
深度学习中的3个秘密:集成,知识蒸馏和自蒸馏
本文转载自:AI公园
作者:Zeyuan Allen-Zhu | 编译:ronghuaiyang
训练好的模型,用自己蒸馏一下,就能提高性能,是不是很神奇,这里面的原理到底是什么呢,这要从模型集成开始说起。
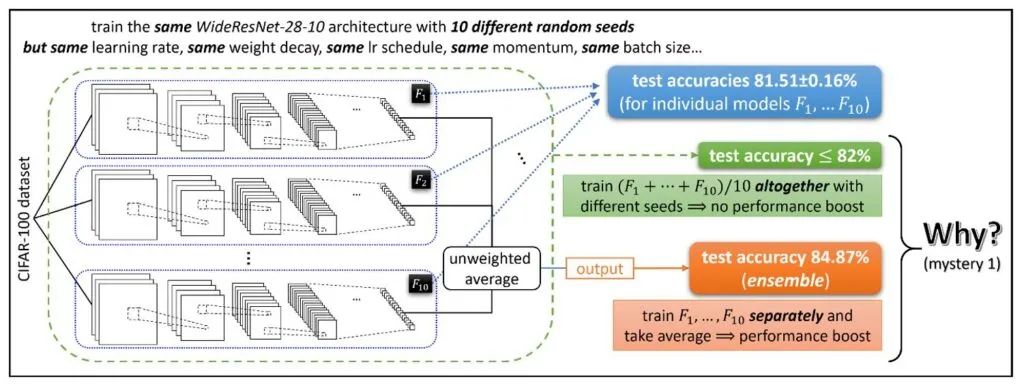
在现在的标准技术下,例如过参数化、batch-normalization和添加残差连接,“现代”神经网络训练 —— 至少对于图像分类任务和许多其他任务来说 —— 通常是相当稳定的。使用标准的神经网络结构和训练算法(通常是带动量的SGD),学习模型的表现一贯良好,不仅在训练精度方面,甚至在测试精度方面,无论在训练过程中使用的是哪种随机初始化或随机数据顺序。例如,用不同的随机种子在CIFAR-100数据集上训练相同的WideResNet-28-10架构10次,平均测试精度为81.51%,而标准偏差仅为0.16%。
在一篇新论文“Towards Understanding Ensemble, Knowledge Distillation, and Self-Distillation in Deep Learning“中,我们专注于研究神经网络在训练过程中纯粹由于随机化产生的差异。我们提出了以下问题:除了测试准确性上的微小偏差外,从不同随机初始化中训练出来的神经网络是否学习了非常不同的函数?如果是这样,差异从何而来?我们如何减少这种差异,使神经网络更稳定,甚至更好?这些问题并非微不足道,它们与深度学习中广泛使用的三种技术有关。
深度学习中的三个神秘之处
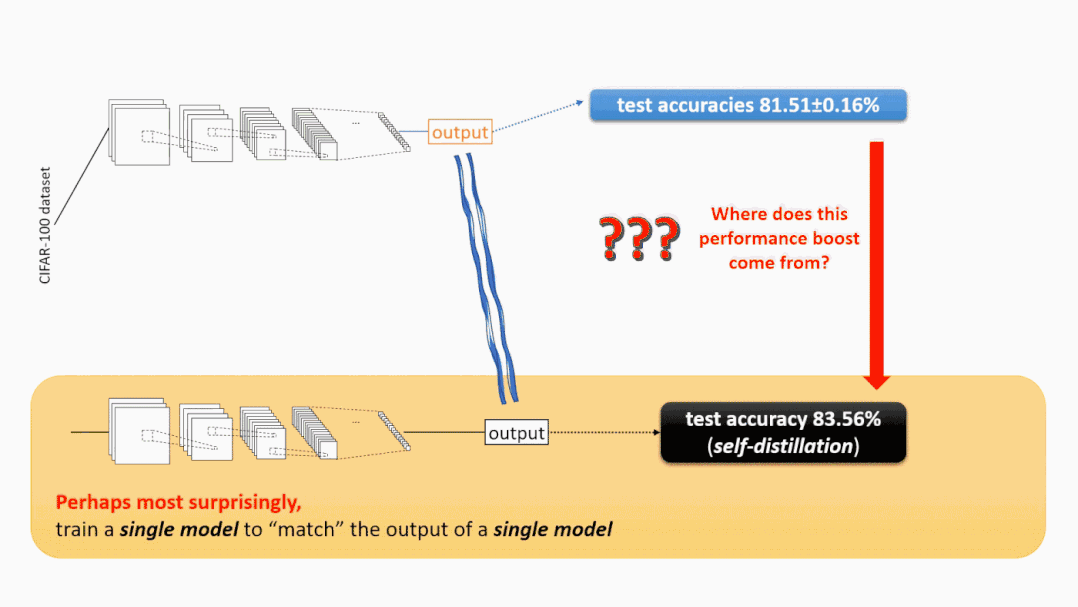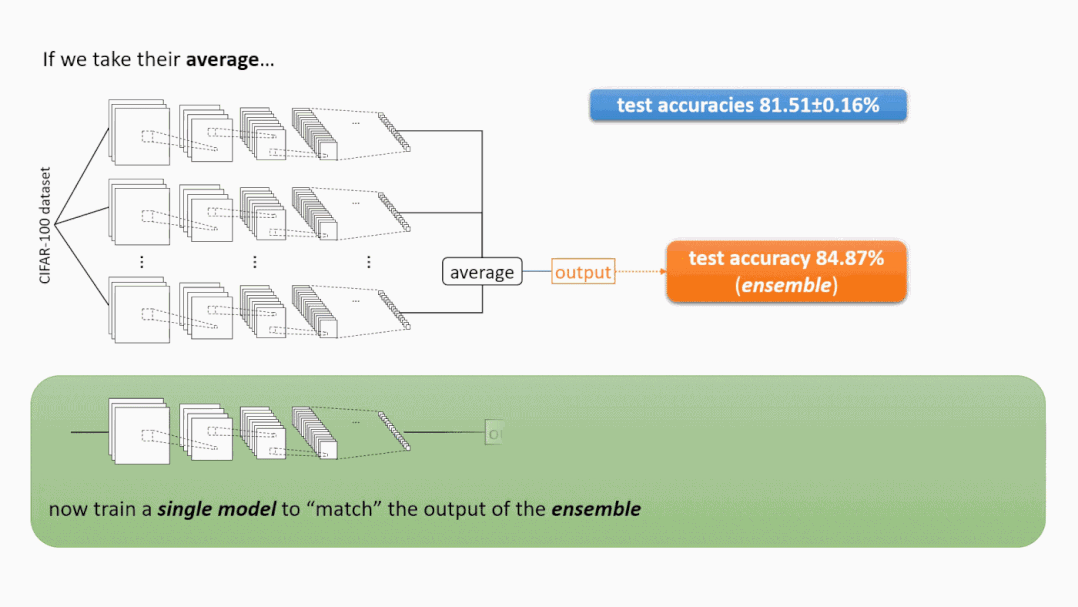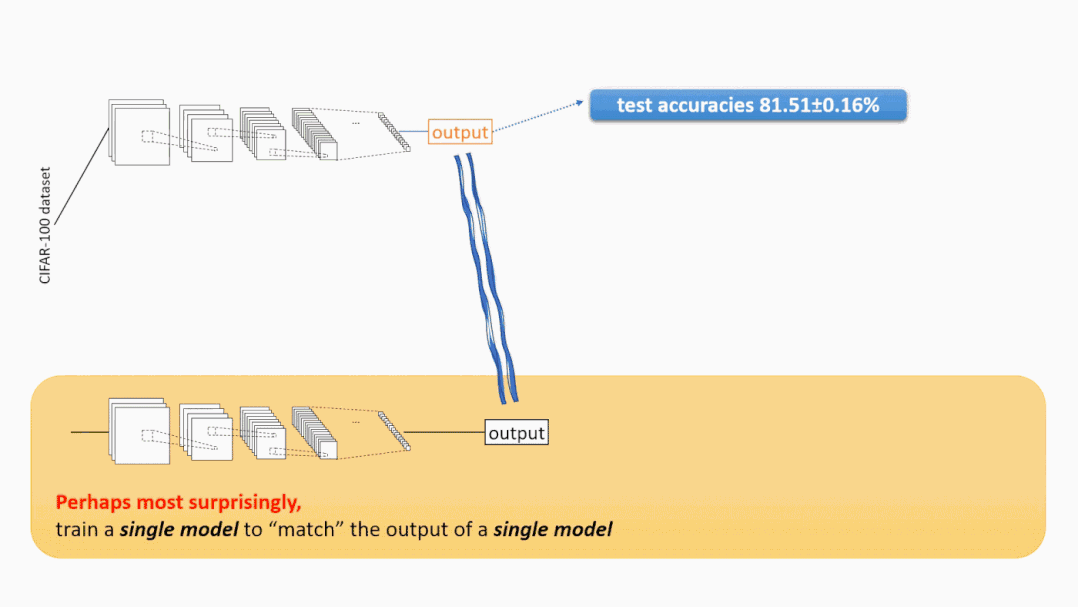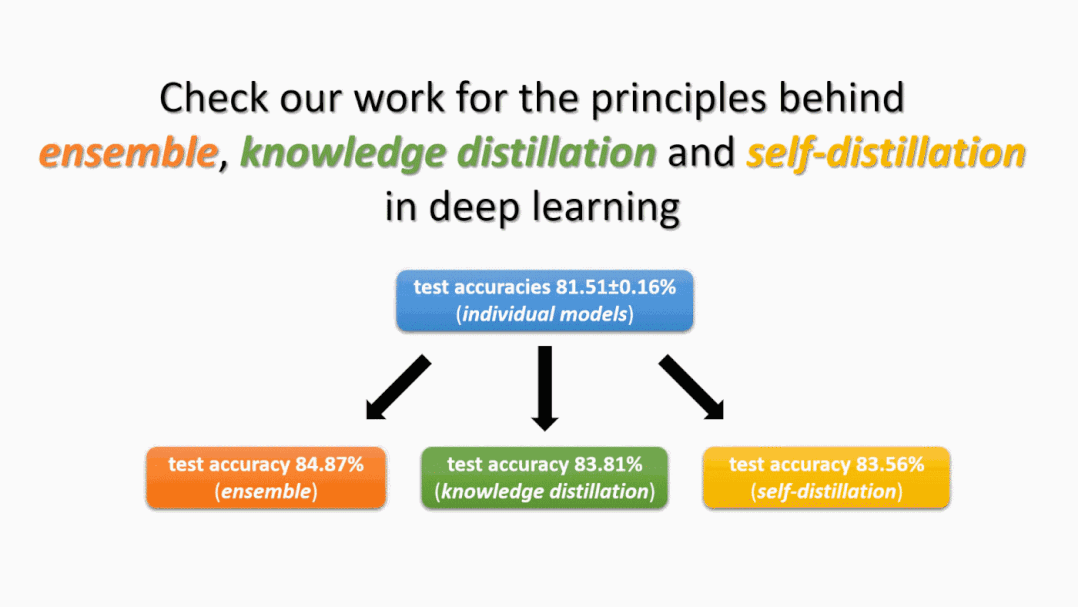
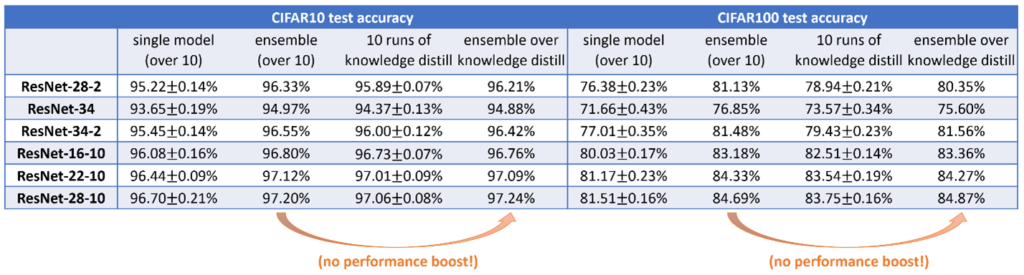
神秘之处1:集成 使用不同随机种子的学习网络F1,…F10 —— 尽管具有非常相似的测试性能 —— 被观察到与非常不同的函数相关联。实际上,使用一种著名的技术叫做集成(ensemble),只需对这些独立训练的网络的输出进行无加权的平均,就可以在许多深度学习应用中获得测试时性能的巨大提升。(参见下面的图1。)这意味着单个函数F1,…F10必须是不同的。然而,为什么集成的效果会突然提高呢?另外,如果一个人直接训练(F1+⋯+F10)/10,为什么性能提升会消失?
神秘之处2:知识蒸馏 尽管集成在提高测试时性能方面非常出色,但在推理时间(即测试时间)上,它的速度会慢10倍:我们需要计算10个神经网络的输出,而不是一个。当我们在低能耗、移动环境中部署这样的模型时,这是一个问题。为了解决这个问题,提出了一种叫做知识蒸馏的开创性技术。也就是说,知识蒸馏只需要训练另一个单独的模型就可以匹配集成的输出。在这里,对猫图像的集成输出(也称为“dark knowledge”)可能是类似“80% cat + 10% dog + 10% car”,而真正的训练标签是“100% cat”。(参见下面的图2。)
事实证明,经过训练的单个模型,在很大程度上,可以匹配10倍大的集成测试时的表现。然而,这导致了更多的问题。为什么与真实的标签相比,匹配集成的输出能给我们更好的测试精度?此外,我们是否可以对知识蒸馏后的模型进行集成学习以进一步提高测试精度?
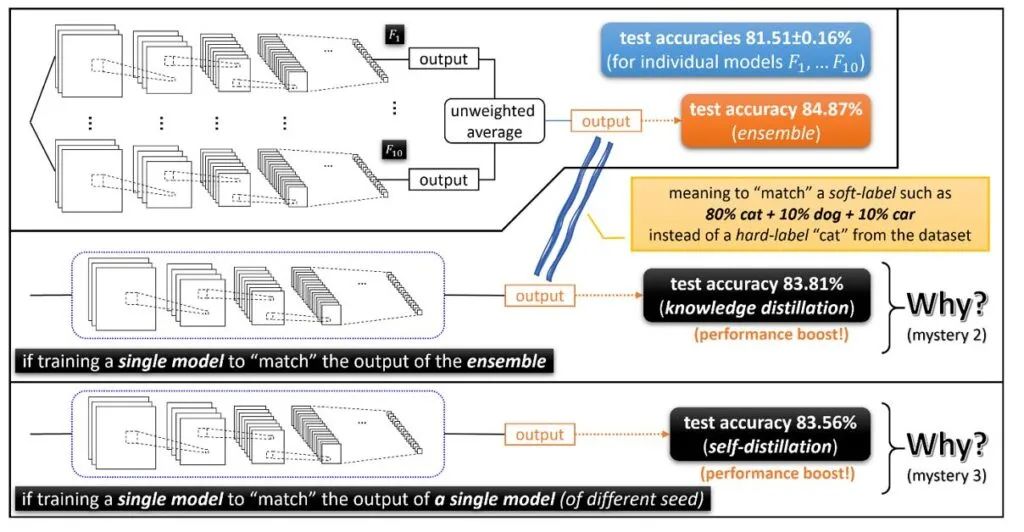
神秘之处3:自蒸馏 注意,知识蒸馏至少直观上是有意义的:教师集成模型的测试准确率为84.8%,所以单个学生模型的测试准确率可以达到83.8%。下面的现象,被称为自蒸馏(或“Be Your Own Teacher”),是完全令人惊讶的 ——通过对同一架构的单个模型执行知识蒸馏,测试的准确性也可以得到提高。(请参见上面的图2。) 考虑一下这个问题:如果训练一个单独的模型只能得到81.5%的测试准确率,那么为什么“再次训练同一个模型把自己当作老师”突然可以把测试准确率提高到83.5%呢?
神经网络集成 vs 特征图集成
大多数现有的集成理论只适用于个体模型本质上不同的情况(例如,使用不同变量子集的决策树)或在不同的数据集上训练(如bootstrapping)。在深度学习世界中,单独训练的神经网络具有相同的架构,使用相同的训练数据 —— 它们唯一的区别在于训练过程中的随机性。
也许现有的深度学习中最接近去匹配集成定理的是随机特征映射的集成。一方面,将多个随机(特定的)特征的线性模型结合在一起可以提高测试时的性能,因为它增加了特征的数量。另一方面,在某些参数上,神经网络权重可以保持非常接近他们的初始化(称为neural tangent kernel、NTK,regime),以及由此产生的网络仅仅是学习一个由完全随机初始化决定的特定的特征映射的线性函数。当将两者结合起来时,我们可以推测深度学习中的集成与随机特征映射中的集成原理相同。这就引出了下面的问题:
与随机特征映射(即NTK特征映射)相比,集成/知识蒸馏在深度学习中的工作方式是否相同?
**回答:并非如此,下面图3的实验证明了这一点。**此图比较了深度学习中的集成和知识蒸馏与随机特征映射的线性模型的集成和知识蒸馏。集成在两种情况下都有效。然而,图3中的准确性清楚地表明,它们的工作原因完全不同。具体地说:
与深度学习的情况不同,随机特征设置下集成的优越性能不能被蒸馏为单个模型。例如,在图3中,neural tangent kernel(NTK)模型在CIFAR-10数据集上的集成精度达到了70.54%,但经过知识精馏后,集成精度下降到66.01%,甚至低于个体模型的测试精度66.68%。 在深度学习中,直接训练模型的平均值(F1+⋯+F10)/10与训练单个模型Fi相比没有任何好处,而在随机特征设置中,训练平均值的效果优于单个模型和它们的集成。例如,在图3中,NTK模型的集成达到了70.54%的精度,但这甚至比直接训练10个模型的平均的精度72.86%还要差。
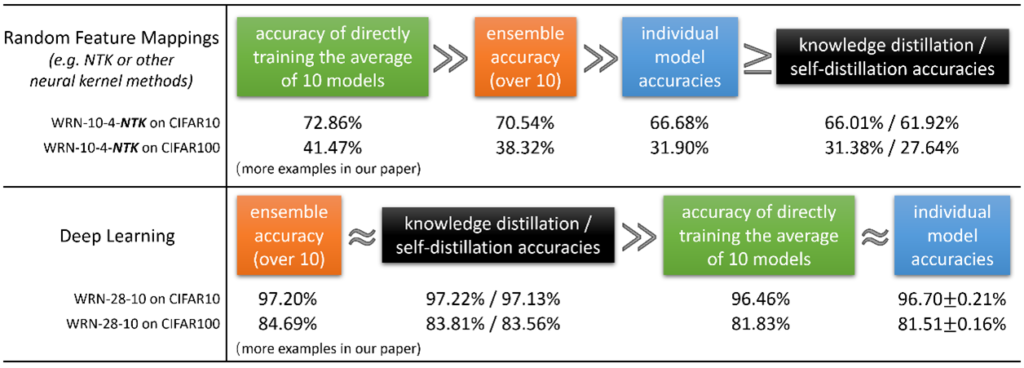
神经网络的原因是执行(层次特性学习) —— 单个Fi模型,尽管使用不同的随机初始化,仍有能力学习相同的特性集。因此,与单个网络相比,它们的平均几乎无法提供额外的能力。然而,在线性设置中,每个Fi使用一组不同的特定的特征。因此,尽管结合这些特征(使用集合或直接训练平均值)确实有优势,但由于特征的稀缺性,它们不能被提炼成单个模型。
集成 vs 减少单个模型的误差
除了随机特征的集合外,人们还可以推测,由于神经网络的高度复杂性,每个单独的模型Fi可能学习一个函数Fi (x)=y+ξi,其中ξi是一些依赖于训练过程中使用的随机性的噪声。经典统计表明,如果所有的ξi都是大致独立的,那么对它们平均可以大大减少噪声。因此,
“集成减少误差”是集成可以让性能提升的原因吗?
答案:我们的证据表明,这种减少误差的假设在深度学习的背景下是非常值得怀疑的:
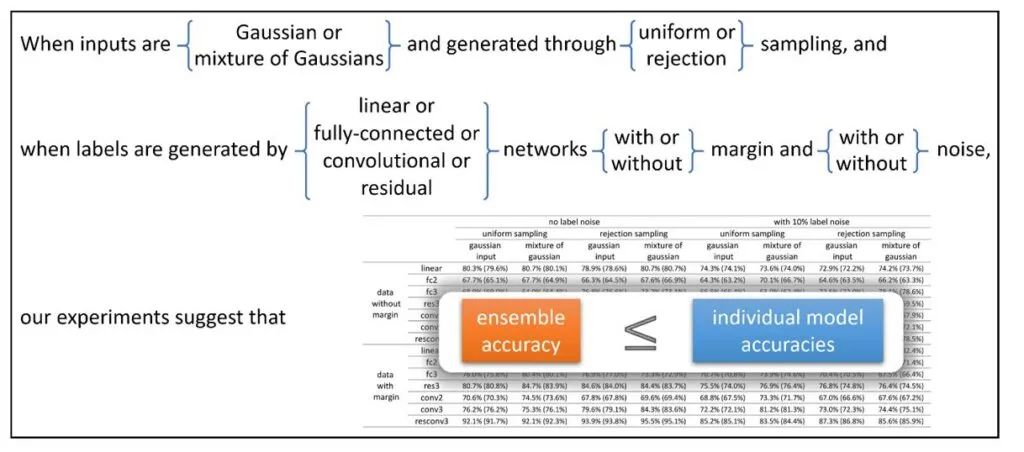
集成不会永远提高测试精度:当集成超过100个单独的模型时,与集成超过10个单独的模型相比,通常没有区别。因此,100ξi的均值与10ξi的相比不再减少方差 —— 这表明ξi的(1)可能不是独立的,(2)可能是有偏的,因此其均值不为零。在(1)的情况下,很难讨论通过对这些算子的平均可以减少多少误差。 即使人们希望接受理想主义的信念即(1)不会发生,所有的ξi都是有偏的,用符号表示的话,Fi(x)=y+ξ+ξi‘,其中ξ是一般性偏差,ξi '是独立偏差。那么为什么知识蒸馏能工作呢?在集成之后,我们期望输出可以接近y+ξ ,也就是具有一般性的偏差ξ。那么,为什么使用具有误差ξ的输出(也称为 dark knowledge)比原来训练的真实标记更好呢? 在图4中,我们看到神经网络的集成学习并不总是提高测试精度——至少在输入是类似高斯的情况下是这样。换句话说,在这些网络中,“平均这些数据”并不会导致任何精度的提高。因此,我们需要更仔细地理解深度学习中的集成,而不是像“减少误差”这样的一般性说法。
多视图数据:新方法去证明深度学习中的集成
由于集成不太可能在非结构化的随机输入下工作(见图4),我们必须查看数据中的特殊结构以正确理解它。
在我们的新工作中,我们建议研究一种可以在许多深度学习擅长的数据集中找到的共同结构。特别是在视觉数据集中,对象通常可以使用多个视图进行分类。例如,一辆汽车的图像可以根据前灯、车轮或窗户分类为一辆汽车。对于汽车在图像中的典型视图,我们可以观察到所有这些特征,使用其中一个特征将其分类为汽车就足够了。然而,也有一些从特定角度拍摄的汽车图像,其中一个或多个特征是缺失的。例如,一辆汽车正面朝前的图像可能没有车轮的特征。我们在图5中给出了实际的例子。
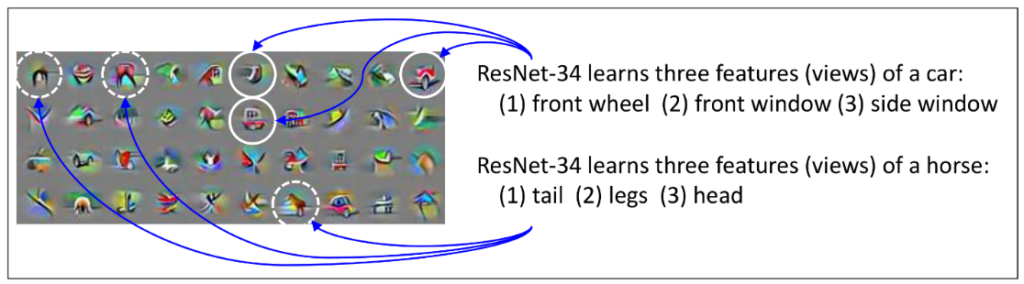
我们将这种结构称为“多视图”,其中每个数据类都有多个视图特征。在大多数数据中,几乎所有的视角特征都会显示出来,但在一些数据中,一些视图特征可能会丢失。(更广义地说,“多视图”结构不仅表现在输入像素空间中,也表现在中间层中)
我们发展出一个定理,表明在多视图数据下的神经网络训练过程中,网络会:
根据学习过程中使用的随机性,快速学习这些视图特征的子集。 记住少数剩余的不能使用这些视图特性正确分类的数据。
第一点意味着,不同网络的集成将收集所有这些可学习的视图特征,从而实现更高的测试精度。第二点意味着单个模型不能学习所有的视图特性,不是因为它们没有足够的容量,而是因为没有足够多的训练数据来学习这些视图。大多数数据已经用现有的视图特征进行了正确的分类,所以在这个训练阶段它们基本上不提供梯度。
知识蒸馏:让单个模型去学习多个视图
在这项新工作中,我们继续展示知识蒸馏的工作原理。在现实生活中,一些汽车图像可能比其他图像看起来“更像猫”:例如,一些汽车图像的前灯看起来像猫的眼睛。当这种情况发生时,集成模型可以提供有意义的dark knowledge:例如,“汽车图像X有10%像一只猫。”
现在来看看关键的观察结果。当训练一个单独的神经网络模型时,如果“前照灯”视图没有被学习,那么即使剩余的视图仍然可以正确地将图像X标记为一辆车,它们也不能用来匹配“dark knowledge”图像X是10%像一只猫。换句话说,在知识蒸馏过程中,个体模型被迫学习每一个可能的视图特征,以匹配集成的性能。请注意,深度学习中知识提炼的关键是,作为神经网络的单个模型正在进行特征学习,因此能够学习集成的所有特征。这与我们在实践中观察到的情况是一致的。(参见图6)。
自蒸馏:隐式地结合集成和知识蒸馏
在这项新工作中,我们还为知识自蒸馏提供了理论支持(参见图3)。训练一个单个模型以匹配另一个相同单个模型的输出(但使用不同的随机种子),以某种方式提高了性能。
在较高的层次上,我们把自蒸馏看作是集成蒸馏和知识蒸馏更紧密的结合。当从随机初始化学习单个模型F2以匹配单独训练的单个模型F1的输出时,可以期望F2根据它自己的随机初始化学习特征的子集。除此之外,F2也有动机去学习F1已经学习过的特征子集。换句话说,人们可以把这个过程看作是“集成学习两个单独的模型F1和F2,并将其蒸馏为F2。最终的学习模型F2可能不一定涵盖数据集中所有的可学习视图,但它至少有潜力学习所有可以通过集成学习覆盖两个单独模型的视图。这就是测试时性能提升的来源。
总结
在这项工作中,我们尽我们所知,展示了第一个理论证明,有助于理解集成在深度学习中的工作原理。我们也提供了实证证据来支持我们的理论和我们的“多视角”数据假设。我们认为,我们的框架可以适用于其他情况。例如,使用随机裁剪的数据增强可以被视为增强网络学习“多视图”的另一种方式。我们希望,在实践中,我们关于神经网络如何在训练过程中提取特征的新理论观点,也可以帮助设计新的原则和方法,以提高神经网络的测试精度,并有可能与模型集成的测试精度相匹配。
英文原文:https://www.microsoft.com/en-us/research/blog/three-mysteries-in-deep-learning-ensemble-knowledge-distillation-and-self-distillation/
 End
End
声明:部分内容来源于网络,仅供读者学术交流之目的,文章版权归原作者所有。如有不妥,请联系删除。