
中药说明书实体识别
共 3284字,需浏览 7分钟
·
2021-03-15 03:43

向AI转型的程序员都关注了这个号👇👇👇
人工智能大数据与深度学习 公众号:datayx
人工智能加速了中医药领域的传承创新发展,其中中医药文本的信息抽取部分是构建中医药知识图谱的核心部分,为上层应用如临床辅助诊疗系统的构建(CDSS)等奠定了基础。本次NER挑战需要抽取中药药品说明书中的关键信息,包括药品、药物成分、疾病、症状、证候等13类实体,构建中医药药品知识库。
代码 获取方式:
分享本文到朋友圈
关注微信公众号 datayx 然后回复 实体识别 即可获取。
AI项目体验地址 https://loveai.tech
数据探索分析
本次竞赛训练数据有三个特点:
中药药品说明书以长文本居多
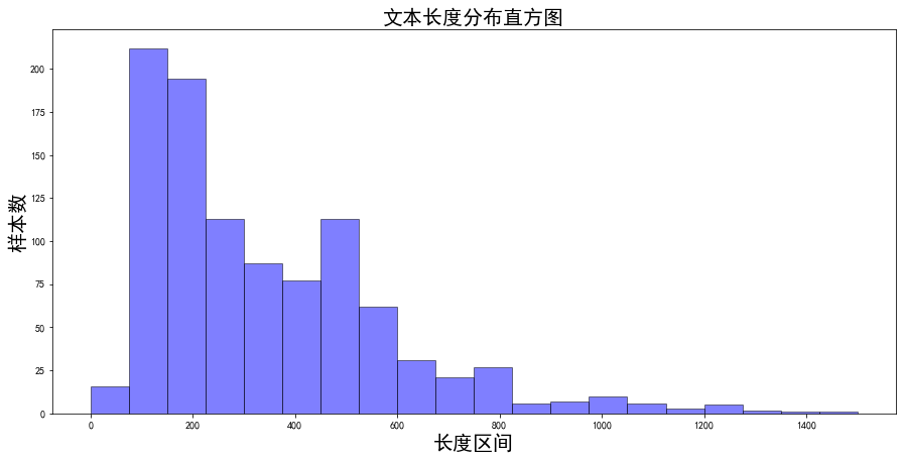
医疗场景下的标注样本不足
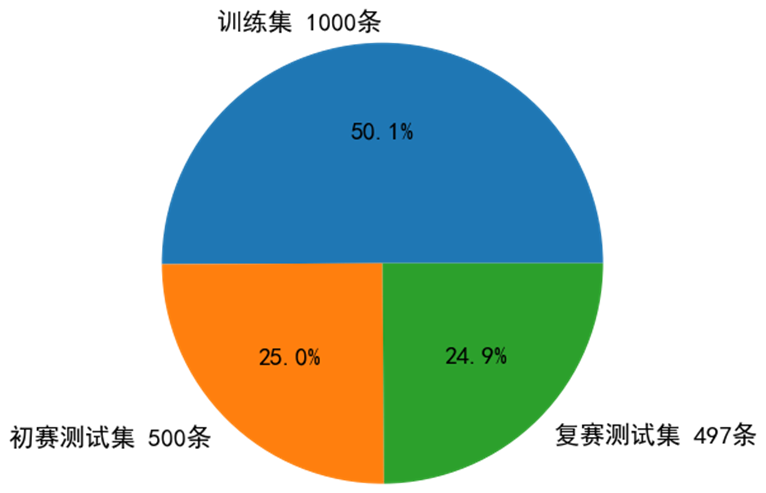
标签分布不平衡

核心思路
数据预处理
首先对说明书文本进行预清洗与长文本切分。预清洗部分对无效字符进行过滤。针对长文本问题,采用两级文本切分的策略。切分后的句子可能过短,将短文本归并,使得归并后的文本长度不超过设置的最大长度。此外,利用全部标注数据构造实体知识库,作为领域先验词典。
Baseline: BERT-CRF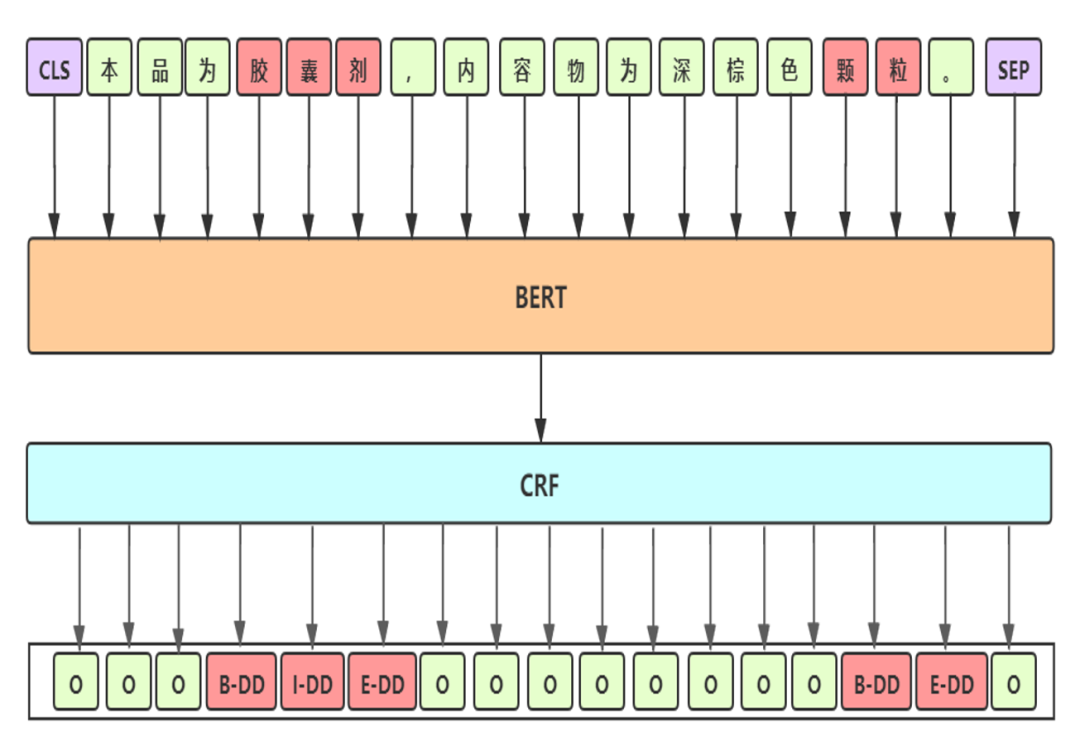
Baseline 细节
预训练模型:选用 UER-large-24 layer[1],UER在RoBerta-wwm 框架下采用大规模优质中文语料继续训练,CLUE 任务中单模第一
差分学习率:BERT层学习率2e-5;其他层学习率2e-3
参数初始化:模型其他模块与BERT采用相同的初始化方式
滑动参数平均:加权平均最后几个epoch模型的权重,得到更加平滑和表现更优的模型
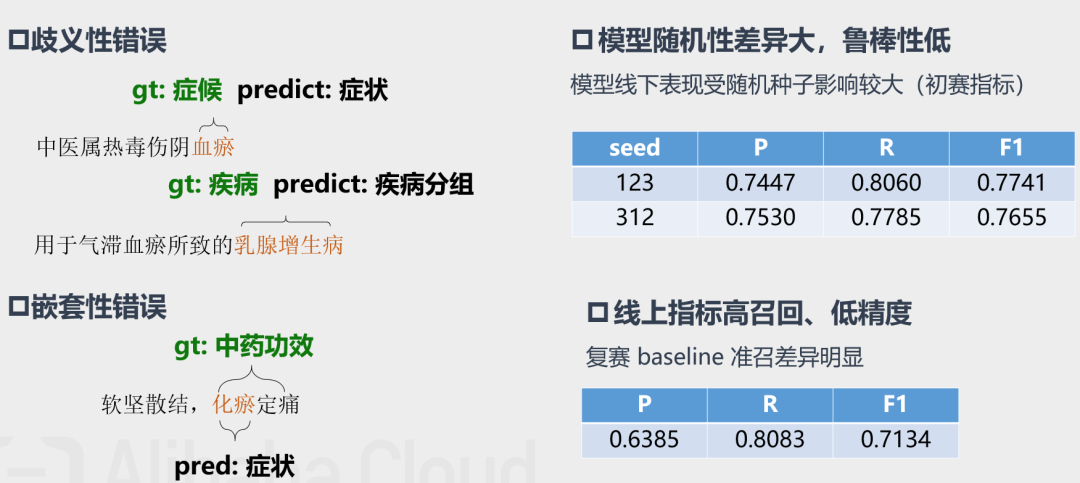
Baseline bad-case分析
优化1:对抗训练
动机:采用对抗训练缓解模型鲁棒性差的问题,提升模型泛化能力
对抗训练是一种引入噪声的训练方式,可以对参数进行正则化,提升模型鲁棒性和泛化能力
Fast Gradient Method (FGM):对embedding层在梯度方向添加扰动
Projected Gradient Descent (PGD) [2]:迭代扰动,每次扰动被投影到规定范围内
优化2:混合精度训练(FP16)
动机:对抗训练降低了计算效率,使用混合精度训练优化训练耗时
混合精度训练
在内存中用FP16做存储和乘法来加速
用FP32做累加避免舍入误差
损失放大
反向传播前扩大2^k倍loss,防止loss下溢出
反向传播后将权重梯度还原
优化3:多模型融合
动机:baseline 错误集中于歧义性错误,采用多级医学命名实体识别系统以消除歧义性
方法:差异化多级模型融合系统
模型框架差异化:BERT-CRF & BERT-SPAN & BERT-MRC
训练数据差异化:更换随机种子、更换句子切分长度(256、512)
多级模型融合策略
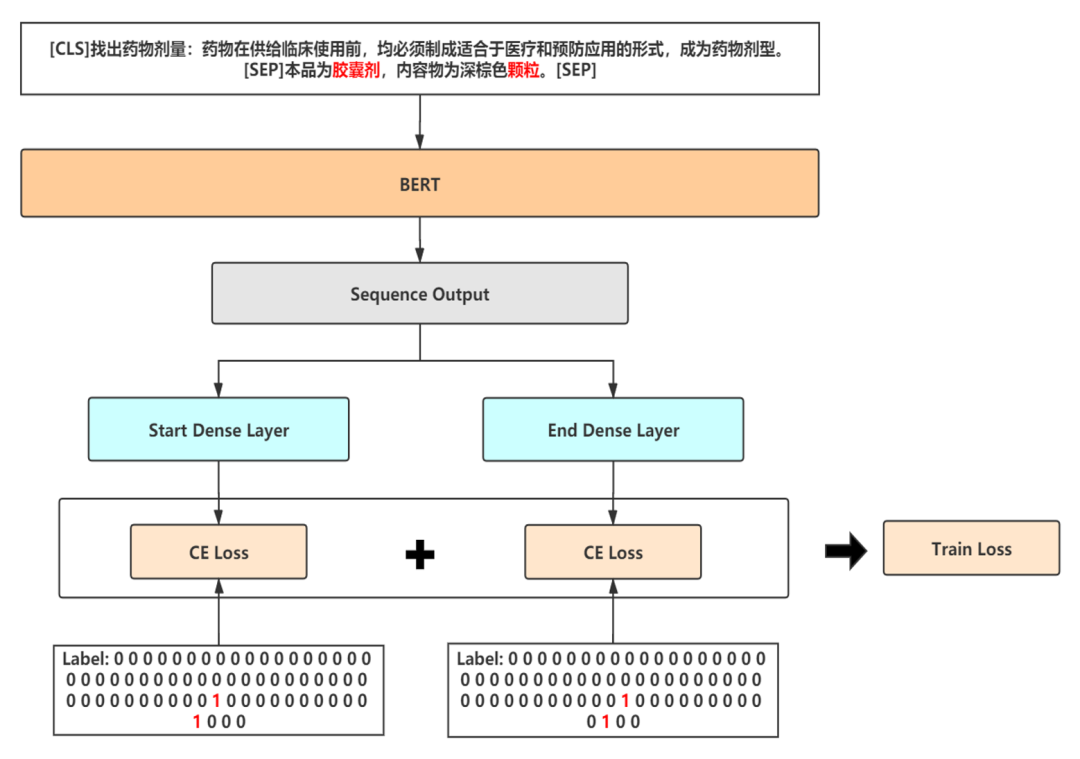
融合模型1——BERT-SPAN
采用SPAN指针的形式替代CRF模块,加快训练速度
以半指针-半标注的结构预测实体的起始位置,同时标注过程中给出实体类别
采用严格解码形式,重叠实体选取logits最大的一个,保证准确率
使用label smooth缓解过拟合问题
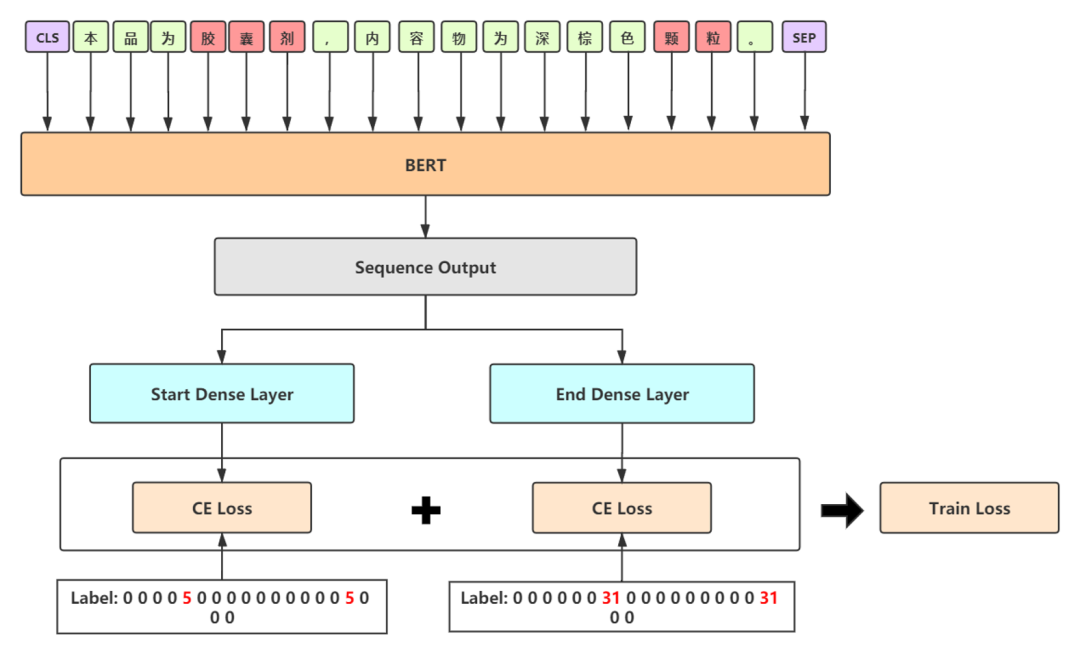
融合模型2——BERT-MRC
query:实体类型的描述来作为query
doc:分句后的原始文本作为doc
基于阅读理解的方式处理NER任务
针对每一种类型构造一个样本,训练时有大量负样本,可以随机选取30%加入训练,其余丢弃,保证效率
预测时对每一类都需构造一次样本,对解码输出不做限制,保证召回率
使用label smooth缓解过拟合问题
MRC在本次数据集上精度表现不佳,且训练和推理效率较低,仅作为提升召回率的方案
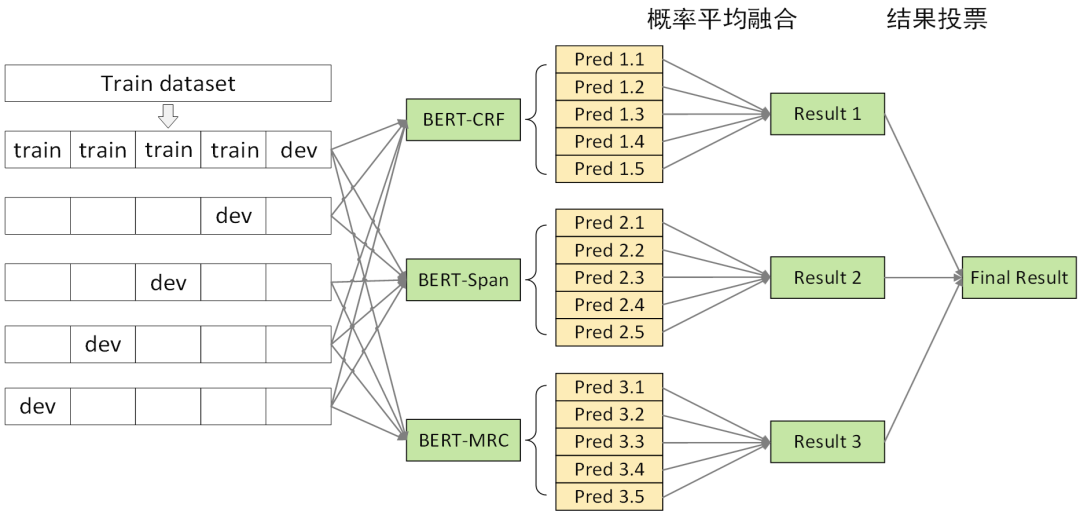
多级融合策略
CRF/SPAN/MRC 5折交叉验证得到的模型进行第一级概率融合,将 logits 平均后解码实体
CRF/SPAN/MRC 概率融合后的模型进行第二级投票融合,获取最终结果
优化4:半监督学习
动机:为了缓解医疗场景下的标注语料稀缺的问题, 我们使用半监督学习(伪标签)充分利用未标注的500条初赛测试集
策略:动态伪标签
首先使用原始标注数据训练一个基准模型M
使用基准模型M对初赛测试集进行预测得到伪标签
将伪标签加入训练集,赋予伪标签一个动态可学习权重(图中alpha),加入真实标签数据中共同训练得到模型M’
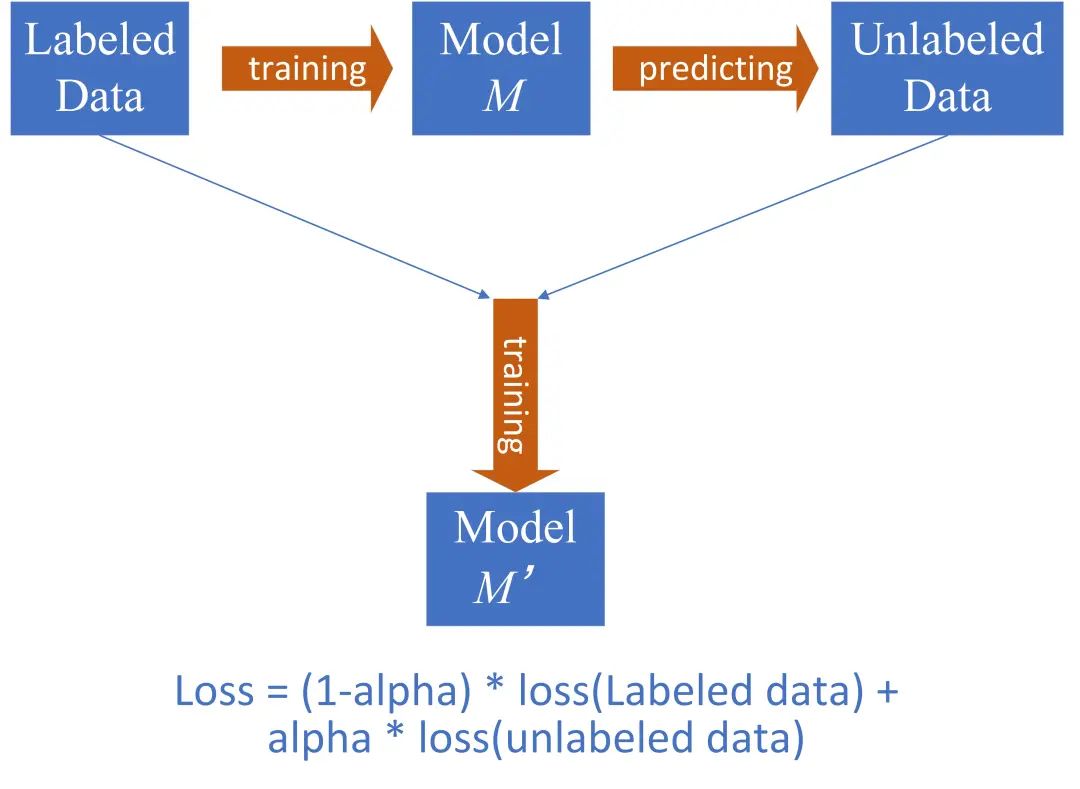
tips:使用多模融合的基准模型保证伪标签的准确率
其他无明显提升的尝试方案
取BERT后四层动态加权输出,无明显提升
BERT 输出后加上BiLSTM / DGCNN 模块,过拟合严重,训练速度大大降低
数据增强,对同类实体词进行随机替换,以扩充训练数据
BERT-SPAN / MRC 模型采用focal loss / dice loss 等缓解标签不平衡
利用构造的领域词典修正模型输出
最终线上成绩72.90%,复赛Rank 1,决赛Rank 1
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码