
多模态模型GILL:生成+理解,CMU华人博士新作
【新智元导读】CMU全新多模态模型GILL,能够生成图像、检索图像,还能进行多模态对话。

演示

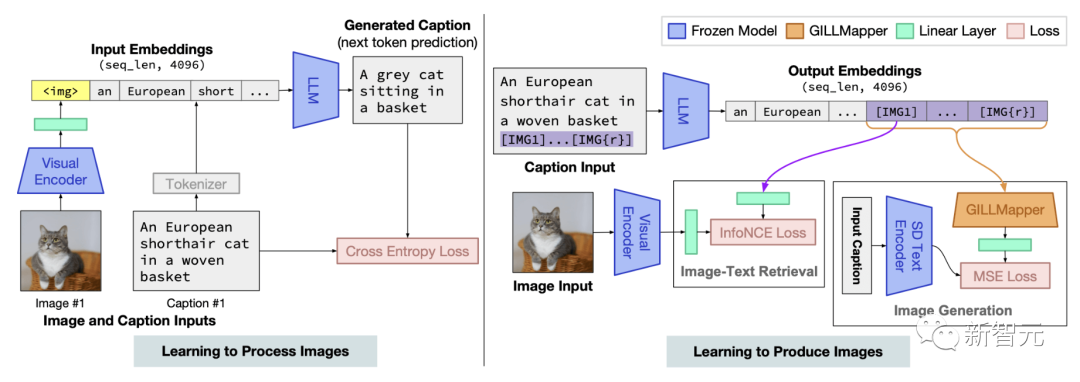
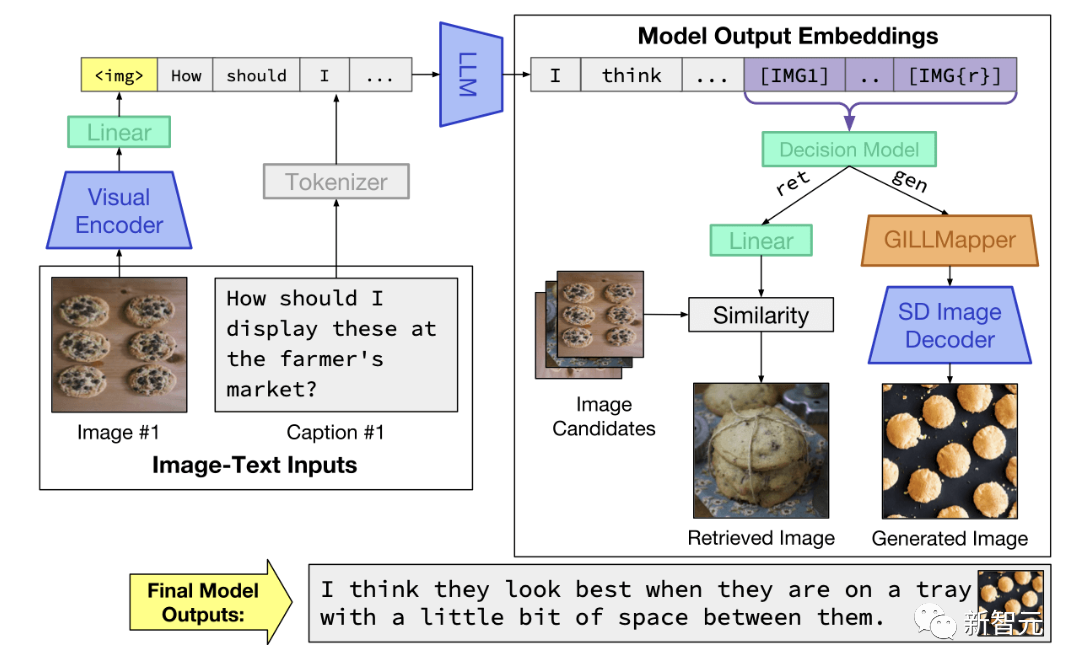
多模态大模型GILL
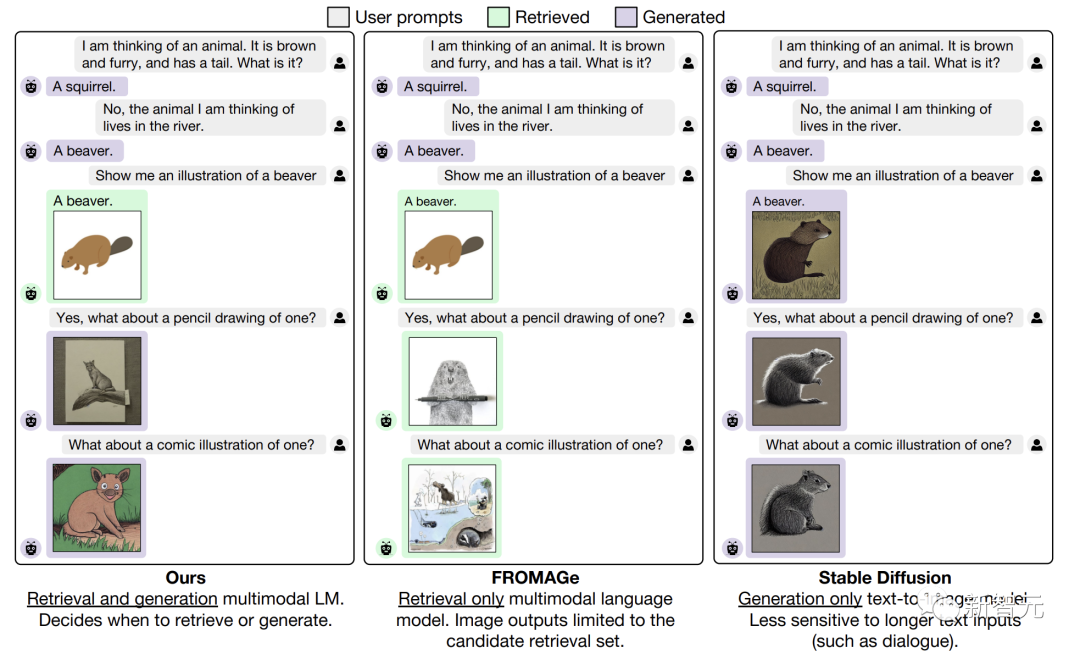
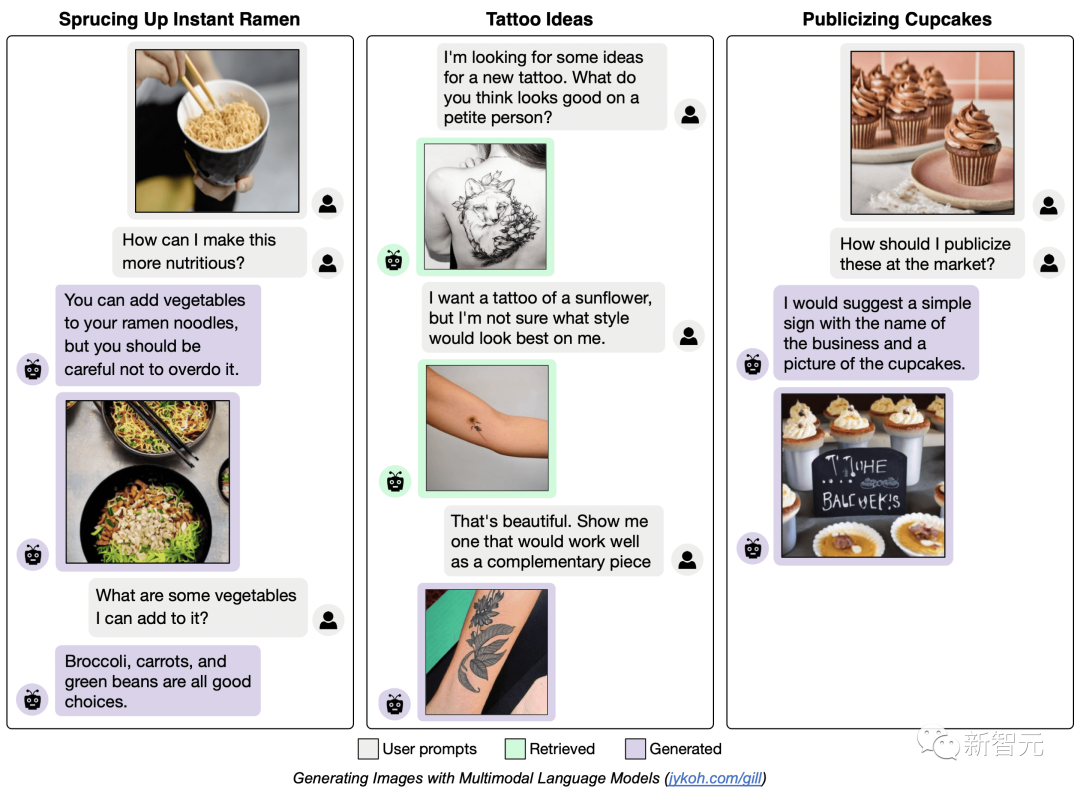
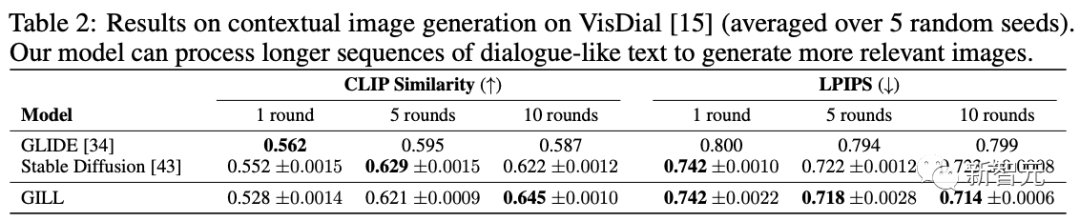
实验结果



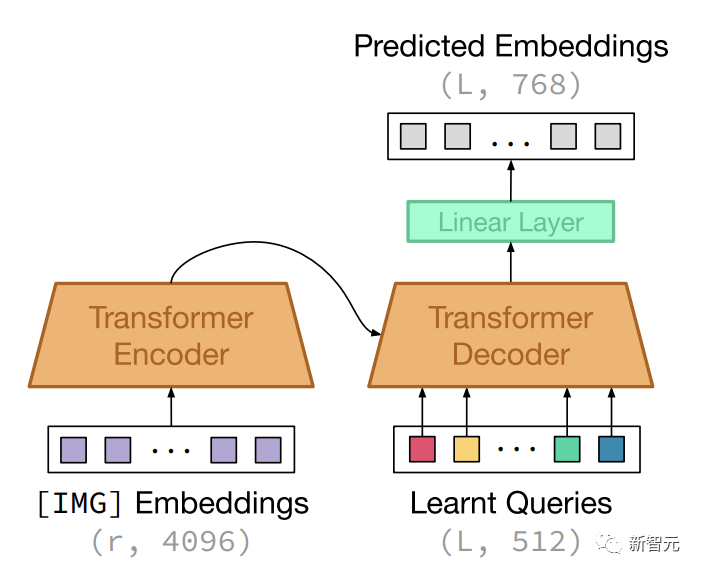
作者介绍

https://www.cxs.cmu.edu/news/2023/gill
https://jykoh.com/gill
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!,加入 AI生成创作与计算机视觉 知识星球!
评论