
深度学习三大谜团:集成、知识蒸馏和自蒸馏

来源 | 智源社区
集成(Ensemble,又称模型平均)是一种「古老」而强大的方法。只需要对同一个训练数据集上,几个独立训练的神经网络的输出,简单地求平均,便可以获得比原有模型更高的性能。甚至只要这些模型初始化条件不同,即使拥有相同的架构,集成方法依然能够将性能显著提升。
但是,为什么只是简单的「集成」,便能提升性能呢?
目前已有的理论解释大多只能适用于以下几种情况:
(1)boosting:模型之间的组合系数是训练出来的,而不能简单地取平均;
(2)Bootstrap aggregation:每个模型的训练数据集都不相同;
(3)每个模型的类型和体系架构都不相同;
(4)随机特征或决策树的集合。
但正如上面提到,在(1)模型系数只是简单的求平均;(2)训练数据集完全相同;(3)每个模型架构完全相同 下,集成的方法都能够做到性能提升。

论文链接:https://arxiv.org/pdf/2012.09816.pdf
来自微软研究院机器学习与优化组的高级研究员朱泽园博士,以及卡内基梅隆大学机器学习系助理教授李远志针对这一现象,在最新发表的论文《在深度学习中理解集成,知识蒸馏和自蒸馏》(Towards Understanding Ensemble, Knowledge Distillation, and Self-Distillation in Deep Learning)中,提出了一个理论问题:

当我们简单地对几个独立训练的神经网络求平均值时,「集成」是如何改善深度学习的测试性能的?尤其是当所有神经网络具有相同的体系结构,使用相同的标准训练算法(即具有相同学习率和样本正则化的随机梯度下降),在相同数据集上进行训练时,即使所有单个模型都已经进行了100%训练准确性?随后,将集合的这种优越性能「蒸馏」到相同架构的单个神经网络,为何能够保持性能基本不变?
两位作者分别从理论和实验的角度给出了分析结果:
原因在于数据集中「多视图」(Multi-view)数据的存在。

朱泽园(Zeyuan Allen-Zhu)
朱泽园博士目前就职于微软总部 AI 研究院。南京外国语毕业,高一保送清华;2005、2006两年蝉联IOI金牌,2009年ACM总决赛亚军;清华毕业后在MIT读完硕博,后在普林斯顿进修博士后。

李远志(Yuanzhi Li)
另一位作者李远志,现任美国卡内基·梅隆大学(CMU)机器学习系助理教授,也是微软研究院的访问研究员。他于2010年到2014年在清华姚班进行本科学习,于2018年在普林斯顿大学获得博士学位,在斯坦福大学做了一年博士后之后,加入CMU担任助理教授。其研究方向主要为深度学习的基础理论与实践,凸优化算法与非凸优化算法设计,数据处理算法分析等。
1
深度学习的三大谜团
谜团 1:集成
观察结果显示,使用不同随机种子的学习网络𝐹1,…𝐹10(尽管具有非常相似的测试性能)相关联的函数非常不同。在这种情况下,使用“集成”的技术,仅需要获取这些经过独立训练的网络输出的未加权平均值,就可以在许多深度学习应用中极大地提高测试时间的性能。(参见图1)这意味着各个函数𝐹1,…𝐹10一定是不同的。但是,为什么集成可以大幅提升性能呢?
如果直接训练(𝐹1+⋯+𝐹10)/ 10,为什么性能提升就消失了?
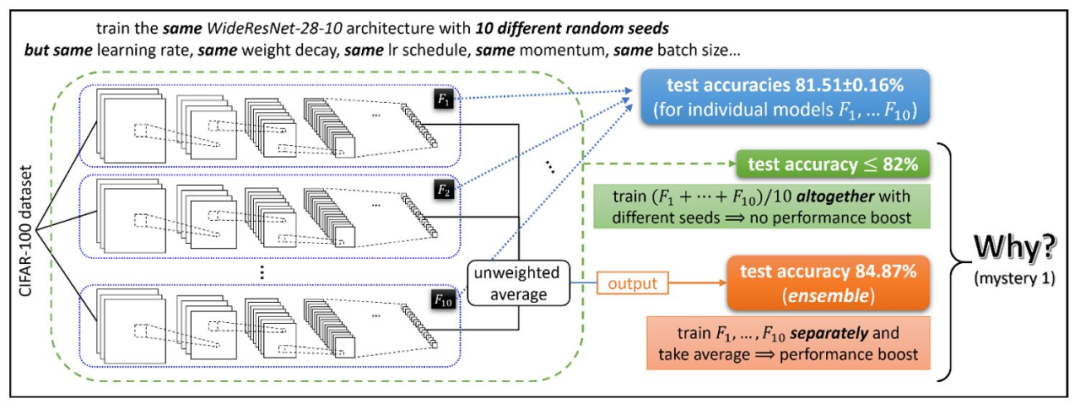
图1:集成(Ensemble)提升了深度学习应用中的测试准确性,但是这种准确性的提高则无法通过直接训练模型的平均值来实现。
谜团2:知识蒸馏
虽然集成可以极大地提升测试时间性能,但在推理时间(即测试时间)方面它变慢了10倍:我们需要计算10个神经网络的输出,而不是1个。当我们在低能耗的移动环境中部署此类模型时,这是一个严重的问题。
为了解决这个问题,研究者提出了一种叫做知识蒸馏的开创性技术。知识蒸馏指的是训练另一个单独的模型来匹配集成的输出。在这里,一张猫的图像上的集成(也称为隐藏知识)输出可能看起来像“ 80%猫+ 10%狗+ 10%汽车”,而真正的训练标签是“ 100%猫”。(请参见下面的图2)
事实证明,经过这样训练的单个模型可以在很大程度上匹配10倍以上集成模型的测试时间性能。但是,这导致了更多的问题。
与匹配真实标签相比,为什么匹配集成模型的输出可以为我们提供更好的测试准确性?此外,我们在知识蒸馏后对模型进行集成学习可以进一步提高测试准确性吗?
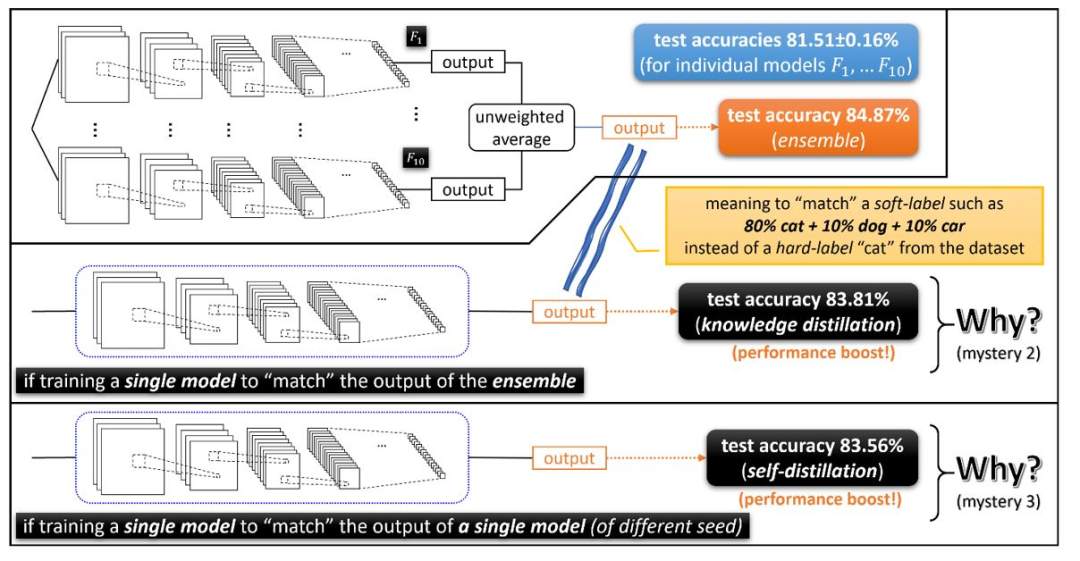
图2:知识蒸馏和自蒸馏也能够提升深度学习的性能。
谜团3: 自蒸馏
注意,知识蒸馏至少在直观上是有意义的:teacher model有84.8% 的测试准确率,那么student model 可以达到83.8% 。
但接下来这个现象就让人难以理解了,使用自蒸馏技术,也即老师的学生就是它自己:通过对具有相同架构的单个模型进行知识蒸馏,竟然可以提高测试准确率。
想象一下: 训练出一个测试准确率为81.5% 的单个模型,结果使用相同结构的模型进行自蒸馏一下,测试准确率竟然提高到了83.5%,这不是很奇怪么?
2
神经网络集成与特征映射集成
大多数现有的集成理论只适用于单个模型之间存在根本性差异的情况(例如,决策树支持不同变量的子集),或者在不同的数据集上训练的情况(例如自举)。
但这些理论显然不能解释前面提到的现象。上面提到,集成的模型,其训练的框架是相同的,训练的数据也是相同的 —— 唯一的区别只是训练期间的随机性。
或许,与深度学习中的集成最为相近的理论,应该是「随机特征映射集成」(ensemble in random feature mappings)。这表现在两个方面:一方面,将多个随机特征的线性模型进行组合,可以提升测试时的性能,这很显然,因为它增加了特征的数量;另一方面,在特定的参数区域中,神经网络的权值可以非常接近它们的初始化(称为神经正切核区域,或 NTK区域) ,结果网络只在规定的特征映射上学习一个线性函数,这些特征映射完全由随机初始化决定。
将这两者结合起来,可以推测深度学习集成与随机特征映射集成,在原理上是一致的。
这就引出了另外一个问题:
集成和知识蒸馏在深度学习上,与在随机特征映射(即NTK特征映射)上,是否会有相同的表现呢?
答案是否定的。
如下图3所示,该图比较了在深度学习/随机特征映射中的集成和知识蒸馏的性能。

图3: 集成在随机特征映射上有效(但是出于与深度学习完全不同的原因) ,而知识蒸馏在随机特征映射中不起作用。
可以看出,通过集成的方式,无论是在深度学习中,还是在随机特征映射中,都能够得到较好的性能;而在随机特征映射中,知识蒸馏的性能显然要比单个模型的性能还要差。
这就很明显地说明:集成和蒸馏,原理上并不相同。
具体来说:
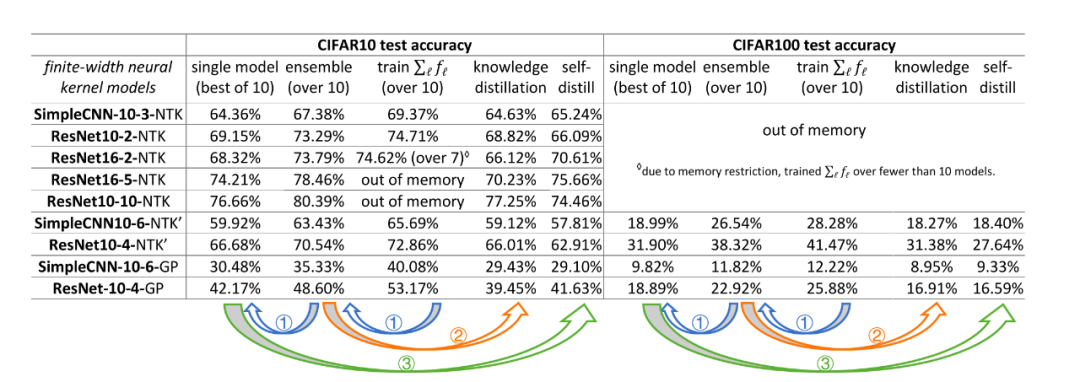
与在深度学习情况不同,在随机特征映射中,集成的优越性能不能蒸馏到单个模型上。
在图3中,神经正切核(NTK)模型的集成,在 CIFAR-10数据集上达到了70.54% 的准确率,但经过知识蒸馏后,它下降到了66.01% ,甚至比单个模型的66.68% 的测试准确率还要低。
在深度学习中,直接训练模型的平均值(𝐹1+⋯+𝐹10)/10 与训练单个模型 𝐹𝑖 相比没有任何优势;而在随机特征映射中,训练平均值的效果优于单个模型及其集成。
在图3中,NTK 模型的集成的准确率为 70.54% ,而直接训练10个模型的平均值准确率为72.86%。
为什么会这样呢?
主要原因在于,神经网络是使用分层特征学习,尽管每个模型𝐹𝑖有不同的初始化,但在每一层它们都拥有相同的特征集合。因此,与单个模型相比,多个模型的平均模型,并没有增加其特征集合的大小。
在随机特征映射中,每个 𝐹𝑖 都使用了一组完全不同的规定特征。因此,无论是使用集成的方式,还是直接求平均的方式,都能够带来一些性能优势,但由于特征的稀缺性,在蒸馏后,性能必然会有一定下降。
3
集成与减少单个模型的方差
除了随机特征的集成外,还有人推测认为,由于神经网络的高度复杂性,每个单独的模型 𝐹𝑖 可能学习到一个函数 𝐹𝑖 (𝑥)=𝑦+ξ𝑖,ξ𝑖 是某种噪声,这种噪声取决于训练过程中使用的随机性。
经典的统计学认为,如果所有的ξ𝑖是大致独立的,那么求取他们的平均值能够大大减少噪音量。
因此,
“集成能够减少方差”真的是集成能提高提高性能的原因吗?
证据表明,在深度学习的背景下,这种减少方差来提升性能的假设是值得怀疑的:
1. 集成并不能无限制地提高测试的准确性。
集成超过100个单个模型通常,与集成10个单个模型基本没有差别。因此,100 ξ𝑖 的平均值与10 ξ𝑖 的平均值相比,方差不再减小,表明 ξ𝑖 可能是不独立的,而且有可能存在偏差,因此均值不为零。在ξ𝑖 不独立的情况下,很难讨论求得这些 ξ𝑖 的平均值能够减少多少偏差。
2. 即使理想情况下,我们认为ξ𝑖 是相互独立的,那么这就表明ξ𝑖 是有偏或异号的。
于是我们可以将 𝐹𝑖 写成:
𝐹𝑖(x)=𝑦+ξ+ξ𝑖
ξ 是一个固定误差,ξ𝑖 则指每个模型的独立误差。于是在集成之后,期望的网络输出将接近 y + ξ,这会有一个固定的偏差 ξ。
在这种情况下,为什么知识蒸馏会有效呢?那么,为什么这个带有偏差 ξ (也被称为隐藏知识)的输出会优于原来的训练呢?
3. 集成学习并不总是能够提高准确性
在图4中,我们可以看到神经网络的集成学习并不总是能够提高测试的准确性,至少在输入类似高斯分布的情况下是这样。
换句话说,在这些网络中,求平均值不会带来任何准确性的增益。
综上来看,我们需要更深入地理解深度学习中的集成,而不只是认为“集成能够减少方差”这么简单。

图4:当输入类似高斯分布时,实验表明集成并不能提高测试的准确性。
4
多视图数据:深度学习中集成的一种新方法
图4 表明,在非结构化随机输入的情况下,集成并不凑效。
在我们最新的工作中,我们从数据中找到了集成之所以能够在深度学习中有效的原因所在。
通常,在一个数据集中(以视觉数据集为例),一个对象通常会有多个视角(muti-view)的数据。以「car」为例,一个汽车的数据集中,通常会有从各个角度拍摄的车辆的照片,通常我们仅需要通过车头灯、车轮或车窗等其中的一个特征,便可以对汽车进行分类了;即使在图片中有些特征因为拍摄角度的原因而缺失了,也没有太大的关系。例如从正前方拍摄的汽车,图像中便没有车轮,但这并不妨碍我们识别出「car」。
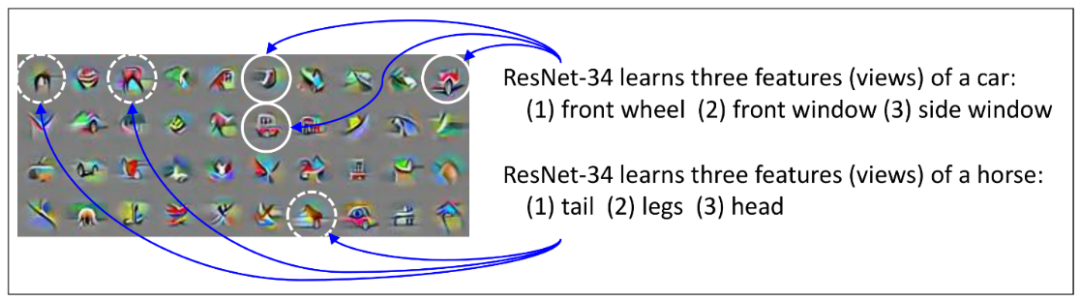
图5:在CIFAR-10数据集上进行训练的 ResNet-34第23层的一些通道的可视化。
这种现象在多数数据中都会存在,其中每类数据都具有多个视角的特征,这种结构被称为“多视图”(multi-view)。
在大多数数据中,几乎所有的视图特征都会显示出来;但在某些数据中,却可能缺少一些视图特征。
更广泛地说,这种“多视图”结构事实上,不仅在原始数据中存在,在中间层抽取的特征集合中也会存在。
在这种“多视图”结构下进行训练,网络会:
1)根据学习过程中的随机性,快速学习这些视图特征的一个子集;
2)会使用这些视图特征,记下剩余那些少量不能正确分类的数据。
第一点意味着,如果将不同网络进行集成,将能够把学习到的视图特征聚合起来,从而达到更高的测试精度。
第二点意味着,单个模型不能学习所有的视图特性,不是因为它们没有足够的容量,而是因为没有足够的训练数据;大多数数据已经被现有的视图特征正确分类,因此在训练阶段,它们基本上不提供梯度。
5
知识蒸馏: 强制单个模型学习多个视图
基于上述视角,我们可以再来分析知识蒸馏是如何工作的。
在现实生活的场景中,一些汽车图像可能看起来“更像一只猫”:例如,一些汽车图像的前灯可能看起来像猫眼。当这种情况发生时,集成模型可以提供有意义的隐藏知识,例如“汽车图像 X 有10% 像一只猫。”
这里是个关键点。在训练单个神经网络模型时,如果没有学习“前灯”视图,剩下的视图或许仍然有可能根据别的视图将图像 x 标记为汽车,但它却无法匹配隐藏知识“图像 X 有10% 像猫”。
而在知识蒸馏的过程中,蒸馏模型会学习每一个可能的视图特征,来匹配集成的性能。需要注意的是,深度学习中知识蒸馏的关键是,作为一个神经网络,单个模型在特征学习中能够学习到集成的所有特征。这与实验中观察到的情况是一致的。(见图6)
 图6:知识蒸馏已经从集成中学习了大部分视图特性,因此在知识蒸馏之后对模型进行集成学习不会带来更多的性能提升。
图6:知识蒸馏已经从集成中学习了大部分视图特性,因此在知识蒸馏之后对模型进行集成学习不会带来更多的性能提升。
6
自蒸馏: 集成与知识蒸馏的隐性结合
这个解释也可以用到知识自蒸馏中——训练一个模型来匹配另一个相同的架构的模型(但使用不同的随机种子)的输出,在某种程度上也能提高性能。
简单来理解,自蒸馏是知识蒸馏的一种特殊情况。
我们假设使用模型𝐹2 从一个随机的初始化开始,来匹配另外一个模型𝐹1 的输出。在这个过程中𝐹2 一方面会学习𝐹1 已经学习到特征子集,另一方面其能够学习到的特征子集也会受其随机初始化的影响。
这个过程,可以看做是:首先对两个单独的模型 𝐹1,𝐹2进行集成学习,然后蒸馏成 𝐹2。
最终的 𝐹2 可能不一定涵盖数据集中所有可学习的视图,但它至少有学习所有视图(通过两个单个模型的集成学习数据库来覆盖)的潜力。这就是自蒸馏模型测试时性能提升的来源!
参考:
https://www.microsoft.com/en-us/research/blog/three-mysteries-in-deep-learning-ensemble-knowledge-distillation-and-self-distillation/

