
keras实战系列之推荐系统FM(Factorization Machine)算法
共 3024字,需浏览 7分钟
·
2021-12-25 21:26
前言
博主在之前的文章中介绍过使用keras搭建一个基于矩阵分解的推荐系统,而那篇文章所介绍的方法可能只是一个庞大推荐系统中的一小环节。而对于工业级别的推荐系统,面对极其庞大的产品种类数量,一步就输出符合用户心意的产品可能够呛,最好的方式应该是从巨大的产品类别之中粗筛出一些靠谱的待推荐产品,然后再从粗筛的产品中精挑细选出要推荐给用户的最终产品。
工业级别的推荐系统简介
工业级别的推荐系统的架构图如下图所示,大致分为两个阶段:
召回阶段:也就是粗筛阶段,由于涉及到的产品数量巨大,大的公司都是千万级别,甚至上亿级别的产品数量,此阶段的模型应该尽量简单,特征维度也尽量少,这样方便快速筛选出一些待推荐的产品。
排序阶段:即对上一阶段粗筛出来的待推荐产品进行精挑细选,此阶段为了推荐出符合用户心意的产品,需要模型尽量的准确。而且由于粗筛阶段将数据量减少到几千,甚至几百级别,所以使用复杂模型,并且特征维度也可以尽量丰富,尽量多一些,这样训练出来的模型才能有较强的性能。
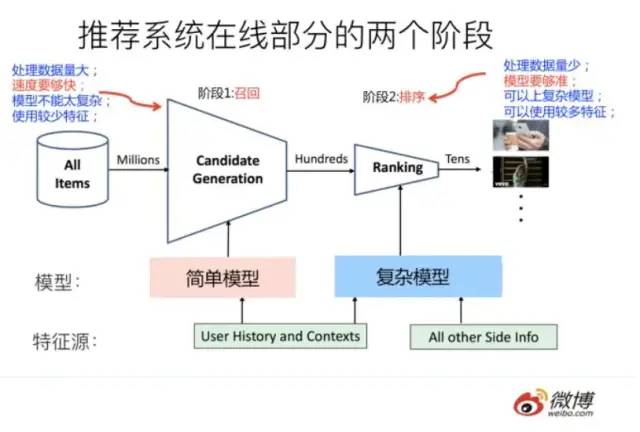
推荐系统的架构图
而接下来我要介绍的FM(Factorization Machine)算法,不仅在召回阶段有用武之地,在排序阶段也是很拿得出手的推荐模型。
FM(Factorization Machine)算法简介
Factorization Machine的中文叫因子分解机,FM算法的最强特点就是考虑到了特征的二阶组合——即特征两两组合形成一个新的特征。在产品推荐,CTR预估等任务中,特征相互组合很可能会得到一个特别强的新特征。接下来我们从FM算法的公式来了解一下此算法的精髓:
如果我们单看FM算法的前面一部分: ,这不就是一个Logistics回归模型吗,确实没错,FM算法的前半部分就是Logistics回归,算法的后半部分才体现出FM的特征组合的思想:
其中 可以理解成特征 和特征 的另外一种向量表示,
向量相乘得到的值则是特征 和特征 组合特征的权重,
Logistics回归 + 特征之间的两两组合,最后给每个两两组合而来的新特征乘上一个权重值,就实现了FM算法的特征的二阶组合的思想。
通过下图我们可以将FM算法的公式转化为:
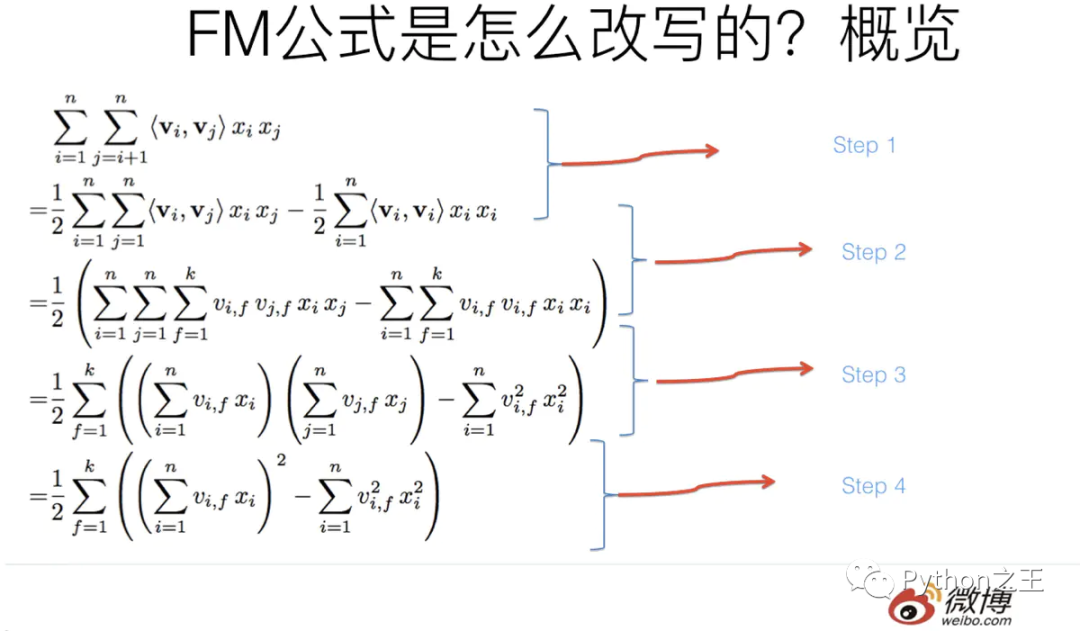
FM算法的改写
不要小看了公式的改写这一步,公式的改写这一过程会带来了算法时间复杂度的下降,加速算法的运行。接下来我们就尝试使用keras实现一下FM算法。
FM算法实战
导入python包
首先导入必要的python 包,导入 sklearn中乳腺癌的分类任务数据。
import keras
from keras.layers import Layer, Dense, Dropout,Input
from keras import Model,activations
from keras.optimizers import Adam
import keras.backend as K
from sklearn.datasets import load_breast_cancer
FM层的定义,其中call函数中定义了FM的主要实现部分。
class FM(Layer):
def __init__(self, output_dim=30, activation="relu",**kwargs):
self.output_dim = output_dim
self.activate = activations.get(activation)
super(FM, self).__init__(**kwargs)
def build(self, input_shape):
self.wight = self.add_weight(name='wight',
shape=(input_shape[1], self.output_dim),
initializer='glorot_uniform',
trainable=True)
self.bias = self.add_weight(name='bias',
shape=(self.output_dim,),
initializer='zeros',
trainable=True)
self.kernel = self.add_weight(name='kernel',
shape=(input_shape[1], self.output_dim),
initializer='glorot_uniform',
trainable=True)
super(FM, self).build(input_shape)
def call(self, x):
feature = K.dot(x,self.wight) + self.bias
a = K.pow(K.dot(x,self.kernel), 2)
b = K.dot(x, K.pow(self.kernel, 2))
cross = K.mean(a-b, 1, keepdims=True)*0.5
cross = K.repeat_elements(K.reshape(cross, (-1, 1)), self.output_dim, axis=-1)
return self.activate(feature + cross)
def compute_output_shape(self, input_shape):
return (input_shape[0], self.output_dim)
数据载入
载入sklearn中乳腺癌的分类任务数据。
data = load_breast_cancer()["data"]
target = load_breast_cancer()["target"]
模型构建
这里我采用了一层FM层,一层15个神经元的隐层构建了一个两层的网络模型,Loss 采用的是平方误差损失(mse),当然也可以采用交叉熵损失(cross entropy)。
K.clear_session()
inputs = Input(shape=(30,))
out = FM(20)(inputs)
out = Dense(15,activation="sigmoid")(out)
out = Dense(1,activation="sigmoid")(out)
model = Model(inputs=inputs, outputs=out)
model.compile(loss='mse',
optimizer=adam(0.0001),
metrics=['accuracy'])
model.summary()
模型训练
定义好batch_size 和训练轮数,就可以将模型跑起来了。
model.fit(data, target,
batch_size=1,
epochs=100,
validation_split=0.2)
下图训练的截图,由于数据集太小,太简单这里也没有对比FM和其他算法的性能差异,不过看网上的博客教程,FM在应对特征丰富的推荐任务时有着很不错的效果。毕竟考虑到了特征之间的组合关系。
模型训练