消息机制补偿(如何用消息系统避免分布式事务?) 定时任务补偿用得较多,实现最终一致,分为加数据补偿,删数据补偿两种。
应用拆分后稳定性怎么保证?

遵循接口最少暴露原则:很多同学搭建完新应用后会随手暴露很多接口,而这些接口由于没人使用而缺乏维护,很容易给以后挖坑。听到过不只一次对话,“你怎么用我这个接口啊,当时随便写的,性能很差的”。 不要让使用方做接口可以做的事情:比如你只暴露一个 getMsgById 接口,别人如果想批量调用的话,可能就直接 for 循环 RPC 调用,如果提供 getMsgListByIdList 接口就不会出现这种情况了。 避免长时间执行的接口:特别是一些老系统,一个接口背后对应的可能是 for 循环 select DB 的场景。 …
按应用优先级进行流控:不仅有总流量限流,还要区分应用,比如核心应用的配额肯定比非核心应用配额高。 业务容量控制:有些时候不仅仅是系统层面的限制,业务层面也需要限制。举个例子,对 Saas 化的一些系统来说,“你这个租户最多 1w 人使用”。
正则匹配耗 CPU 耗性能的 job 优化、降级、下线(循环调用 RPC 或SQL) 慢 SQL 优化、降级、限流 Tair/Redis、DB 调用量要可预测 例:Tair、DB
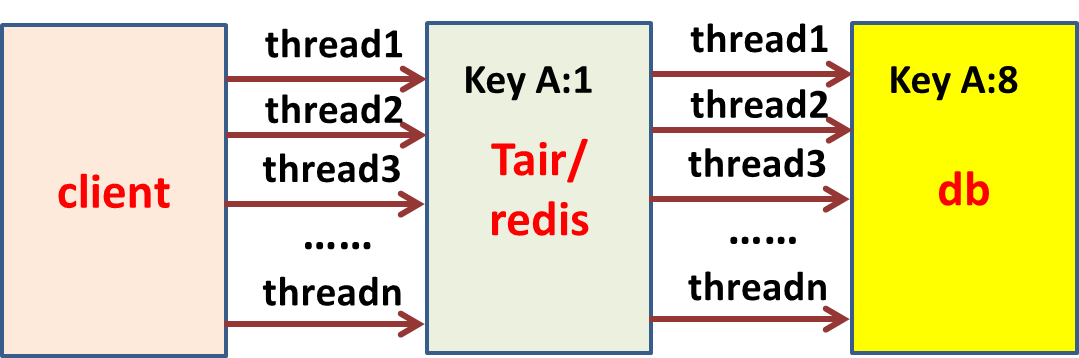
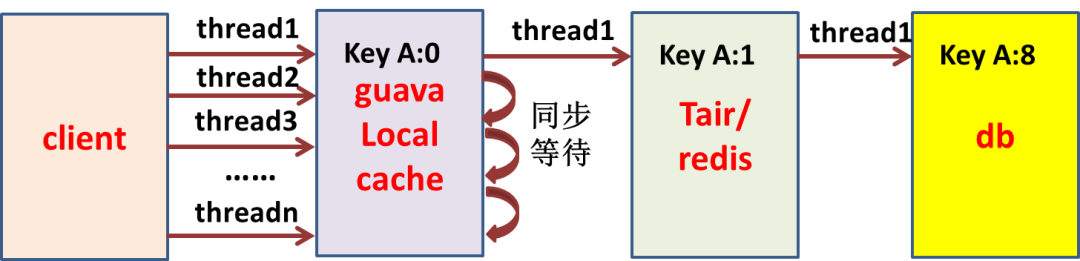
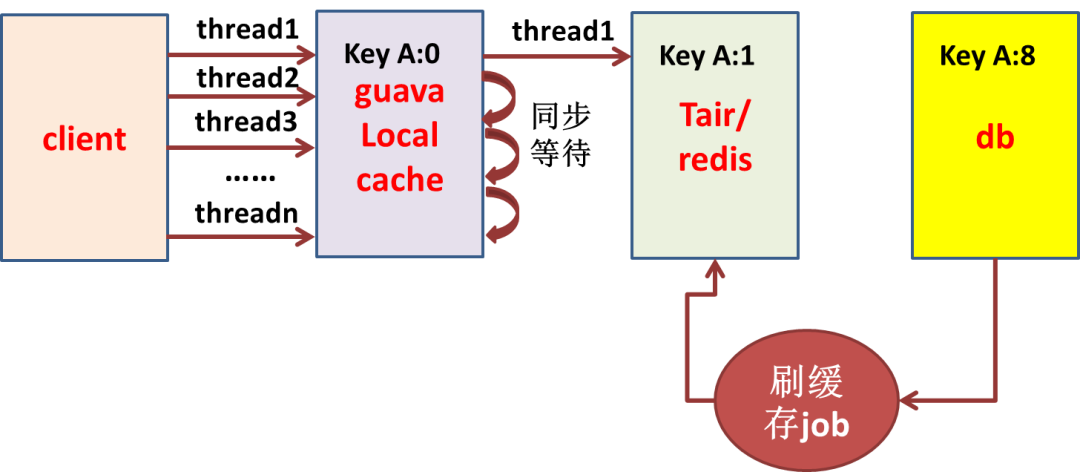
总结

推荐阅读

为什么CTO、技术总监、架构师都不写代码,还这么牛逼?

“因为你不懂技术…” 警察:???

拼多多终于被砍了一刀
一键三连「分享」、「点赞」和「在看」
技术干货与你天天见~
评论