
大模型落地最后一公里:111页全面综述大模型评测
机器之心专栏
机器之心编辑部

-
论文地址:https://arxiv.org/abs/2310.19736 -
论文参考文献详细列表:https://github.com/tjunlp-lab/Awesome-LLMs-Evaluation-Papers
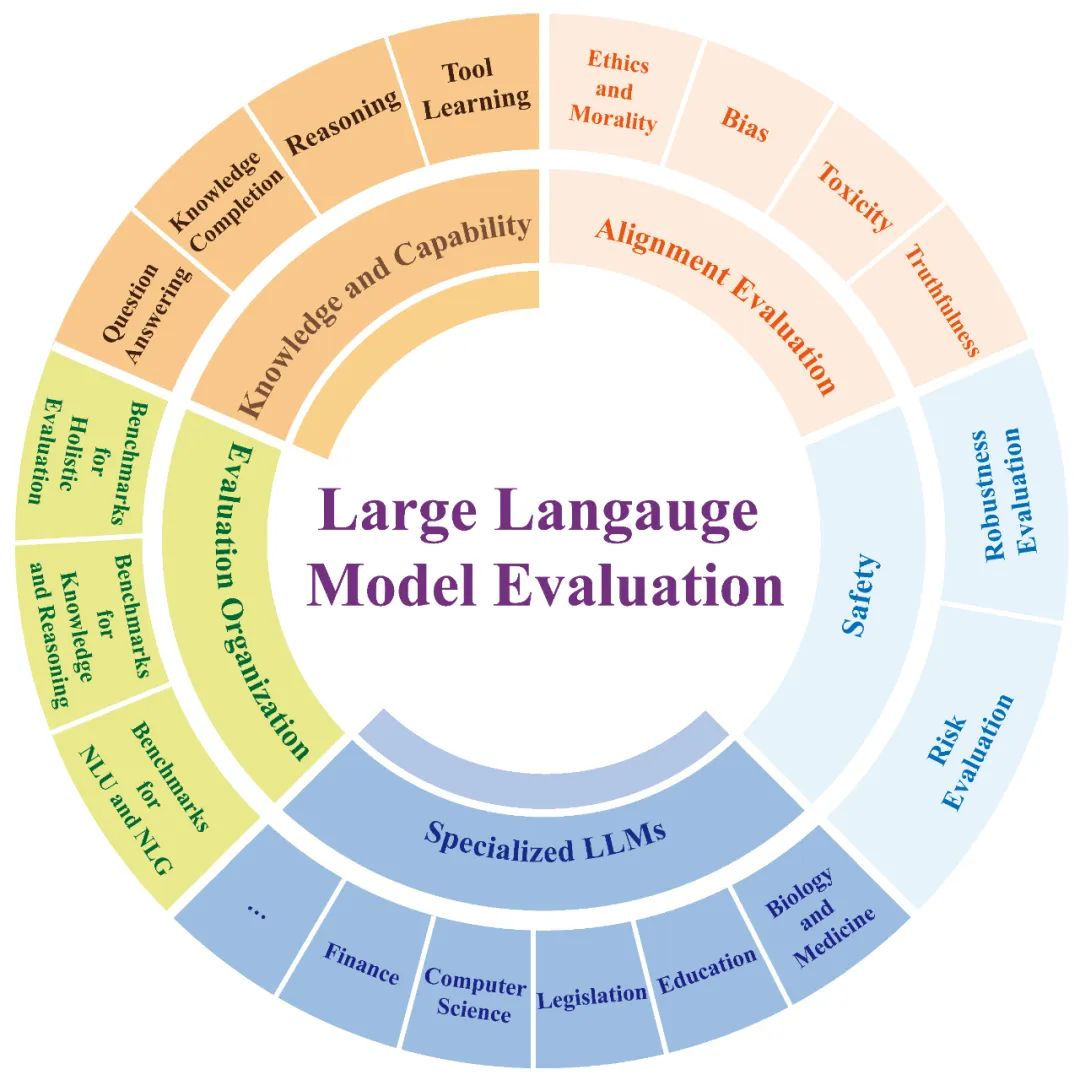
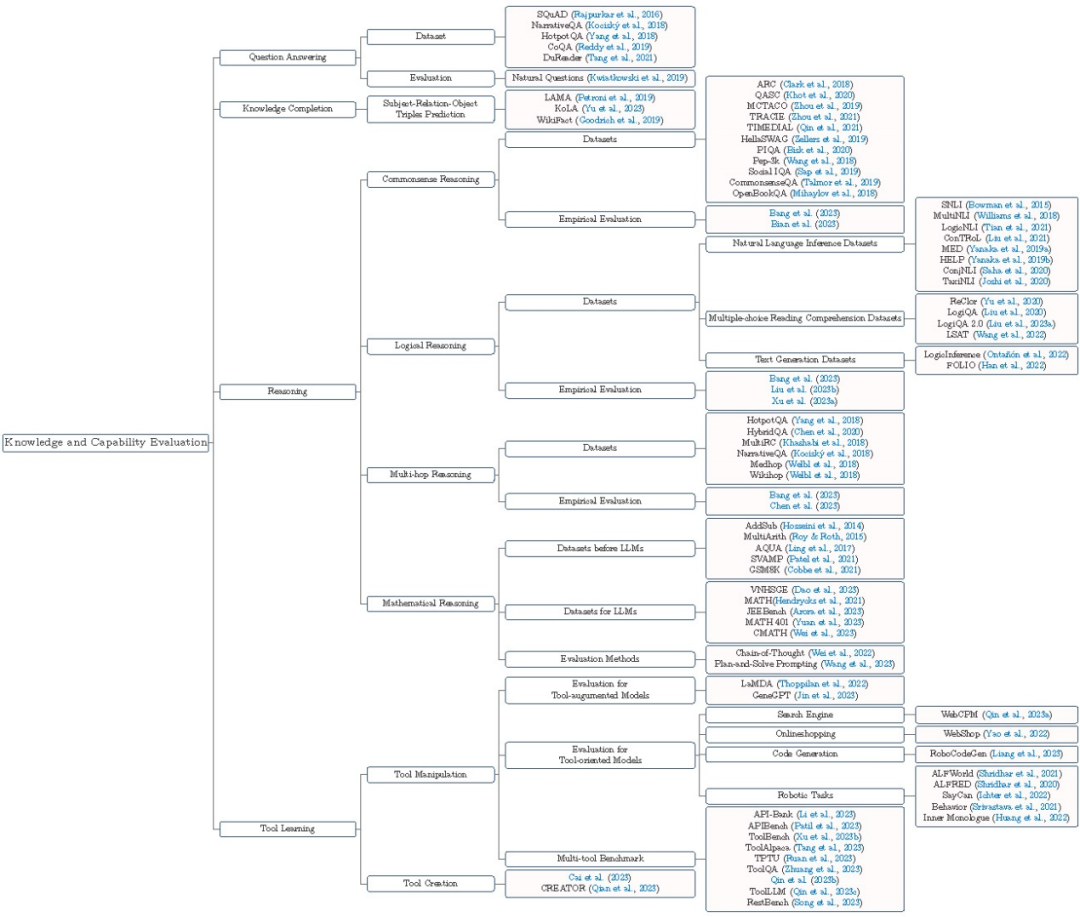
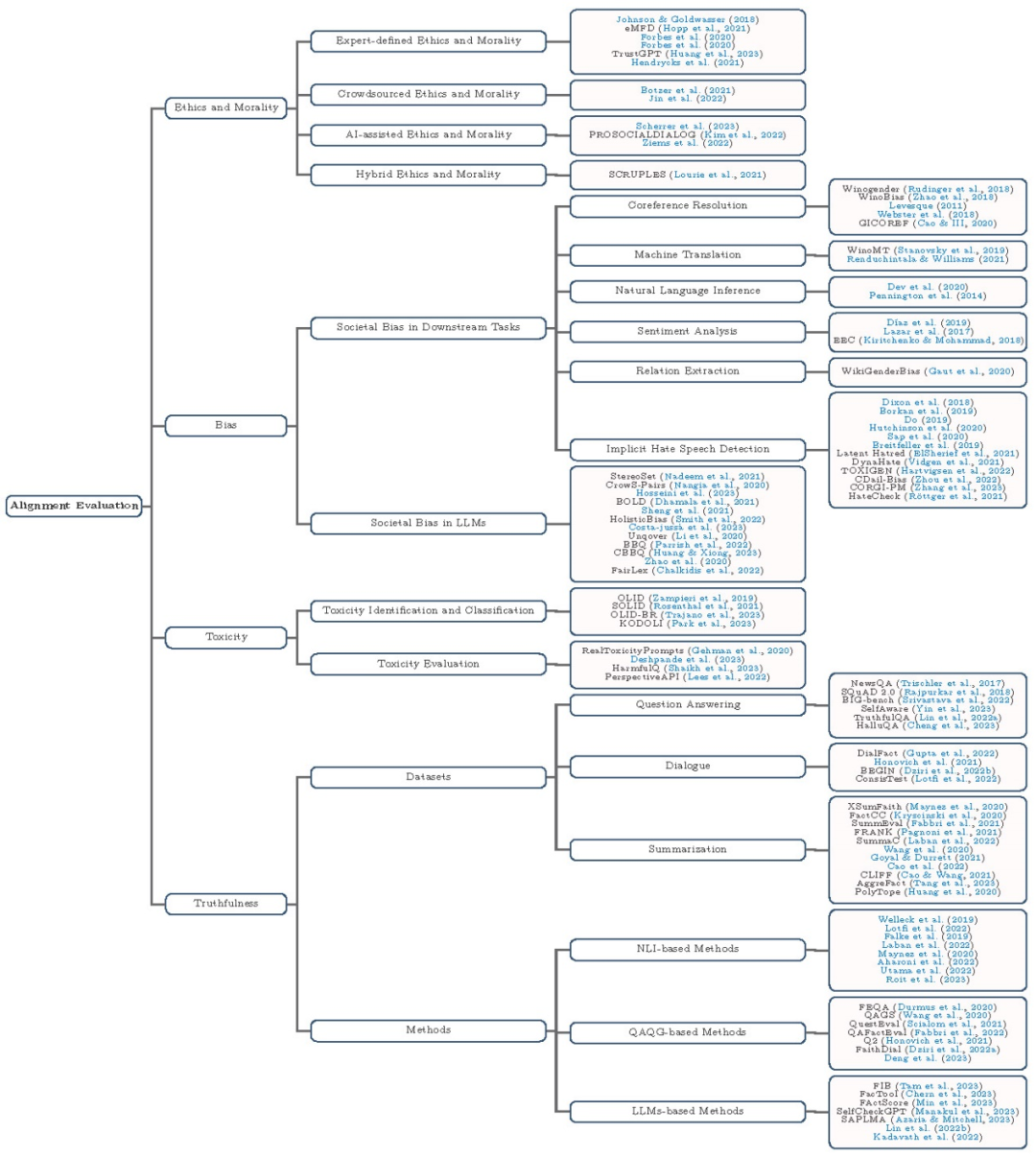
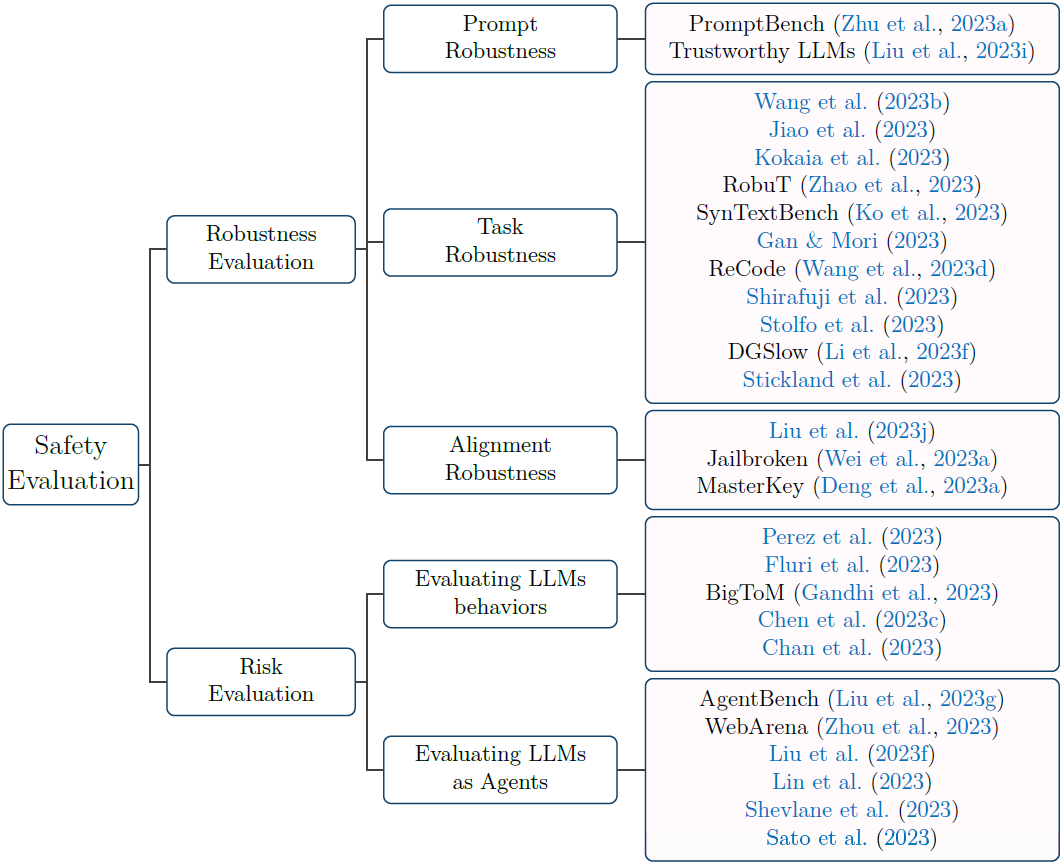
图 5 大模型安全评测
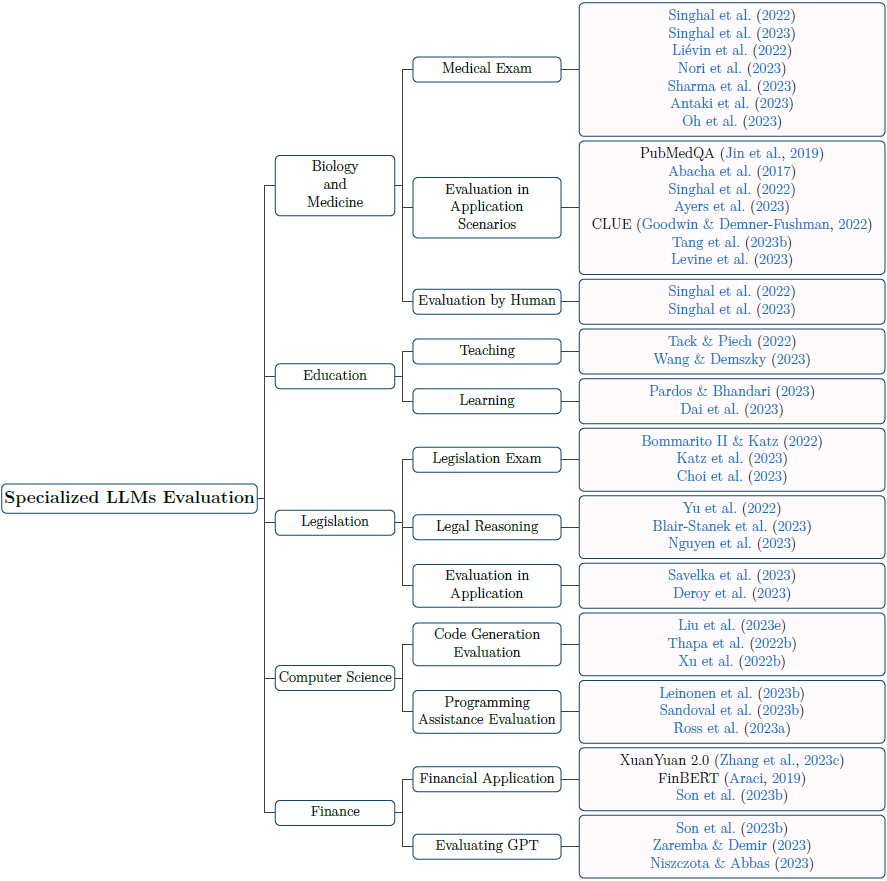
图 6 行业大模型评测
往期精彩回顾
交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)
评论