
图像匹配还用SIFT?来看看 CVPR 2021 比赛中的冠军方案
本文转自旷视研究院。



滑动查看更多图片
一、比赛介绍



Stereo:通过两张图片进行匹配,然后解算F矩阵,求解实际的位姿误差。 Multiview:选取少部分图片组成一个bags,通过bags进行建图,通过3d模型求解不同图片之间的位姿误差。

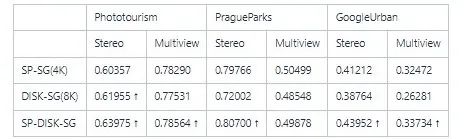
内点数量(越高越好) 匹配成功率,即匹配内点数量/所有提供的匹配对(越高越好) 负匹配对数量,当两张图片没有共视区域时,匹配对应该越少越好
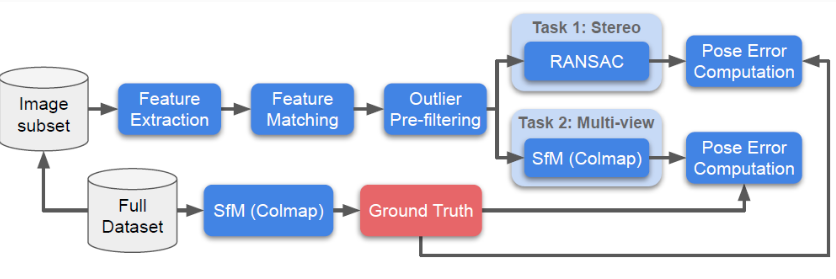
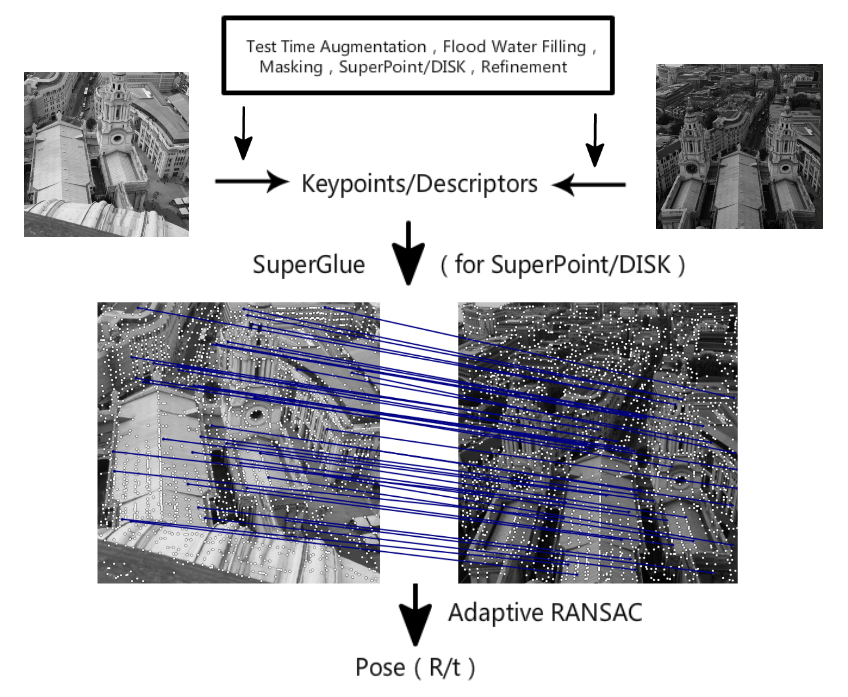
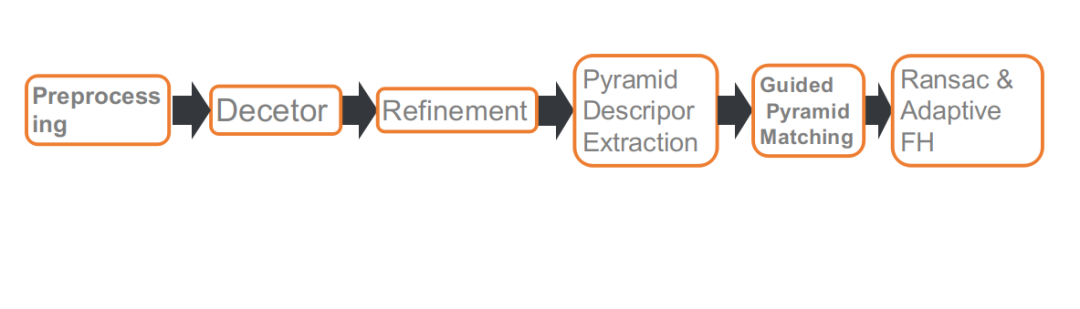
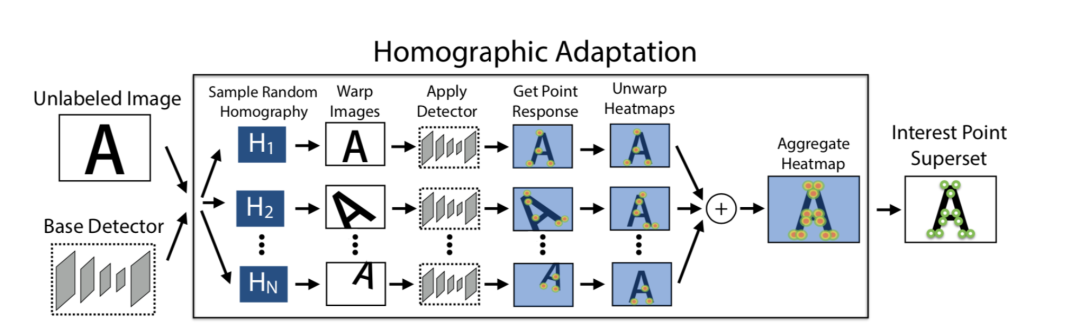
二、比赛方案
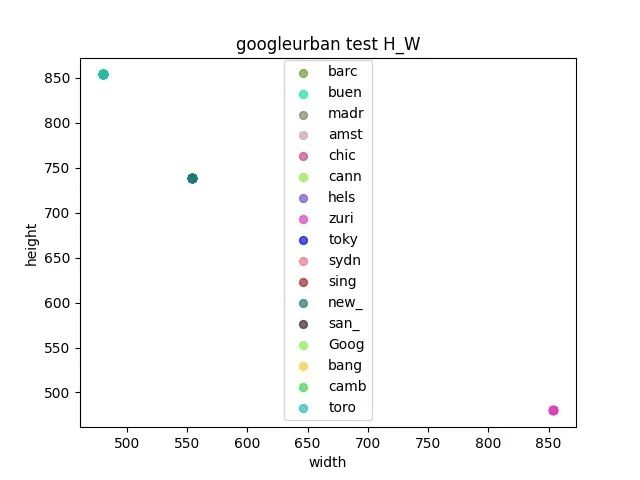
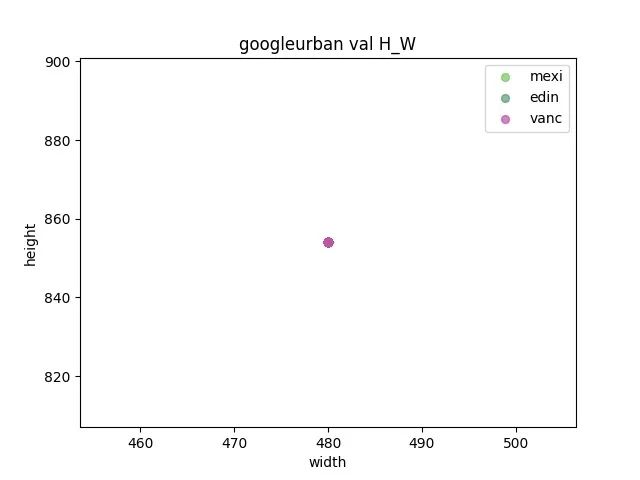
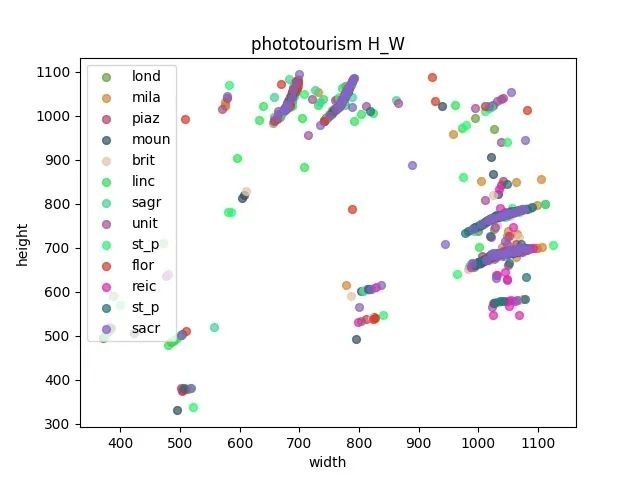
观察验证集和测试集之间是否存在gap 通过统计各个数据集之间的长宽,来确定resize的大小


一个是由于分割网络的精确度不高,并不能很好的区分建筑物和天空连接区域,就会存在把建筑物边缘轻微破坏的情况,这样不利于匹配。所以我们 mask 动态物体之后,对 mask 区域做了腐蚀处理,这样可以把建筑物的边缘细节保留下来。 另外一个问题则是分割网络算法针对真人和雕塑的泛化能力不是很好,当 mask 行人的时候,雕塑也会被 mask。而部分场景例如林肯数据集,雕塑上面的特征点对匹配结果比较重要。针对这个情况,我们训练了一个分类网络用来区分雕塑和行人,这样既可以去掉行人又可以保留雕塑。



滑动查看更多图片
尺度差距比较大 大角度旋转



滑动查看更多图片


三、方案应用:AR 导航
四、未来展望
在训练的时候可以加上强化学习,重新训练整个 pipeline。 增强 DISK 的泛化能力,使用更多的数据集进行训练。 使用 Refinements 网络,进行对特征点的位置 refine。
五、参考文献
END
评论