
深度学习中的知识蒸馏技术(下)
本文概览:
写在前面:
这是一篇介绍知识蒸馏在推荐系统中应用的文章,关于知识蒸馏理论基础的详细介绍,请看我的这篇文章:
1. 背景介绍
1.1 简述推荐系统架构
如果从传统角度来看实际的工业推荐系统,粗略地可以分为两个阶段。首先是召回阶段,主要根据用户部分特征,从海量的物品库里,快速找回一小部分用户潜在感兴趣的物品,然后交给排序环节。其次是排序阶段,排序阶段可以融入较多特征,使用复杂模型,来精准地做个性化推荐。召回强调快且相关性,即快速地召回一批与用户兴趣点相关的物品;排序强调准且符合推荐系统的终极目标,即根据推荐系统的终极目标(DAU、时长、留存等)利用大规模特征做精准的个性化排序。最近一两年,推荐系统的终极目标也在逐步下沉到召回和粗排阶段,比如在召回和粗排阶段设计的多目标与精排多目标对齐。

但是,如果我们更细致地看实用的工业级推荐系统,一般会有四个环节,如下图所示:
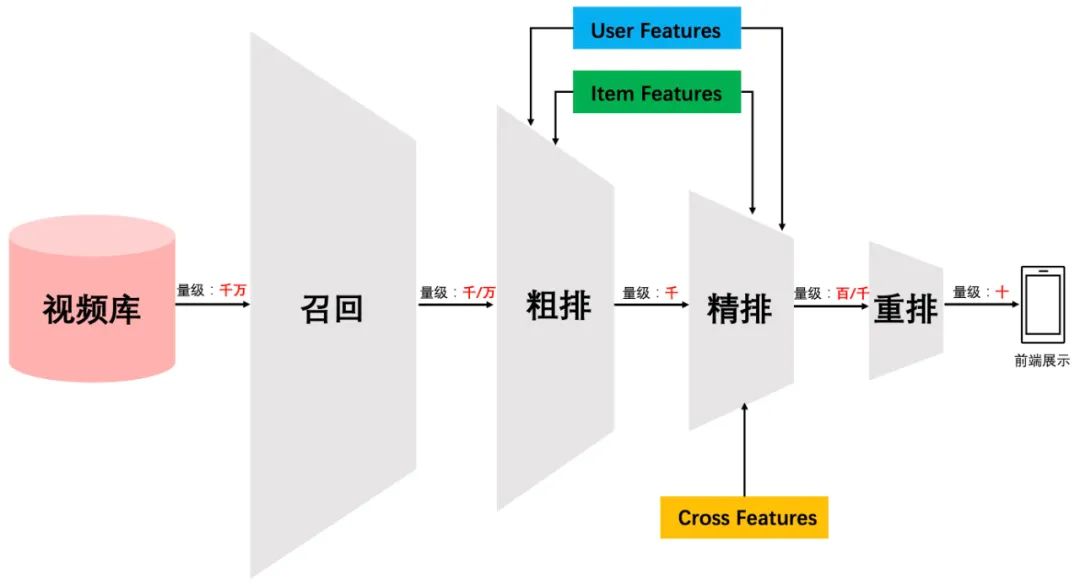
四个环节分别是:召回、粗排、精排和重排。召回目的如上所述。有时候因为每个用户召回环节都有多路召回算法,这会产生两个问题:
这些召回算法每路召回多少物品难以确定,因此需要加一层粗排对每路召回的结果进行统一的打分排序,把Top K 的结果送入精排中; 总体召回环节返回的物品数量太多,排序环节需要占用大量的机器资源且影响排序速度,所以可以在召回和精排之间加入一个粗排环节;
粗排一般通过少量用户和物品特征,利用简单模型,来对召回的结果进行粗略的排序,在保证一定精准的前提下,进一步减少往后传送的物品数量。粗排往往是可选择的,可用可不用,跟场景有关。之后,是精排环节,使用你能想到的任何特征,可以上你能承受速度极限的复杂模型,尽量精准地对物品进行个性化排序。排序完成后,传给重排环节,传统地看,这里往往会上各种技术及业务策略,比如曝光去重、打散、多样性保证、固定类型物品插入等等,主要是技术产品策略主导或者为了改进用户体验。
1.2 为什么要把知识蒸馏引入推荐系统中?
随着深度学习的快速发展,优秀的模型层出不穷,比如图像领域的ResNet、自然语言处理领域的Bert,这些革命性的新技术使得模型精度快速提升。但是,先进的深度学习模型正在变得越来越复杂,网络深度越来越深,模型参数量也在变得越来越多。而这会带来一个现实应用的问题:将这些复杂模型推上线,模型响应速度太慢,当流量大的时候撑不住。因此知识蒸馏就是目前一种比较流行的解决此类问题的技术方向。
一般知识蒸馏采取Teacher-Student模式:将复杂模型作为Teacher,Student模型结构较为简单,用Teacher来辅助Student模型的训练,Teacher学习能力强,可以将它学到的知识迁移给学习能力相对弱的Student模型,以此来增强Student模型的泛化能力。复杂笨重但是效果好的Teacher模型不上线,就单纯是个导师角色,真正上线撑流量的是灵活轻巧的Student小模型。
结合知识蒸馏与推荐系统的特点,将知识蒸馏与推荐系统结合会有哪些优势呢?
在推荐系统的各个阶段都高度要求模型性能。受限于网络延时和性能的要求,可以用复杂模型(如带有高阶特征交叉的模型,xDeepFM等)蒸馏的知识指导简单一些的模型进行学习。 相对于精排模型而言,粗排和召回模型本身就很简单。粗排或召回阶段,在优化ground-truth目标时,是否可以用精排(Teacher网络)输出的知识指导粗排或者召回模型的训练呢?
2. 知识蒸馏与推荐系统
在含有召回、粗排、精排的串行级联推荐体系中,知识蒸馏可以应用在哪个环节呢?假设我们在召回环节采用模型排序(YouTube DNN/DSSM双塔等模型),那么知识蒸馏在这三个环节都可以采用,进而优化现有推荐系统的线上服务响应时间及推荐质量。
2.1 精排环节采用知识蒸馏
为何在精排环节采用知识蒸馏?我们知道,精排环节注重精准排序,所以采用尽量多的特征和复杂模型,以期待获得优质的个性化推荐结果。但是,这同时也意味着复杂模型的在线服务响应变慢。若承载相同的流量,需要增加在线服务并行程度,也就意味着增加机器资源和成本。因此,如何在精准排序和机器资源之间做均衡呢?我们可以通过在精排环节采用知识蒸馏技术实现一个既有较好的推荐质量,又能有快速推理能力的模型。
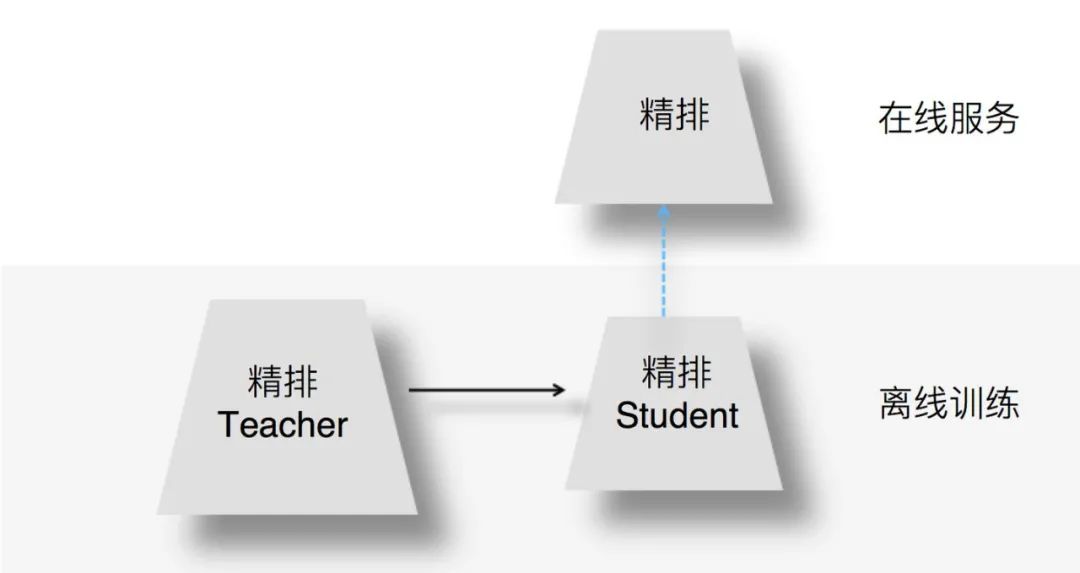
图:来源于参考文献2
上图展示了如何在精排环节应用知识蒸馏:我们在离线训练的时候,可以训练一个复杂精排模型作为Teacher,一个结构较简单的DNN排序模型作为Student。因为Student结构简单,所以模型表达能力弱,于是,我们可以在Student训练的时候,除了采用常规的Ground Truth训练数据外,Teacher也辅助Student的训练,将Teacher复杂模型学到的一些知识迁移给Student,增强其模型表达能力,以此加强其推荐效果。在模型上线服务的时候,并不用那个复杂的Teacher模型,而是使用小的Student作为线上精排模型,进行在线推理。小的Student模型优势如下:
Student结构较为简单,所以在线推理速度会大大快于复杂模型; Teacher将一些知识迁移给Student,所以经过知识蒸馏的Student推荐质量也比单纯Student自己训练质量要高。
以上就是典型的在精排环节采用知识蒸馏的思路。
2.2 模型召回/粗排环节采用知识蒸馏
由于模型召回或者粗排环节,作为精排的前置环节,需要在准确性和速度方面找到一个平衡点,在保证一定推荐精准性的前提下,对物品进行粗筛,减小精排环节压力。所以,这两个环节本身,从其定位来说,并不追求最高的推荐精度,就算模型效果比精排差些,这也是完全可以接受的,毕竟在这两个环节,如果准确性不足可以靠返回物品数量多来弥补。而模型小,速度快则是模型召回及粗排的重要目标之一。这就和知识蒸馏本身的特点对上了,所以在这里用特别合适。
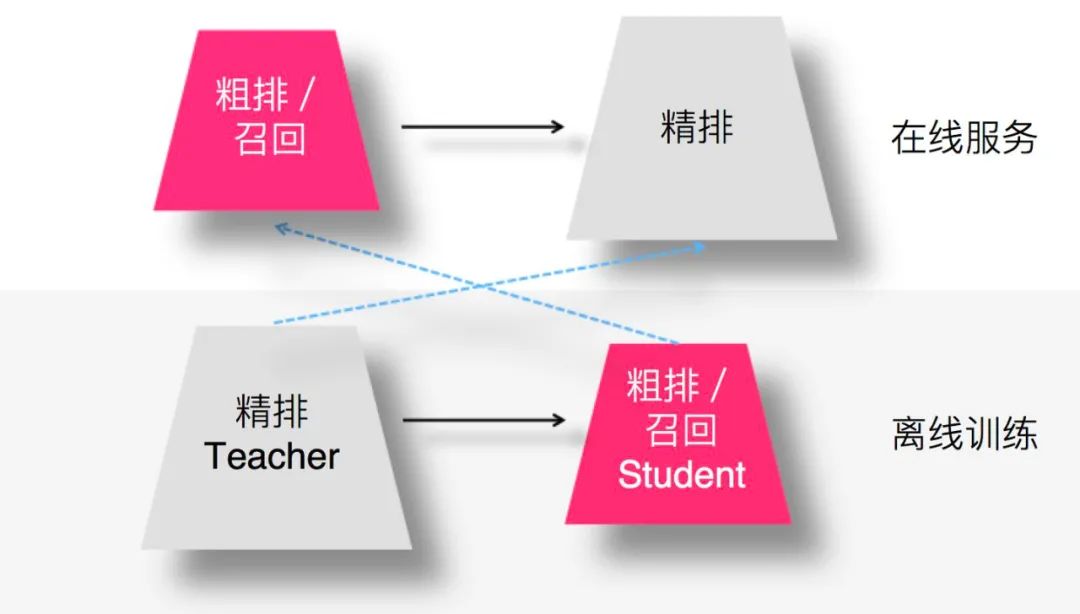
图:来源于参考文献2
那么,召回或者粗排怎么用蒸馏呢?如上图所示,用复杂的精排模型作为Teacher,召回或粗排模型作为小的Student,比如双塔DNN模型等,Student模型模拟精排环节的排序结果,以此来指导召回或粗排Student模型的优化过程。这样,我们可以获得满足如下特性的召回或者粗排模型:
首先,推荐效果好,因为Student经过复杂精排模型的知识蒸馏,推荐效果可以非常接近于精排模型效果; 其次,Student模型结构简单,所以速度快,满足召回、粗排环节对于速度的要求; 最后,通过Student模型模拟精排模型的排序结果,可以使得召回、粗排这两个环节的优化目标和精排环节的优化目标保持一致,即与推荐任务的最终优化目标保持一致。
在推荐系统中,召回、粗排环节优化目标保持和精排优化目标一致,其实是很重要的,但是这点往往在实际中容易被忽略,或者因为条件所限无法考虑这一因素,比如非模型召回,从机制上是没办法考虑这点的。这里需要注意的一点是:如果召回模型或者粗排模型的优化目标已经是多目标的,对于新增的模型蒸馏来说,可以作为多目标任务中新加入的一个目标,当然,也可以只保留单独的蒸馏模型,完全替换掉之前的多目标模型,貌似这两种思路应该都是可以的,需要根据具体情况进行斟酌选择。
以上就是知识蒸馏技术在推荐系统的召回、粗排、精排环节的大概应用思路。下面,我们根据工业界公开的相关论文和资料,详细地了解在推荐系统的各个环节里,采用知识蒸馏的具体方法。
3. 知识蒸馏在推荐系统中的研究进展
3.1 精排环节应用知识蒸馏
3.1.1 《Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net》
这是阿里妈妈的一篇将“目标蒸馏-logits方法“应用到推荐系统领域的论文。 该论文提出的背景是:响应时间直接决定在线响应系统的效果和用户体验。比如在线展示广告系统中,针对一个用户,需要在几ms内,对上百个候选广告的点击率进行预估。因此,如何在严苛的响应时间内,提高模型的在线预测效果,是工业界面临的一个巨大问题。此外,简单的网络速度快,但精度不如复杂的网络好;复杂的网络精度好,但是计算量大,训练和线上推理速度都很慢。如何能结合小网络的速度和大网络的精度也是一个很难、很重要的问题。
为了解决上述问题,阿里巴巴在2018年AAAI上的论文《Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net》中提出了一个新型框架:训练阶段,同时训练“复杂”和“简单”两个复杂度有明显差异的网络,简单的网络称为轻量网络(Light Net),复杂的网络称为助推器网络(Booster Net),它相比前者有更强的学习能力。两网络共享部分参数,分别学习类别标记(Label)。此外,轻量网络通过学习助推器的soft target来模仿助推器的学习过程,从而得到更好的训练效果。测试阶段,仅采用轻量网络进行预测。
火箭发射过程中,初始阶段,助推器和飞行器一同前行,第二阶段,助推器剥离,飞行器独自前进。在该论文的框架中,训练阶段,有繁简两个网络一同训练,复杂的网络起到助推器的作用,通过参数共享和信息提供推动轻量网络更好的训练;在预测阶段,助推器网络脱离系统,轻量网络独自发挥作用,从而在不增加预测开销的情况下,提高预测效果。整个过程与火箭发射类似,所以命名该系统为“火箭发射”。整个网络结构如下:
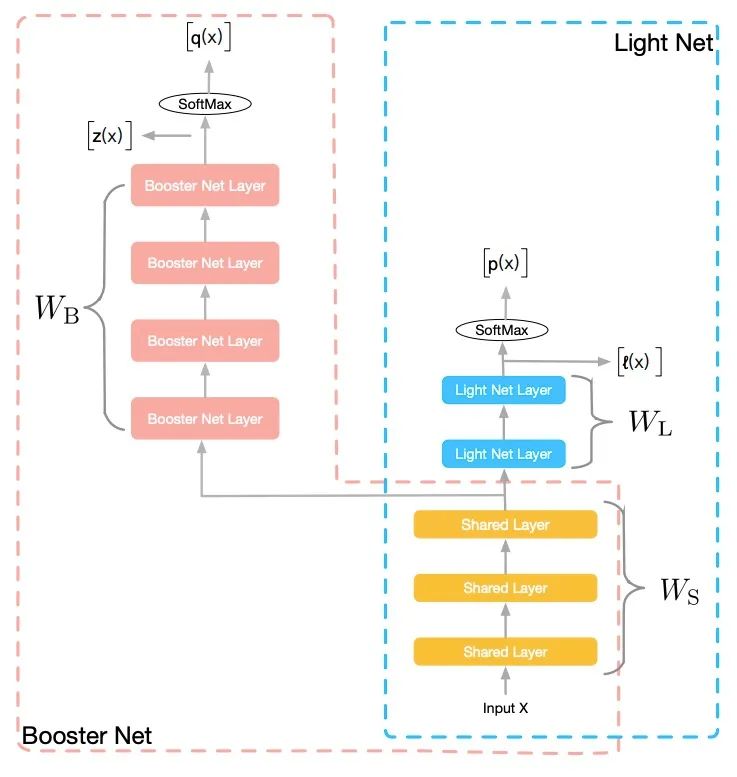
助推器网络和轻量网络共享部分层的参数,共享的参数可以根据网络结构的变化而变化。在神经网络中,低层可以用来学习信息表示,低层网络的共享,可以帮助轻量网络获得更好的信息表示能力。如上图所示,训练阶段,我们同时学习两个网络:Light Net 和Booster Net,两个网络共享部分信息。我们把大部分的模型理解为表示层学习和判别层学习、 ,表示层学习的是对输入信息做一些高阶处理,而判别层则是和当前子任务目标相关的学习。表示层的学习是可以共享的,共享的信息为底层参数,这些底层参数能一定程度上反应了对输入信息的基本刻画。在整个训练过程中,网络的Loss如下:
Loss包含三部分:第一项,为Light Net对Ground Truth的学习;第二项,为Booster Net对Ground Truth的学习;第三项,为两个网络Softmax之前的logits的均方误差(MSE),该项作为hint loss,用来使两个网络学习得到的logits尽量相似。
与传统的知识蒸馏相比,该论文提出的新型框架的创新点和优势在于:
复杂和简单两个网络同时训练。 一方面, 缩短总的训练时间。相比传统teacer-student范式中,先训练一个复杂网络,然后用其训练一个简单网络。这里同时训练复杂和简单两个网络缩短了总的训练时间。另一方面, 助推器网络全程提供soft target信息给轻量网络,从而达到指导轻量网络整个求解过程的目的。这与一般的teacher-student 范式下,学习好大模型,仅用大模型固定的输出作为soft target来监督小网络的学习有着明显区别,因为Booster Net的每一次迭代输出虽然不能保证对应一个和Label非常接近的预测值,但是到达这个解之后有利于找到最终收敛的解。相比传统方法,同时训练获得了更多的指导信息,从而取得更好的效果。 采用梯度固定技术。 训练阶段,两网络soft target的loss(hint loss)只用于轻量网络的梯度更新,而不更新助推器网络,从而使得助推器网络不受轻量网络的影响,只从真实标记中学习信息。由于助推器网络有更多的参数,有更强的拟合能力,我们需要给它更大的自由度来学习,尽量减少轻量网络对它的拖累。梯度固定技术的目的是,在hint loss进行梯度回传时,我们固定助推器网络独有的参数 不更新,让该时刻的助推器网络前向传递得到的 监督轻量网络的学习,从而使得小网络向大网络靠近。这一技术,使得助推器网络拥有更强的自由度来学习更好的模型,而助推器网络效果的提升,也会提升轻量网络的训练效果。
在线响应时间对在线系统至关重要。该论文提出的火箭发射式训练框架,在不提高预测时间的前提下,提高了模型的预测效果,为提高线上模型效果提供了新思路。目前Rocket Launching的框架为在线CTR预估系统弱化在线响应时间限制和模型结构复杂化的矛盾提供了可靠的解决方案,该技术可以做到在线计算被压缩倍的情况下性能不变。在阿里真实的应用场景中,日常可以减少在线服务机器资源消耗,双十一这种高峰流量场景更是保障算法技术不降级的可靠方案。
【相关文章】
Zhou G, Fan Y, Cui R, et al. Rocket launching: A universal and efficient framework for training well-performing light net[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2018, 32(1).
3.1.2 《Privileged Features Distillation at Taobao Recommendations》
这篇同样是阿里的一篇将“目标蒸馏-logits方法“应用到推荐系统领域的论文,被KDD 2020所接收。 论文《Privileged Features Distillation at Taobao Recommendations》提出的蒸馏技术是我在工业界见过的知识蒸馏用在推荐系统领域最广泛的技术之一,整篇文章思路比较朴素,对于工业应用具有非常大的借鉴意义。因此,我会详细重点介绍这篇论文。
(1)推荐中的优势特征
在推荐系统的粗排阶段,主要的任务是预估召回阶段返回的候选集中每个物品的点击率,然后选择排序分最高的一些物品进入精排阶段。粗排阶段输入的特征主要有用户的行为特征(如用户的历史点击/购买行为)、用户属性特征(如用户id、性别、年龄等)、物品特征(如物品id、类别、品牌等)。在粗排阶段,由于要在毫秒内给成千上万的候选物品打分,因此模型的复杂度受到了很大的限制,工业界传统的做法是使用内积模型,把用户侧和物品侧作为双塔,在请求时,把用户侧的向量和候选物品向量进行内积运算,从而对物品池做粗筛。有一些交叉特征对粗排效果有明显的提升,比如用户在过去小时内在待预估商品类目下的点击次数、用户过去小时内在待预估商品所在店铺中的点击次数等。对于这些交叉特征,如果放到用户侧,那么针对每个物品都需要计算一次用户侧的塔;如果放到物品侧,同样针对每个物品都需要计算一次物品侧的塔,这会大大加大计算复杂度,增加线上的推理延时。因此,这些交叉特征对于粗排阶段的模型来说,通常在线上无法应用,我们就称它们为粗排CTR预估中的Privileged Features。
在精排阶段,我们不仅要预估CTR,还要预估CVR,即用户点击跳转到商品页后购买该商品的概率。在电商领域的推荐,主要目标是最大化GMV,即 GMV = CTR * CVR * Price 。一旦预估了所有商品的CTR和CVR,我们就可以根据预期的GMV对它们进行排名,使得GMV最大化。在CVR的定义下,很明显用户在商品页的行为特征对于CVR预估会非常有帮助,比如说用户在商品页停留的时长、是否查看评论、是否与商家沟通等。但是,这些特征在线上预估阶段是无法获取的,商品在被用户点击之前就需要估计CVR以进行排序。所以对于CVR预估来说,用户在点击后进入到商品页的一些特征(比如停留时长、是否查看评论、是否与商家沟通等)同样是Privileged Features。
再比如,在短视频粗排或精排阶段要做多目标预估,即不仅要预估点击率还要预估该视频的点赞、评论、分享转发、进入个人主页、收藏、下载等互动目标。如果此时,用户点击该视频,并对该视频进行了观看。那么,用户的视频观看时长特征,对于互动目标的预估显的很重要,但是在线上推理时,我们需要在预估点击率之前就要估计互动目标,并不能获取到视频观看时长这一重要特征。因此,我们可以把用户观看视频时长特征作为Privileged Features。
使用这些Privileged Features,可以提升模型的预测精度。因此本论文借鉴模型蒸馏的思想,让粗排阶段的CTR模型或者是精排阶段的CVR模型,都能够学习到一些Privileged Features的信息。
(2)优势特征蒸馏
直观来看,使用多任务学习(Multi-Task Learning,简称MTL)来预测优势特征是一个不错的选择。然而,在多任务学习中,每个子任务往往很难满足对其他任务的无害准则(No-harm Guarantee),换句话说,预测优势特征的任务可能会对原始的预测任务造成负面影响,尤其是预测优势特征的任务比原始任务来得更有挑战性时。从实践的角度来看,如果同时预测许多优势特征,如何平衡各个任务的权重也会非常困难。
为了更优雅地利用优势特征,本论文提出优势特征蒸馏(Privileged Features Distillation,简称PFD)。在离线环境下,我们会同时训练两个模型:一个学生模型以及一个教师模型。其中学生模型和原始模型完全相同,而教师模型额外利用了优势特征, 其准确率也因此更高。 通过将教师模型蒸馏出的知识(Knowledge,论文中特指教师模型中最后一层的输出)传递给学生模型,可以辅助其训练并进一步提升准确率。在线上服务时,我们只抽取学生模型进行部署,因为输入不依赖于优势特征,离线、在线的一致性得以保证。在PFD中,所有的优势特征都被统一到教师模型作为输入,加入更多的优势特征往往能带来模型更高的准确度。相反,在MTL中,预测更多的优势特征反而可能损害原始模型。更进一步,相比原始目标函数,PFD只引入额外一项蒸馏误差,因此更容易与原始损失函数平衡。
上面的损失函数被分为两部分,两部分都是计算交叉熵。损失的第一部分是可以称为hard loss,其label是或者;第二部分可以称为soft loss或distillation loss,其label是Teacher网络的Softmax输出,是概率值,如(的概率点击,的概率不点击)。其中,表示普通的输入特征,表示优势特征,表示Label,表示模型的输出,表示损失函数,其中下标 指代student,指代distillation,指代teacher。是平衡两个损失函数之间的超参数。值得注意的是,在教师模型中,除了输入优势特征以外,我们还将普通特征输入到教师模型中去。如上述公式中所示,教师模型的参数需要预先学好,这直接导致模型的训练时间加倍。
PFD不同于常见的模型蒸馏(Model Distillation,简称MD)。在MD中,教师模型和学生模型处理同样的输入特征,其中教师模型会比学生模型更为复杂,比如,教师模型会用更深的网络结构来指导使用浅层网络的学生模型进行学习。在PFD中,教师和学生模型会使用相同网络结构,而处理不同的输入特征。在下图中,我们给出了优势特征蒸馏和模型蒸馏的网络结构区别。

如上述损失函数的公式所示,教师模型的参数需要预先学好,这直接导致模型的训练时间加倍。一种更直接的方式是同步更新学生和教师模型,因此目标函数变成如下形式:
尽管同步更新能显著缩短训练时间,但也会导致训练不稳定的问题。尤其在训练初期,教师模型还处于欠拟合的情况下,学生模型直接学习教师模型的输出会有一定的概率导致训练偏离正常。解决这个问题的方法也非常简单,只需要在开始阶段将设定为,然后在预设的迭代步将其设为固定值。具体步骤可以参见下图算法1。值得一提的是,我们让蒸馏误差项只影响学生网络的参数的更新,而对教师网络的参数不做梯度回传,从而避免学生网络和教师网络相互适应(co-adaption)而损失精度。

(3)优势特征蒸馏+模型蒸馏
在上图中,我们比较了模型蒸馏和优势特征蒸馏的异同,既然两者都能提升学生模型的效果且互补,一个直观的想法就是将这两种技巧结合在一起以进一步提升效果。
这里我们尝试在粗排CTR模型中使用这种PFD+MD技巧。在粗排中,我们使用内积运算对候选商品集合进行打分。事实上,无论采用何种映射表征用户或者商品,模型最终都会受限于顶层双线性(Bi-Linear)内积运算的表达能力。内积粗排模型可以看成是广义的矩阵分解,不过与常规的分解不同的是,这里额外融合了各种辅助信息(side information)。按照神经网络的万有逼近定理,非线性(Non-Linear)MLP,有着比双线性内积运算更强的表达能力,在这里很自然地被选为更强的教师模型。下图给出了粗排PFD+MD蒸馏框架示意图。事实上,图中加了优势特征的教师模型就是我们线上精排CTR模型,所以这里的蒸馏技巧也可以看成粗排反向学习精排的打分结果。
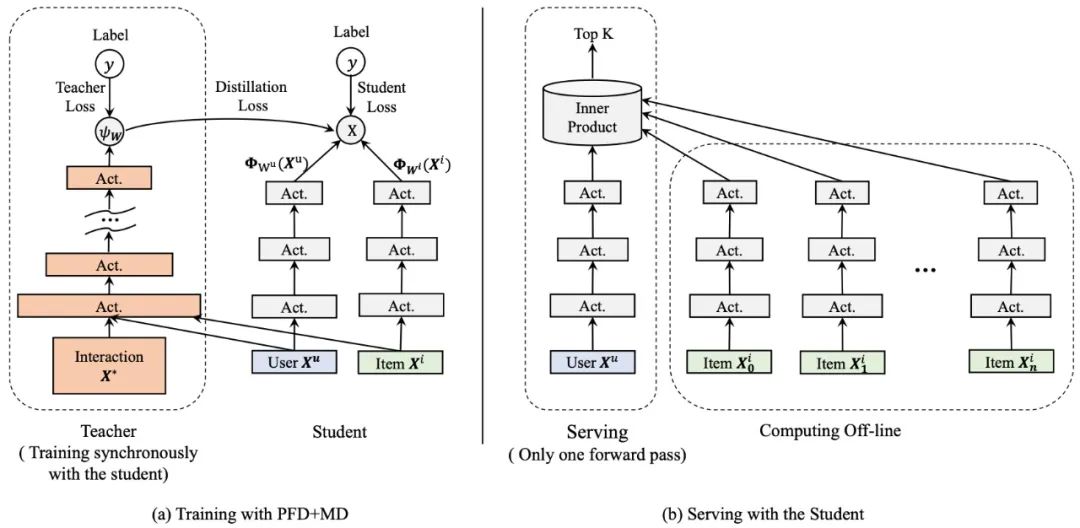
(4)实验结论
在手淘信息流的两个基础预测任务上进行PFD实验。在粗排CTR模型中,通过蒸馏交叉特征(在线构造特征以及模型推理延时过高,在粗排上无法直接使用)以及蒸馏表达能力更强的MLP模型,即通过MD+PFD可以在线提升%的点击指标(同时保证成交指标不降)。在精排CVR模型上,通过蒸馏停留时长等后验特征,只对PFD做测试,对比Baseline,PFD提升%的成交指标(并且点击指标不降)。
【相关文章】
Xu C, Li Q, Ge J, et al. Privileged Features Distillation at Taobao Recommendations[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 2590-2598.
3.1.3 《Ranking Distillation: Learning Compact Ranking Models With High Performance for Recommender System》
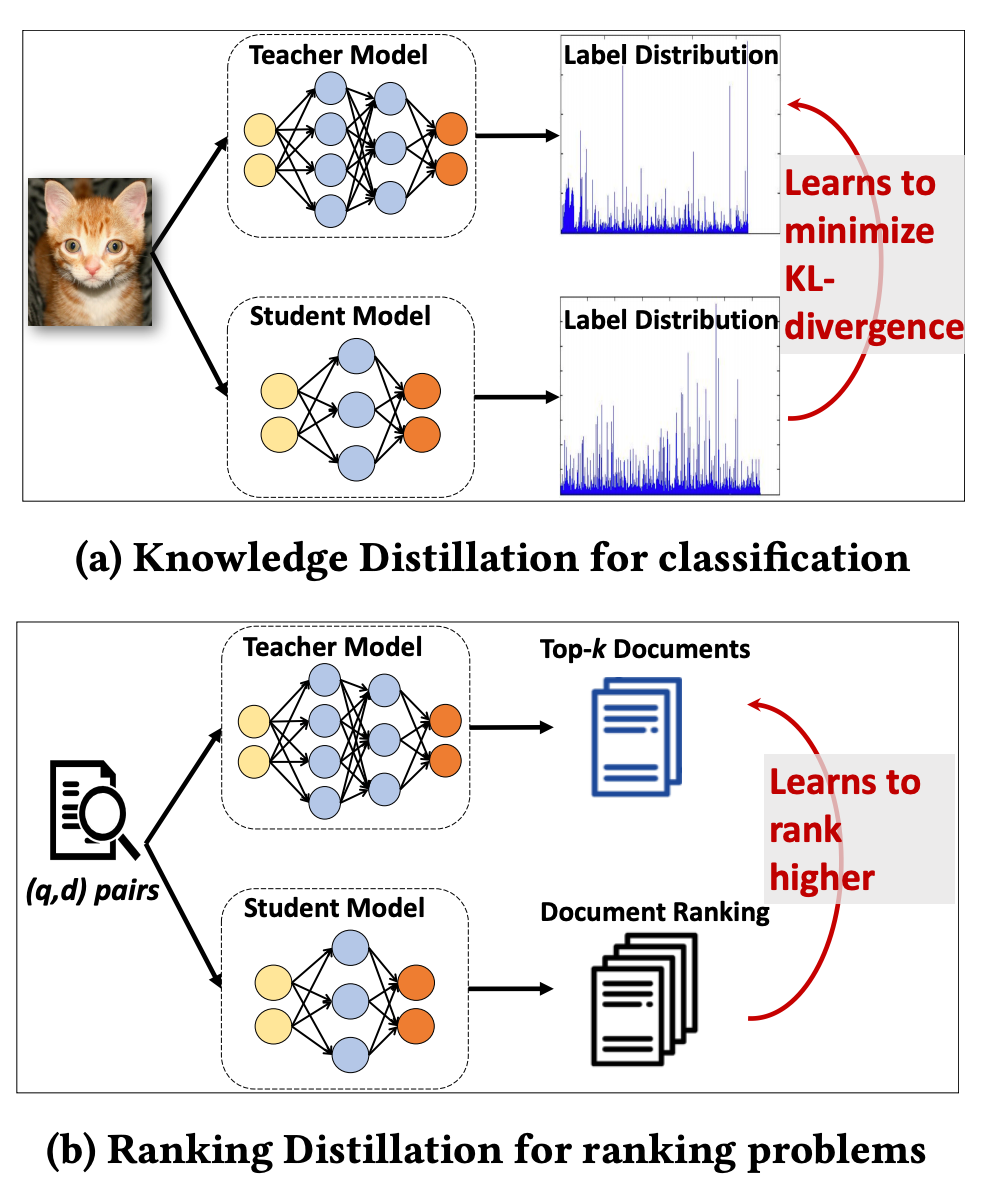
这篇论文是将“目标蒸馏-logits方法“应用到推荐系统领域的论文,被KDD 2018所接收。 因为是推荐和信息检索相关的论文,有一定的借鉴价值,因此也在这里给大家介绍一下。本论文提出的背景是:(1)检索系统或推荐系统中模型庞大,可以用蒸馏网络的方式提升工程效率;(2)目标是给一个query,预测检索系统的Top K相关的documents。知识蒸馏是指:给定一个输入,学生模型学习最小化Label和教师模型Soft-target的KL散度;排序蒸馏是指:给定一个query,学生模型将因其教师模型的前K个文档排名而获得更高的排名;两者区别如下图所示。
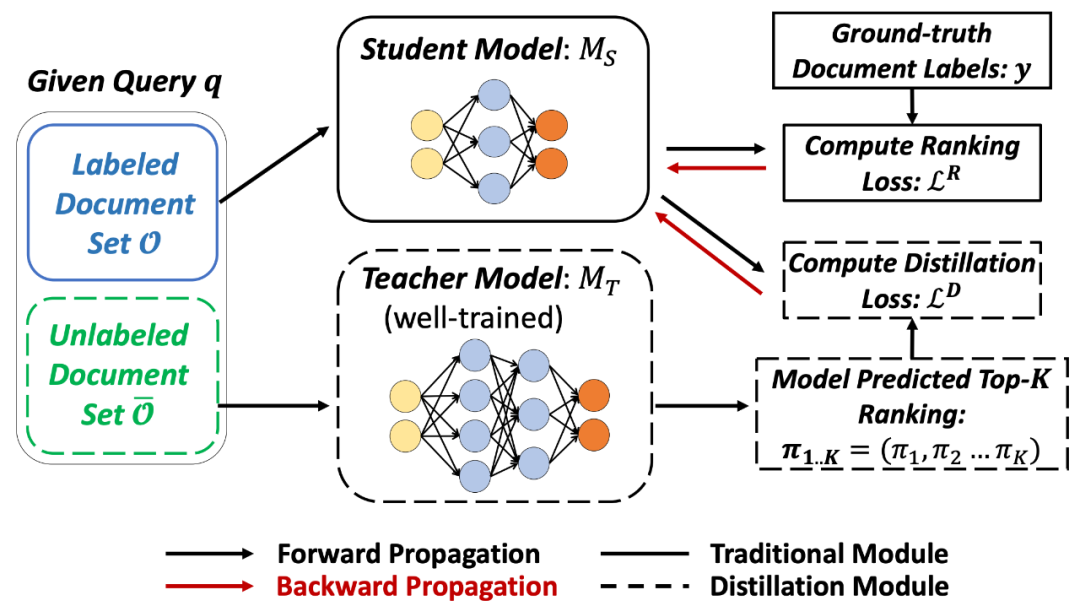
排序蒸馏的过程如下图所示。第一阶段训练教师网络,对于每个query预测Top K相关documents,补充为学生网络的Ground truth信息;第二阶段教师网络的Top K作为正例加到学生网络中一起进行训练,使得学生网络和教师网络的预测结果更像。
排序蒸馏的损失函数如下:
其中,Loss的第一部分为交叉熵Loss, 为真实标签, 为学生网络的预测结果。第二部分为蒸馏损失,教师网络对无标签数据排序出的Top K作为正样本指导学生模型学习。第二部分Top K 损失的具体公式为:
其中,为每条教师网络中预测的样本的权重,有两种方式生成:
对位置进行加权(即,Top 1到K的顺序); 对排序相关性进行加权(考虑教师网络预测的documents与query的相关性程度)。
【相关文章】
Tang J, Wang K. Ranking distillation: Learning compact ranking models with high performance for recommender system[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 2289-2298.
3.1.4 《Ensembled CTR Prediction via Knowledge Distillation》
这是华为发表的一篇将“目标蒸馏-logits方法“和“特征蒸馏(即学习Teacher模型的中间层特征)”应用到推荐系统领域的论文,被CIKM 2020所接收。 当前对于CTR预估的研究大致集中在两个方面,一种是尝试更为复杂的网络结构来更好的捕捉特征之间的交叉信息以及用户的动态行为信息,如引入卷积神经网络、循环神经网络、注意力机制和图神经网络等;另一种趋势是沿用Wide & Deep的思路,尝试将多个子模块进行融合,如DeepFM、DCN、XDeepFM、AutoInt等。尽管这些研究带来了点击率预估效果的提升,但是随着模型结构变得更加复杂,在实际工业界使用这些模型耗时会越来越高,往往难以真正在线上进行部署。那么如何既能保持多模型融合的效果,同时又能够使得模型更加轻量化呢?知识蒸馏的方式是一种不错的选择。
(1)单教师网络知识蒸馏
首先来看一下单教师网络知识蒸馏的框架:
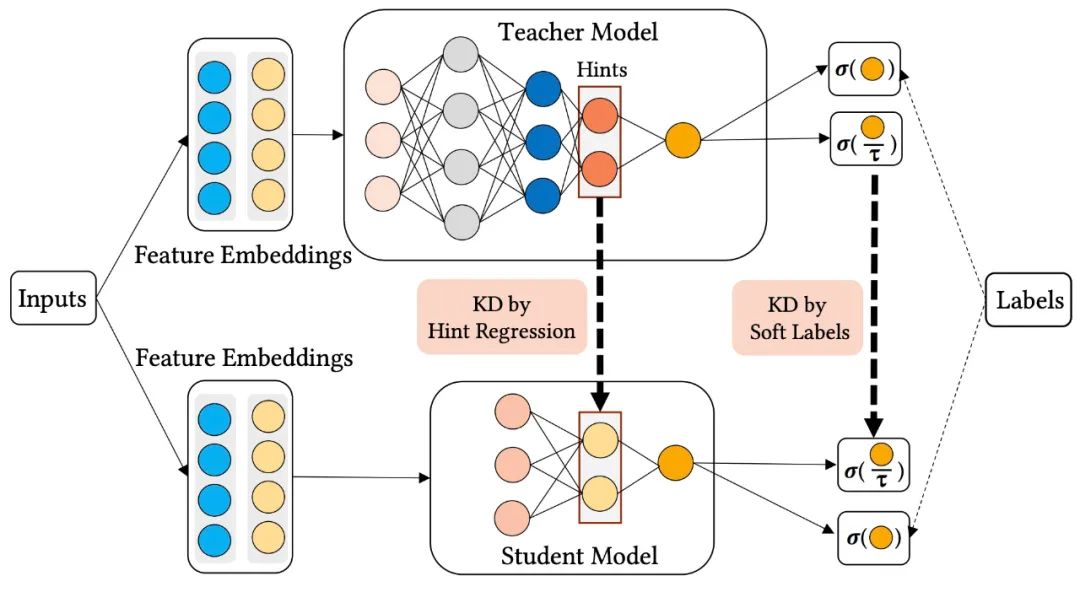
从上图中可以看到,用同样的特征分别输入到teacher网络和student网络中,得到teacher网络的输出为 ,得到student网络的输出为 ,那么在训练时teacher网络和student网络的损失分别为:
其中, 表示交叉熵损失, 表示蒸馏损失。 表示teacher网络的损失,它只有交叉熵损失。 表示student网络的损失,它不仅包含交叉熵损失,还包括一项蒸馏损失。为了使知识从教师模型转移到学生模型,在论文中,使用两种最常用的蒸馏方法:soft label(目标蒸馏-logits方法)和hint regression(学习Teacher模型的中间层特征)。
soft label蒸馏损失如下所示:
其中, 表示交叉熵损失,表示教师模型最后softmax层输出的类别概率,表示学生模型最后softmax层输出的类别概率,就是温度。关于soft label蒸馏、hint regression蒸馏和温度参数作用,可以看我的这篇文章:深度学习中的知识蒸馏技术
hint regression蒸馏损失函数如下:
hint regression的目的是引导student网络学习teacher网络的中间层表示。这里代表teacher网络的中间层表示,代表student网络中被指导的层的输出。通过矩阵进行变换,期望二者的距离越近越好。
(2)多教师网络知识蒸馏
模型融合能够有效提升CTR预估的效果,但会带来耗时的增加。因此,可以通过知识蒸馏的方式,让student网络从多个模型中进行学习,来达到近似或比模型融合更佳的效果。因此,论文提出了多教师网络知识蒸馏,其结构如下图所示:
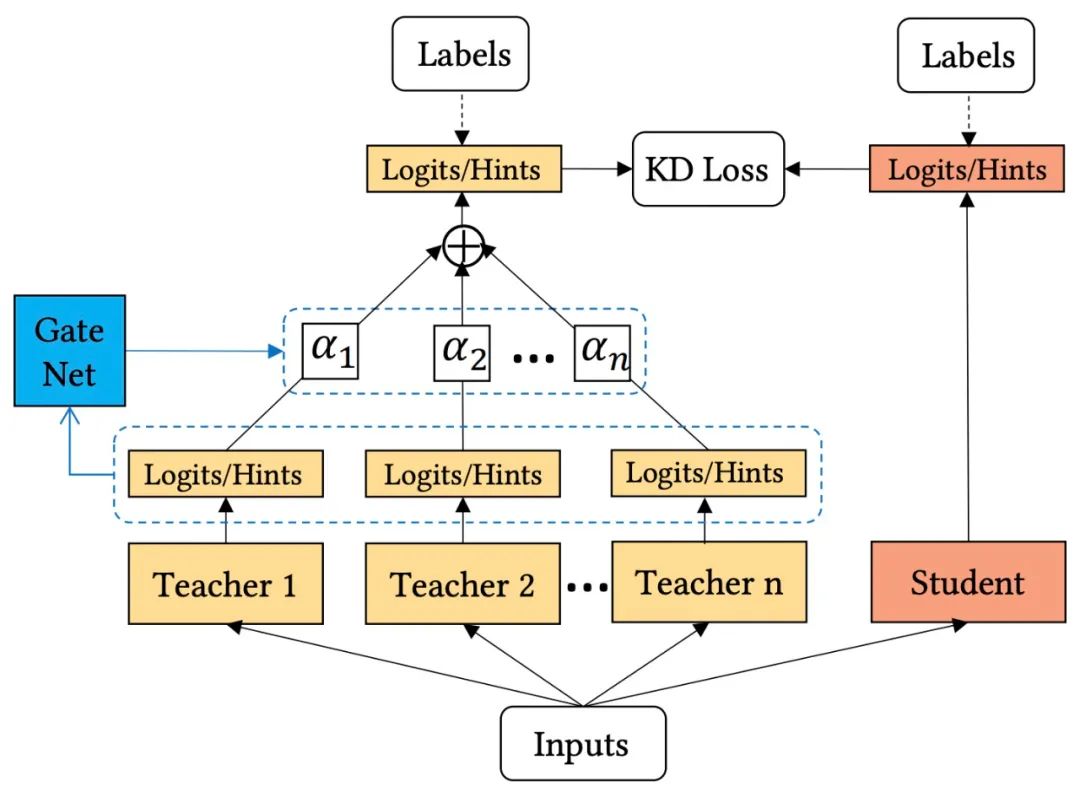
这里的主要问题是,多个teacher网络如何向student网络传递知识?最简单的方式就是对所有teacher模型的输出进行平均,从而使问题简化为向单个教师学习。这种做法实现简单,但是不同teacher的模型结构和训练框架都不同,因此并非所有的教师模型都可以在每个样本上提供同等重要的知识。效率低下的教师模型甚至可能会误导学生模型的学习。为了从多个教师模型那里获得有效的知识,论文提出了一种自适应的集成蒸馏框架,如上图所示,可以动态地调整每个教师模型的贡献。因此有了如下式所示的自适应蒸馏损失函数:
为了实现动态学习权重和自适应不同的训练样本,作者提出了一个教师门控网络(Teacher gating network)来调整教师模型的重要性权重,从而实现按样本进行教师模型选择。更具体地说,采用softmax函数作为门控函数,计算方式如下:
(3)网络训练
知识蒸馏一般有两种训练方式,pre-train方式和co-train方式。pre-train方式是预先训练teacher网络,然后再训练student网络;co-train方式则是通过上述介绍的损失对teacher网络和student网络进行联合训练。co-train方式往往训练速度更快,但所需的GPU资源也会更多。论文的实验部分也对这两种训练方式进行了比较,感兴趣的同学可以阅读一下论文原文。
【相关文章】
Zhu J, Liu J, Li W, et al. Ensembled CTR Prediction via Knowledge Distillation[C]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020: 2941-2958.
3.1.5 百度CTR 3.0 双DNN联合训练
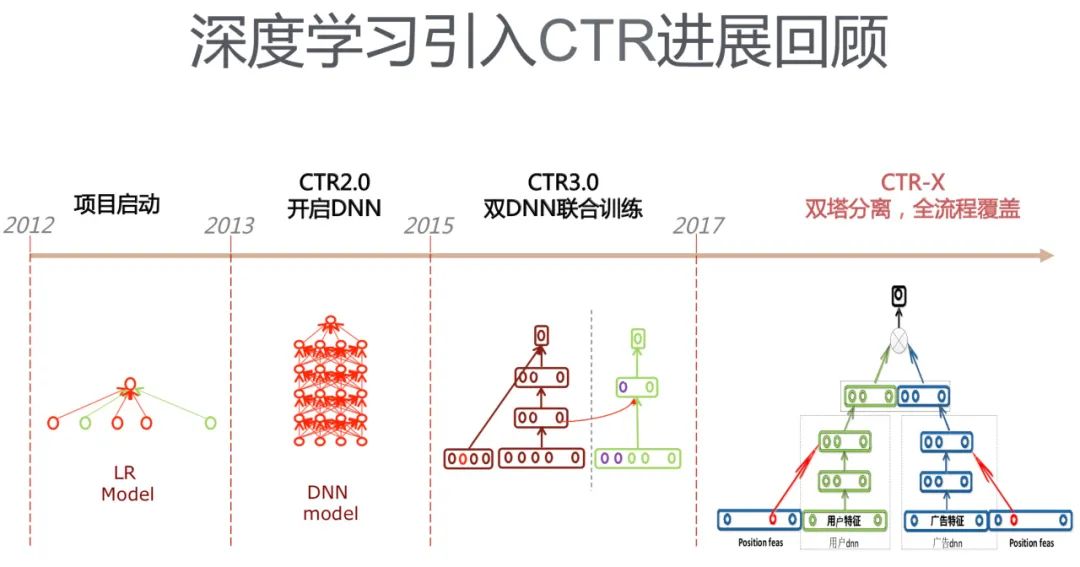
这是2017年百度当时商务搜索智能交互部负责人刘斌新在其PPT《AI筑巢:机器学习在百度凤巢的深度应用》中提到的类似知识蒸馏的技术。由于百度极少对外公开自己的技术,放在这里是想让大家了解一下,百度广告CTR模型的发展历史。
百度广告CTR模型的发展历程如下图所示,CTR-X是一个用于粗排阶段的DSSM,其中CTR3.0与知识蒸馏的工作比较相似,类似于将“特征蒸馏(即学习Teacher模型的中间层特征)”应用在CTR模型中, 也是用于精排阶段,但是训练两个结构差不多的DNN需要运用类似于特征迁移的方法,左侧DNN主要用来学习稀疏特征embedding向量,右侧DNN使用左侧训练得到的embedding向量和其它特征作为输入训练CTR模型。
3.1.6 爱奇艺在排序阶段提出了双DNN排序模型
近年来随着人工智能的发展,深度学习开始在工业界不同场景落地。深度学习跟以前的机器学习模型相比,其中很重要的特点就是能在模型侧自动构建特征,实现端到端学习,效果也有明显提升,但新的问题如模型效果和推理效率的冲突也开始凸显。爱奇艺提出了新的在线知识蒸馏方法来平衡模型效果和推理效率,在推荐场景上获得了明显的效果。爱奇艺在探索升级排序模型的过程中提出的双DNN排序模型,这是一个将“目标蒸馏-logits方法“和“特征蒸馏(即学习Teacher模型的中间层特征)”结合,应用到推荐系统领域的实践。
爱奇艺尝试了一些复杂模型来取代改进版的Wide & Deep模型,如DCN, xDeepFM等,但发现需要平衡large model 的模型效果和推理性能是有待解决的比较关键的问题。xDeepFM比较难落地主要有以下两点原因:
推理性能:同等情况下,在CPU上推理,xDeepFM与改进版的Wide & Deep模型相比,耗时是其~倍; 使用GPU时,只有在大batch下,xDeepFM推理性能才符合要求。
通过实践,爱奇艺提出了一种新的排序模型框架: 双DNN排序模型,其核心在于提出了新的联合训练方法,从而解决了高性能复杂模型的上线问题,该框架的特点和优势总结如下:
(1)双DNN
左侧DNN-Teacher网络(红框):模型性能更好的复杂模型,推理性能差; 右侧DNN-Student网络(黄框):模型性能一般的简单模型,推理性能佳;
(2) Fine-Tune
Teacher网络(红框)和Student网络(黄框)share底层特征参数(蓝框),teacher网络多了Feature Interaction Layer层(该层是teacher网络的核心,可以容纳各种特征交互)。
(3)联合训练
教师网络监督指导学生网络的学习; 学生网络学习教师网络的隐层输出和Logits输出(特征迁移 + 输出迁移); Teacher网络和Student网络同时进行训练; 训练稳定,大网络性能天花板不受小网络影响;
排序模型结构如下:
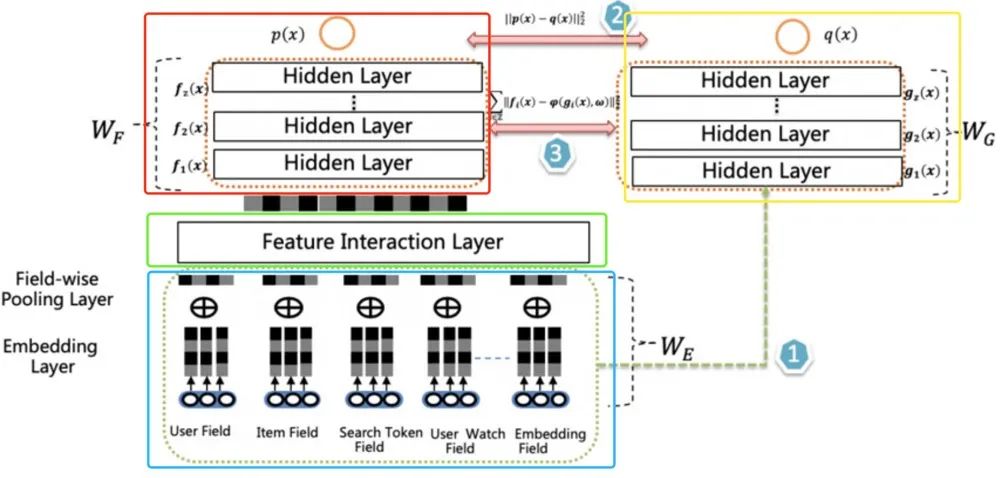
双DNN排序模型由两个DNN CTR模型组成,左侧是Teacher,右侧是Student,Student 模型是最终用于上线推理的CTR 模型。两者共享特征输入和表示,但是左侧相比右侧多了Feature Interaction Layer。左侧和右侧有各自独立的MLP , 其包含多层Hidden Layer。主要Layer的介绍如下:
Embedding Layer: 输入表示层,不同特征按Field组织,稀疏Field ID embedding化后通过average pooling得到field的embedding表示; Feature Interaction Layer: 这是左侧模型核心,其可以容纳各种形式的特征组合组件,二阶或高阶特征组合都可以放置在其中; Classifier Layer: 两个DNN CTR模型的Classifier,一般是多层DNN;
【相关文章】
双DNN排序模型:在线知识蒸馏在爱奇艺推荐的实践,地址:https://mp.weixin.qq.com/s/ZNjC30F28uX2lBkHBAAU3g
3.2 粗排环节应用知识蒸馏
3.2.1 腾讯-全民K歌粗排双塔模型实践
这是一个将“目标蒸馏-logits方法“应用到推荐系统领域的实践。 粗排夹在召回跟精排之间,它的定位是什么?相比于召回,粗排更强调排序性,也就是更强调topk内部的排序关系;相对于精排,粗排更强调性能,因为精排通常有非常复杂的网络结构,非常大的参数量,这也意味着它在实际应用的过程中比较难去处理一个较大规模量级的候选集的打分,这时粗排就必须要解决这个问题,所以它在性能上会相较于精排有更多的要求。
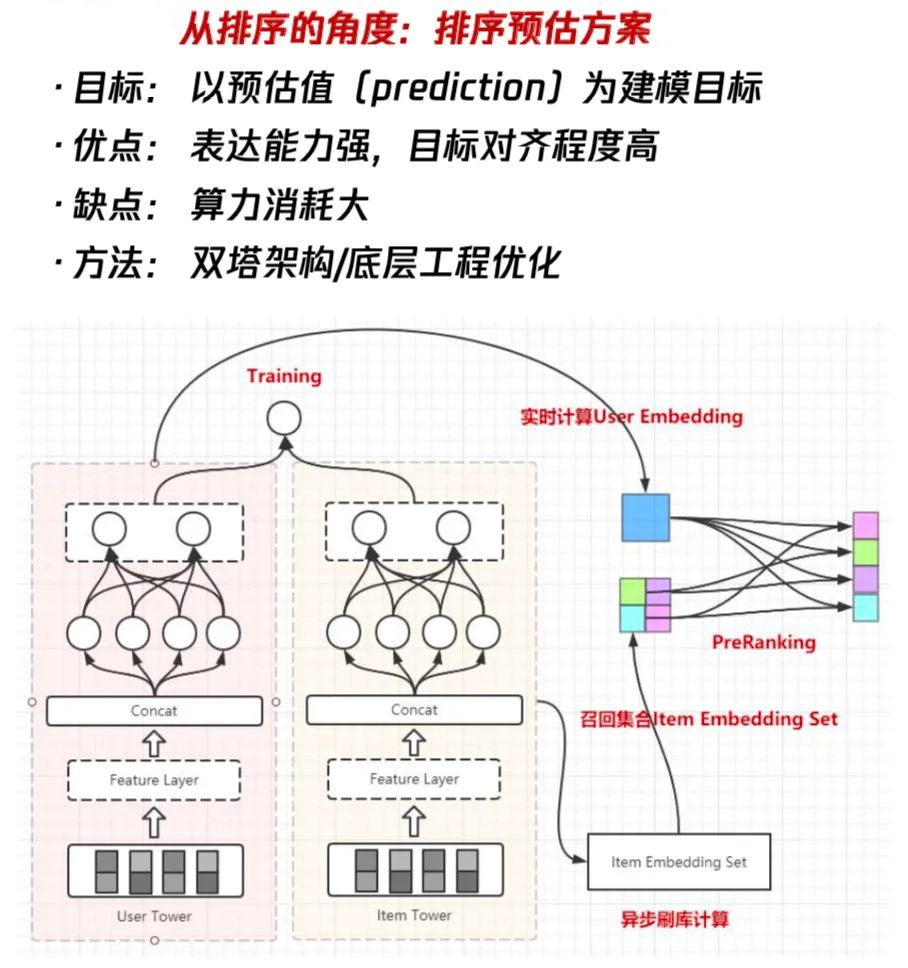
从精排的角度,把粗排当成是精排的迁移或压缩,也就是说从粗排到精排这是一条排序的路线,它的建模目标是预估值。这种粗排建模方法的好处是它的表达能力很强,因为通常会用到一些比较复杂的网络结构,而且它跟精排的联动性是更好的,可以让粗排跟精排的目标保持某种程度上的一致性。同时,它的缺点也凸显出来了,就是我们用到了复杂的方法,算力的消耗一定也会相应的提升。因此,需要着重解决的是如何在有限的算力下尽可能地突破表达能力上限。在这种路线下,我们通常会在架构选择上选择双塔结构模型,如上图所示。
我们通过把user和item的feature进行结构解耦与分开建模,然后完成整个架构的设计,在模型训练完毕之后,我们会通过user serving实时的产出user embedding,再通过索引服务把该用户所有的候选集合的ID给取出来,最后在user embedding跟item embedding之间做內积的运算,得到一个粗排的预估值,作为整个粗排阶段的排序依据。
这么做的优势是user和item的结构是解耦的,内积计算的算力消耗小。同时,它的缺点也非常的明显:
第一个是它在特征表达上是缺失的,因为user跟item解耦之后,很难使用一些交叉特征,一旦用了交叉特征,有多少item就得进行多少次预估,这违背了我们使用双塔模型的初衷。 第二个是双塔模型在结构上也是有缺陷的,从上面这幅框架图中可以看到,user跟item的交互非常少,这会限制模型的表达能力的上限。
如果选择了双塔结构模型,我们可以保障它的性能,但是需要进一步的考虑如何避免这种简易的结构所带来的效果上的损失。在这种情况下,我们通常会使用一些模型蒸馏的方式。
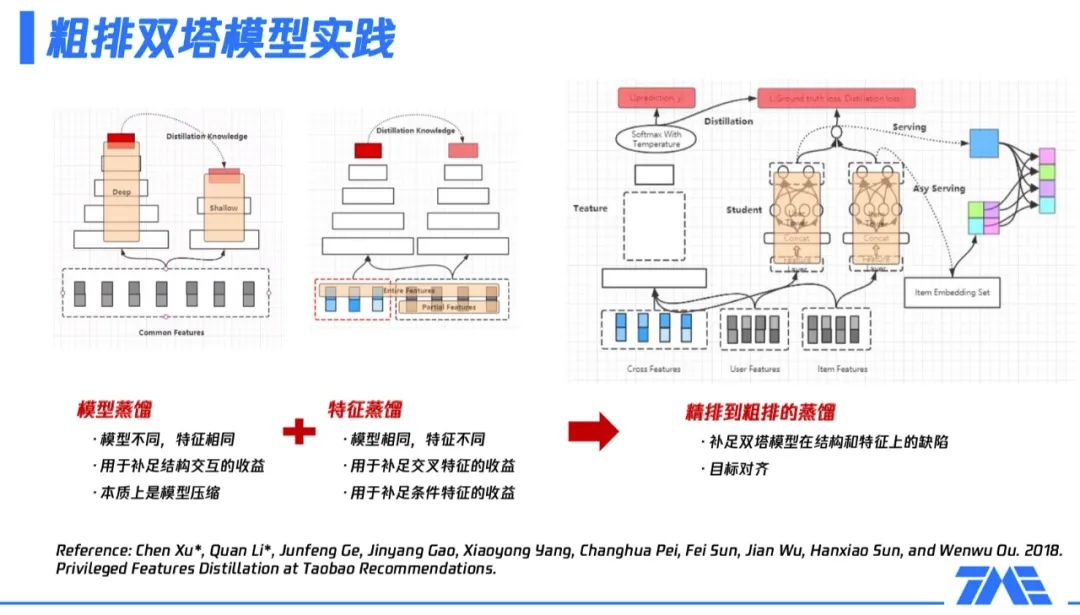
具体的,我们来看看全民K歌算法团队如何做粗排模块的蒸馏,主要是分为两个大的方向:
模型蒸馏,主要适用于模型不同但特征相同的情况,比如,包含多个场景的框架里,某些场景对性能有要求;由于有一些额外的外部限制,使某场景无法用很复杂参数量非常大的模型,可以用一个子模型使用全部特征。此时,模型蒸馏主要是弥补子模型缺少复杂结构或交互结构导致的部分收益损失,本质上是一种模型压缩方案。 特征蒸馏,主要适用于模型相同但特征不同的情况,比如,在某些场景,无法使用全量特征 ( 如交叉特征 ) 或部分特征必须是剪裁过的,即特征没被完全利用,存在一部分损失。这时,通过一个更大的teacher模型学习全量特征,再把学到的知识迁移到子模型,即弥补了上述的部分特征损失。
基于以上描述可知,粗排模块可以通过蒸馏的方式,补足双塔模型在结构和特征上的缺陷。接下来的问题就是如何找到一个合适的teacher模型?精排模型通常是一个被充分训练的、参数量很大、表达能力很强的模型,如果通过蒸馏精排模型获取粗排模型,那么目标的一致性和学习能力的上限都符合我们的预期。具体操作方式如上图右侧所示:
左侧的teacher模型是精排模型,该模型使用全量的特征,包括三大类,即user侧特征、item侧特征及它们的交叉特征;虚线框里是一些复杂的网络拓扑结构;最后的softmax with temperature就是整个精排模型的输出内容,后续会给到粗排模型进行蒸馏。 中间的粗排模型,user tower只用user features,item tower只用item features,即整体上看,模型未使用交叉特征。在user tower和item tower交互后,加上精排模型传递过来的logits信息,共同构成了粗排模型的优化目标。整个粗排模型的优化目标,同时对真实样本和teacher信息进行了拟合。 右侧展示的是训练完粗排模型后,在线上产出user serving,通过user serving产出user embedding,再与item embedding做内积运算,完成整个排序的过程。上述流程即实现了粗排和精排的联动过程,并且训练完粗排模型就可以进行一个非常高效的serving,进行粗排排序。业界也有相关的一些工作,上图最下方给出了一篇阿里在这方面的论文。
实践中,粗排模型训练时,依赖的精排输出结果来自上报精排日志。如果在离线重新对样本进行预估再输出,其实是对线下资源的浪费,所以通常在线上精排预估时,就把一些结果作为日志进行上报。以我个人的猜测,这里精排日志应该是精排模型最后一层或倒数第二层的输出结果,通常是logits或softmax形式的soft labels,比如是否点击,那soft labels就是,表示点击的概率,表示不点击的概率;是否完播,那soft labels就是,表示完播的概率,表示不完播的概率。粗排模型异步训练,产出模型提供给Serving。
最后,全民K歌推荐算法团队给出了知识蒸馏的进一步优化方向:
首先,上述粗排蒸馏过程本质上是pointwise,但通过上报精排日志可以拿到精排模型给出的完整推荐列表,用pairwise学习精排排出来的序,可以进一步逼近精排结果,能更多的提取精排传递出的信息。 其次,前面虽然不断地用teacher模型和student模型描述整个过程,但实际效果上student模型不一定低于teacher模型。换一个角度,student模型其实是基于teacher模型做进一步训练,所以student模型的表征能力有可能超过teacher模型。事实上,如何让student模型通过反复的蒸馏,效果超过teacher模型,在模型蒸馏领域也有许多相关方法。
【相关文章】
腾讯音乐:全民K歌推荐系统架构及粗排设计,地址:https://mp.weixin.qq.com/s/Jfuc6x-Qt0rya5dbCR2uCA
3.2.2 爱奇艺短视频推荐之粗排模型蒸馏优化
这是一个将“目标蒸馏-logits方法“应用到推荐系统领域的实践。 粗排模型发挥的主要作用是统一计算和过滤召回结果,在尽量保证推荐准确性的前提下减轻精排模型的计算压力。这里主要介绍爱奇艺随刻基础推荐团队在短视频推荐业务的粗排模型优化上通过知识蒸馏技术提升链路目标的一致性。
爱奇艺团队也是选择了目前主流的双塔DNN模型作为粗排模型。用户侧和Item侧分别构建三层全联接DNN模型,最后分别输出一个多维(512)的embedding向量,作为用户侧和视频侧的低维表征。粗排双塔DNN模型如下图所示:
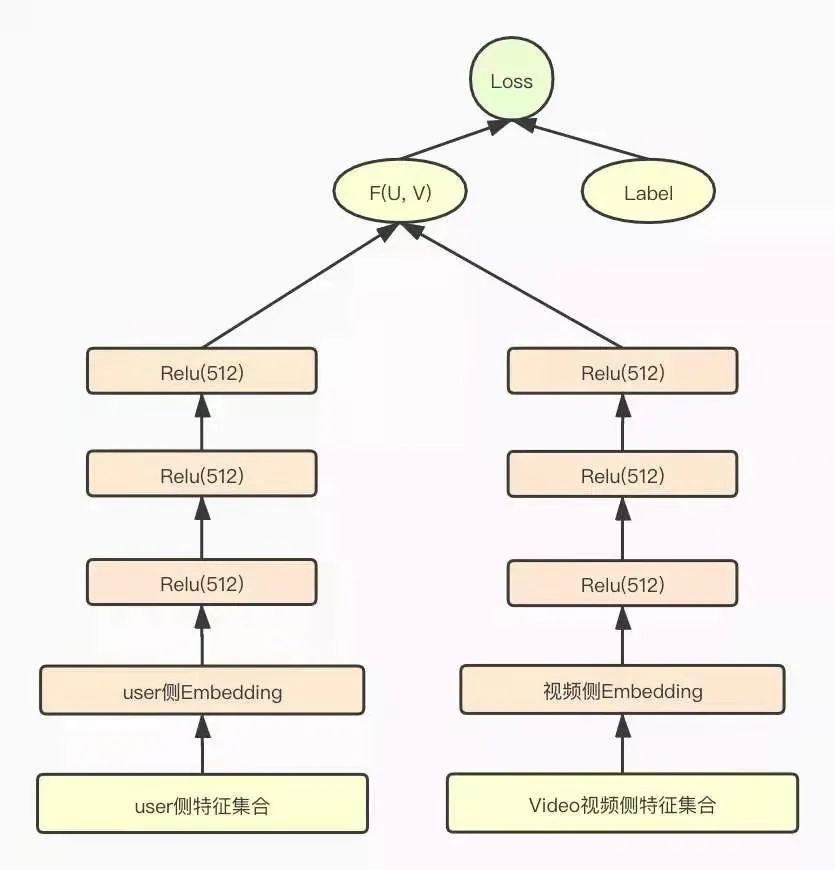
在构建粗排模型特征集合时,为了控制粗排模型参数的复杂度,他们对粗排的特征集合做了大量的裁剪,用户侧和视频侧都只采用了少部分精排模型的特征子集。
其中,用户侧特征主要选取了下面几维特征:
用户基础画像特征、上下文特征如手机系统、型号、地域等; 用户的历史行为特征,如用户观看的视频ID、up主ID,以及观看视频的关键词tag等,以及用户session内的行为特征等。
视频侧特征只保留了三维:视频ID、 up主ID、视频标签。
这里,我插入一些自己的想法。如果粗排模型是双塔DNN模型,精排模型为wide&deep模型,那么对粗排模型和精排模型的预估结果做详细的统计和分析,就会发现粗排模型预估为Top-K的头部视频和精排模型预估的头部视频有很大的差异。这也是目前工业界大多数推荐系统的弊端,归咎原因主要是以下两方面的原因:
特征集合的差异: 粗排层到精排层相当于是一个承上启下的作用,它会把我们召回到的一些万量级的视频进一步筛选到千量级,既要考虑打分的性能问题,又要考虑粗排精准度的问题。因此,粗排模型的特征只会采用少部分精排模型的特征子集。 模型结构的差异: 双塔DNN模型和精排模型(wide&deep、MMoE等模型)的优化和拟合数据时的侧重点还是有很大的差异的。
综合以上分析,为了尽量弥补粗排模型和精排模型的Gap,缩小粗排模型和精排模型预估结果的差异性;为了弥补特征裁剪带来的损失,保证裁剪后粗排模型的精度;且粗排从GBDT升级为双塔DNN模型,使得复杂度和参数量级有了爆炸性增长,为了不损失粗排模型的精度同时满足上线的性能指标要求,我们在训练粗排模型时,采用了模型压缩常用的方法-知识蒸馏来训练粗排模型。
知识蒸馏是一种模型压缩常见方法,在teacher-student框架中,将复杂、学习能力强的网络学到的特征表示“知识蒸馏”出来,传递给参数量小、学习能力弱的网络。从而我们会得到一个速度快,能力强的网络。将粗排模型和精排模型放到知识蒸馏的teacher-student框架中,以蒸馏训练的方式来训练粗排模型,以精排模型为teacher来指导粗排模型的训练,从而得到一个结构简单,参数量小,但表达力不弱的粗排模型,蒸馏训练示意图如下图所示:
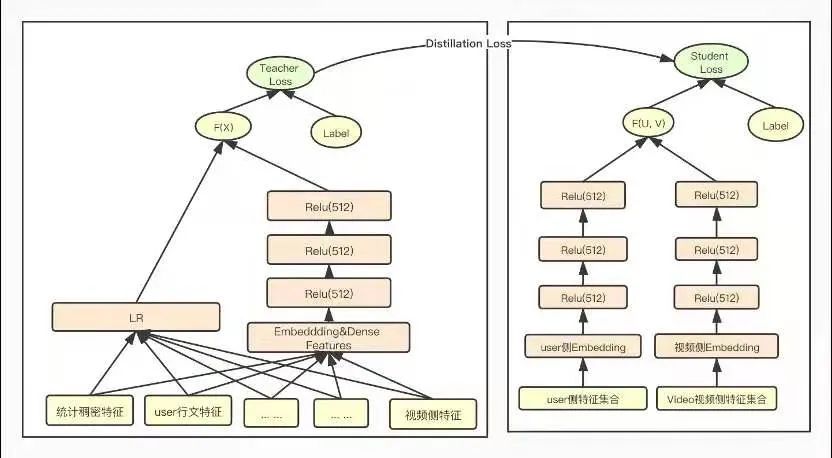
在蒸馏训练的过程中,为了使粗排模型输出的logits和精排模型输出的logits分布尽量对齐,训练优化的目标从原来单一的粗排模型的logloss调整为如下式所示的三部分loss的加和,包括student loss(粗排模型loss)、蒸馏loss 和teacher loss(精排模型loss)三部分组成。
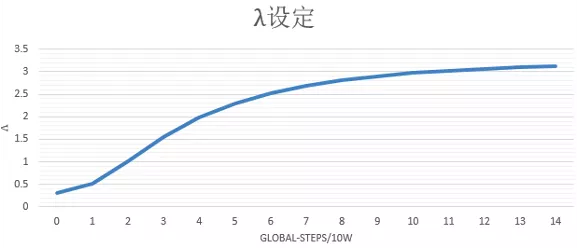
其中蒸馏loss,我们线上采用的是粗排模型输出和精排模型输出的最小平方误差,为了调节蒸馏loss的影响,我们在该项loss前又加了一维超参lamda,我们设置超参lamda随着训练步数迭代逐渐增大,增强蒸馏loss的影响,在训练后期使得粗排模型预估值尽量向精排模型对齐,lamda随着训练step的变化趋势如下图所示:
【相关文章】
如何提升链路目标一致性?爱奇艺短视频推荐之粗排模型优化历程,地址:https://mp.weixin.qq.com/s/LZlskUK4dmOd5fLTZIATnQ
4. 总结
从整个推荐系统的工作流程和业界的实践来看,在精排和粗排中,知识蒸馏的效果已经得到了验证。但是在召回中,还鲜有提及。如何打破推荐不同环节之间的信息壁垒,提升推荐系统的整个链路目标一致性,知识蒸馏在这方面是有价值的。
时间已经来到了2021年,推荐系统中的模型知识蒸馏技术,已经得到了工业界的广泛使用。但是,在互联网的浪潮下,深度学在CTR预估问题上又有了许多新的发展,比如使用新的特征交互方式、CTR模型统一的benchmark、用户行为序列建模和用户的多兴趣建模、多任务学习、CTR模型的增量训练、CTR模型debias、多模态学习与对抗、跨域迁移CTR建模、隐式反馈数据建模、NAS在CTR上应用等。在推荐领域中,这些新的技术和方向层出不穷,我们需要及时的follow业界前沿知识,才能不断的成长,变得更强~
5. Reference
【1】推荐系统技术演进趋势:从召回到排序再到重排 - 张俊林的文章 - 知乎 https://zhuanlan.zhihu.com/p/100019681
【2】知识蒸馏在推荐系统的应用 - 张俊林的文章 - 知乎 https://zhuanlan.zhihu.com/p/143155437
【3】知识蒸馏与推荐系统 - 凉爽的安迪的文章 - 知乎 https://zhuanlan.zhihu.com/p/163477538
【4】火箭发射:阿里巴巴的轻量网络训练方法,地址:https://github.com/Captain1986/CaptainBlackboard/blob/master/D%230034-%E7%81%AB%E7%AE%AD%E5%8F%91%E5%B0%84%EF%BC%9A%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4%E7%9A%84%E8%BD%BB%E9%87%8F%E7%BD%91%E7%BB%9C%E8%AE%AD%E7%BB%83%E6%96%B9%E6%B3%95/D%230034.md
【5】火箭发射:点击率预估界的“神算子”是如何炼成的?,地址:https://mp.weixin.qq.com/s/_qZNxBDUwXZVj4hGpV6ilA
【6】KDD 2020 | 优势特征蒸馏在淘宝推荐中的应用,地址:https://mp.weixin.qq.com/s/3zpri6pfVtp-3-5_004B1Q
【7】RS Meet DL(62)-[阿里]电商推荐中的特殊特征蒸馏,地址:https://mp.weixin.qq.com/s/W309FtLGTjj6y1hFwdueHQ
【8】优势特征蒸馏(Privileged Features Distillation)在手淘信息流推荐中的应用 | KDD论文解读,地址:https://developer.aliyun.com/article/768970
【9】推荐系统遇上深度学习(九十九)-[华为]多教师网络知识蒸馏来提升点击率预估效果,地址:https://mp.weixin.qq.com/s/09O4Izf8_752db45FJ3znQ
【10】AI筑巢:机器学习在百度凤巢的深度应用。https://myslide.cn/slides/763
【11】双DNN排序模型:在线知识蒸馏在爱奇艺推荐的实践,地址:https://mp.weixin.qq.com/s/ZNjC30F28uX2lBkHBAAU3g
【12】腾讯音乐:全民K歌推荐系统架构及粗排设计,地址:https://mp.weixin.qq.com/s/Jfuc6x-Qt0rya5dbCR2uCA
【13】如何提升链路目标一致性?爱奇艺短视频推荐之粗排模型优化历程,地址:https://mp.weixin.qq.com/s/LZlskUK4dmOd5fLTZIATnQ
【14】笔记︱模型压缩:knowledge distillation知识蒸馏(一),地址:https://mp.weixin.qq.com/s/u82_7jYvfHXQaGMM_UQFBw
【15】2020年精排模型调研 - Ruhjkg的文章 - 知乎 https://zhuanlan.zhihu.com/p/335781101
【16】DSSM在召回和粗排的应用举例 - arachis的文章 - 知乎 https://zhuanlan.zhihu.com/p/350206643
【17】Instagram 推荐系统:每秒预测 9000 万个模型是怎么做到的?地址:https://mp.weixin.qq.com/s/xJ9DNxamcYAQEzaYkoSNwA
往期精彩回顾
本站qq群851320808,加入微信群请扫码: