
CVPR 2021 顶会冠军带你解密图像分割
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达


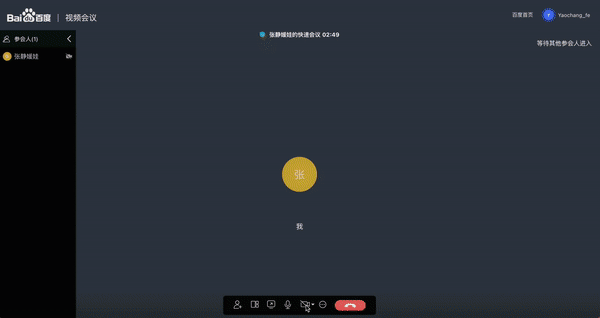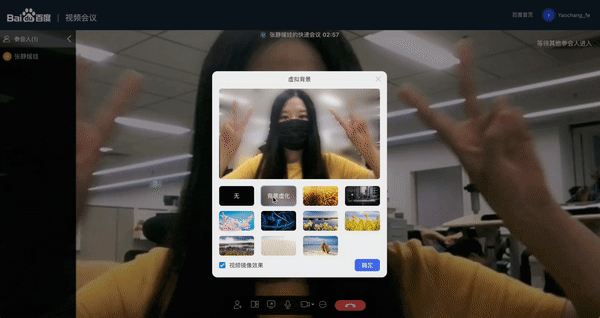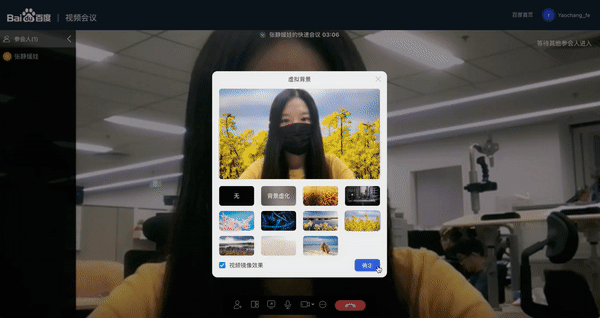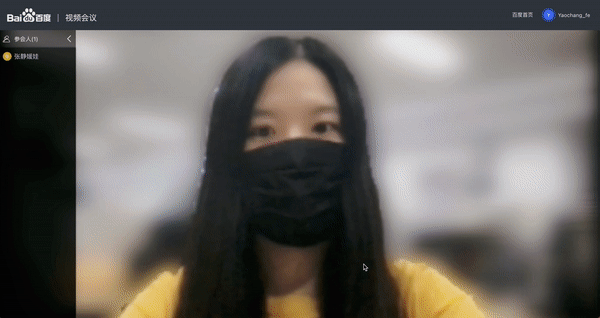
全新升级了人像分割功能,提供了 web 端超轻量模型部署方案;
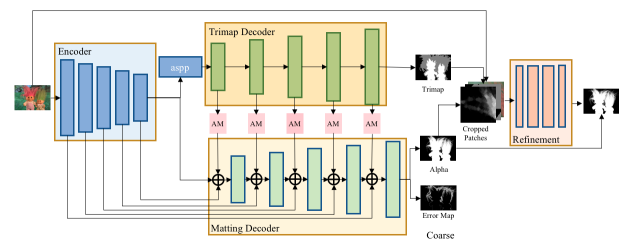
推出了精细化的分割解决方案 PaddleSeg-Matting;
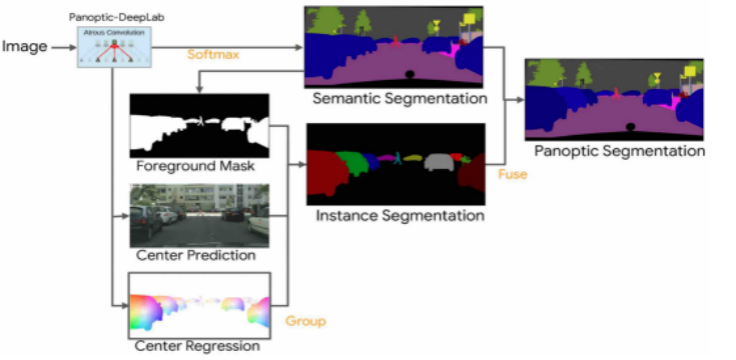
开源了全景分割算法 Panoptic-DeepLab,丰富了模型种类;
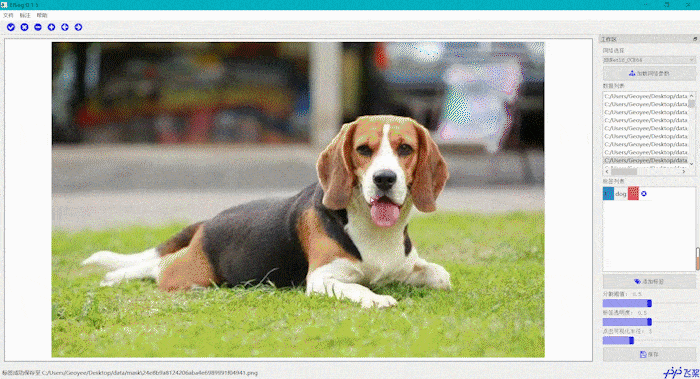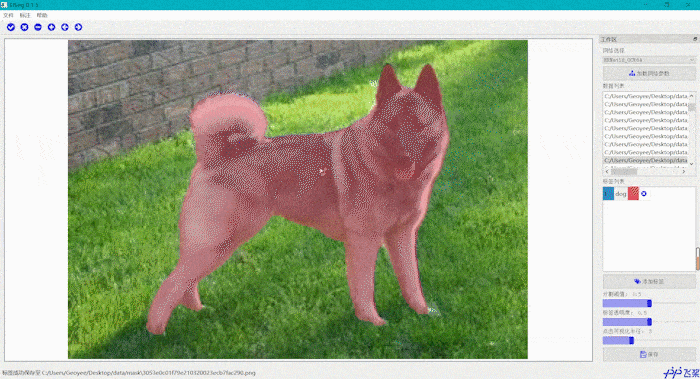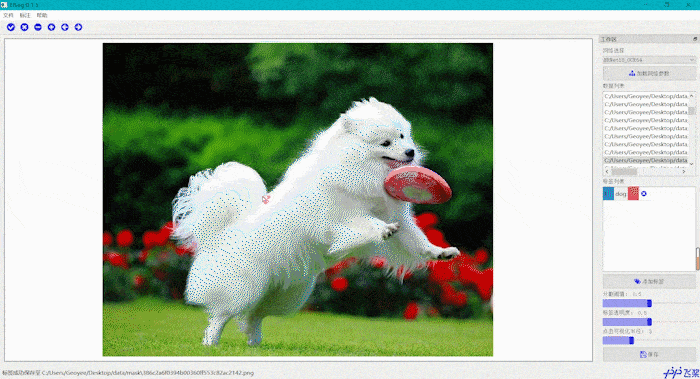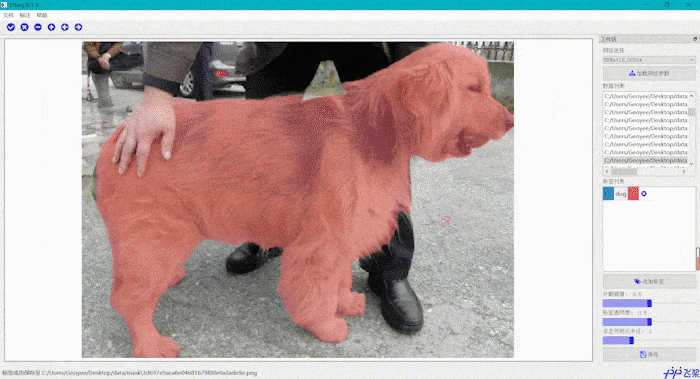
发布了交互式分割的智能标注工具 EISeg。极大的提升了标注效率。

Web 视频会议

Matting
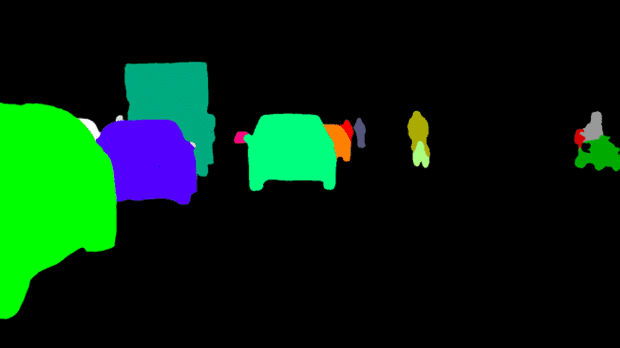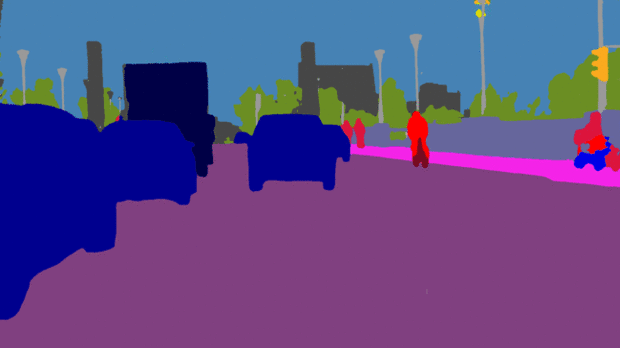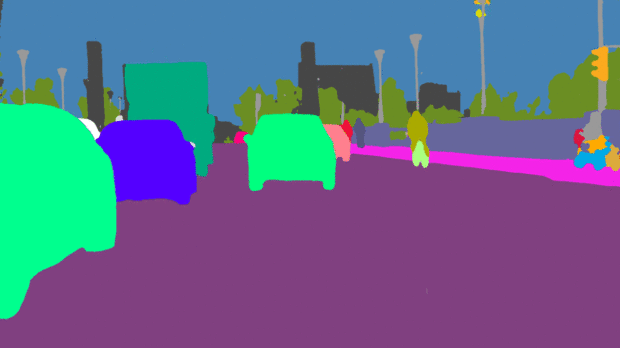
全景分割
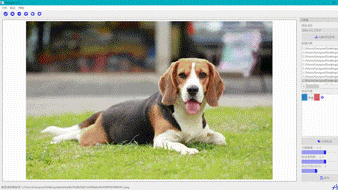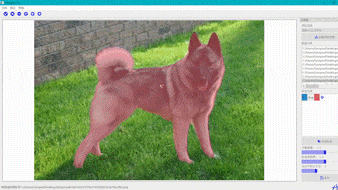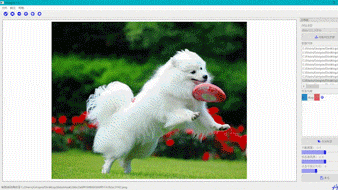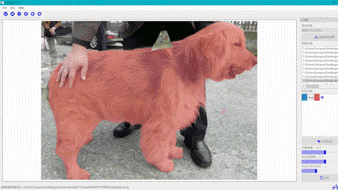
交互式分割

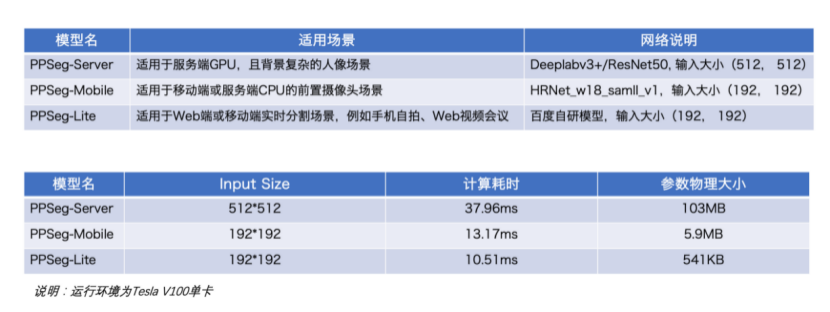
产业级人像分割方案PPSeg
精细化的分割解决方案 PaddleSeg-Matting

交互式分割智能标注工具


什么是全景分割呢?

全明星算法阵容
全产业链部署
精彩课程抢先看
评论