
如何理解 DAX 数据沿袭
数据沿袭,这个词汇,相当生僻,很多小伙伴都问这个什么意思,以及如何去使用他。那本文就来帮大家理解这个事物。
数据沿袭
数据沿袭(data lineage),表示数据的一种本质联系。
举一个例子,如下:
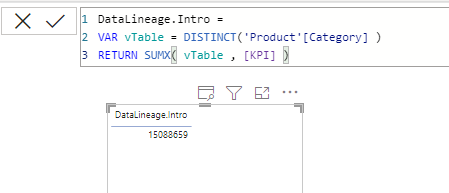
在 SUMX 进行计算的时候,问题来了:
vTable,是一个孤立的表吗?
vTable,是一个与原数据模型实际保持关联的表数据吗?
从 SUMX 的计算结果来看,这的确是总计结果。
这说明,在针对 vTable 进行计算时候,进行的上下文转换,的确由于筛选上下文对模型有实际的影响,这说明:
虽然 vTable 是通过 VAR 独立构建的,但它依然保持着在实际数据模型中的数据血缘关系。
进一步的案例
如果刚刚的案例没能让你觉得有什么特别,那么请看这个例子:
DataLineage.Demo =
VAR vTable = SELECTCOLUMNS( DISTINCT( 'Product'[Category] ) , "Item" , 'Product'[Category] )
RETURN SUMX( vTable , [KPI] )现在,用 VAR 构建的 vTable 的过程是:
第一步,先计算 DISTINCT( 'Product'[Category] 得到一个过程中的表;
第二步,再通过 SELECTCOLUMNS 取出上述过程表的 'Product'[Category] 列,并更名为:Item;
第三步,针对这个 vTable 计算度量值后求和。
我们看看最后的结果:
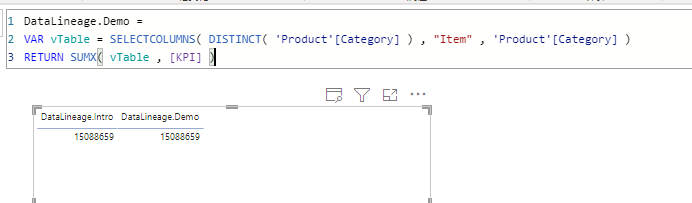
可以看出,与此前的结果是一致的。
也就是说,不管我们在中间的计算过程再增加多少过程,如果其本质只是针对数据模型中的列的获取,那都不会改变数据模型本身,也就不会改变计算过程中数据与数据模型的联系。
一个反例
当然,我们需要一个反例来更好的理解这个数据沿袭,如下:
DataLineage.Error =
VAR vTable = SELECTCOLUMNS( DISTINCT( 'Product'[Category] ) , "Item" , 'Product'[Category] & "" )
RETURN SUMX( vTable , [KPI] )这里的区别在于:

在使用 SELECTCOLUMNS 取出元素的时候,将该列的元素进行了计算,那么虽然元素没有变化,但计算结果就不再一样了,如下:

由于没有了数据沿袭,在计算 SUMX 的时候,vTable 有 3 行,由于其山下文转换没有了数据沿袭的存在,不再构成对数据模型的联系,也就不会筛选数据模型,进而导致总的结果是普通计算结果的 3 倍。
进一步实验
从刚才的反例可以看出,如果破坏了列的元素,就会丢失数据沿袭。
还可以再做一个更仔细的实验,如下:
DataLineage.Error2 =
VAR vTable =
SELECTCOLUMNS(
DISTINCT( 'Product'[Category] ) ,
"Item" , IF( 'Product'[Category] = "家具" , 'Product'[Category] & "" , 'Product'[Category] )
)
RETURN SUMX( vTable , [KPI] )这个实验的特点是,仅仅针对某个元素进行破坏数据沿袭的计算,而其他元素保持不变,那么可以还会部分保持数据沿袭吗?
神奇的效果出现了:
也就是说,如果某行的计算并非获取原始元素,而进行了计算;而其他元素直接获取原始元素,在这种情况下,是否可以部分保持数据沿袭?
请在留言区写下你的看法和你的理解吧。
当然,你可以自己完成这个实验里知道这个结果是什么。
数据沿袭有什么用
数据沿袭,其本质是一种非常自然的存在。请大家考虑一个经典的帕累托积累 % 计算问题,如下:
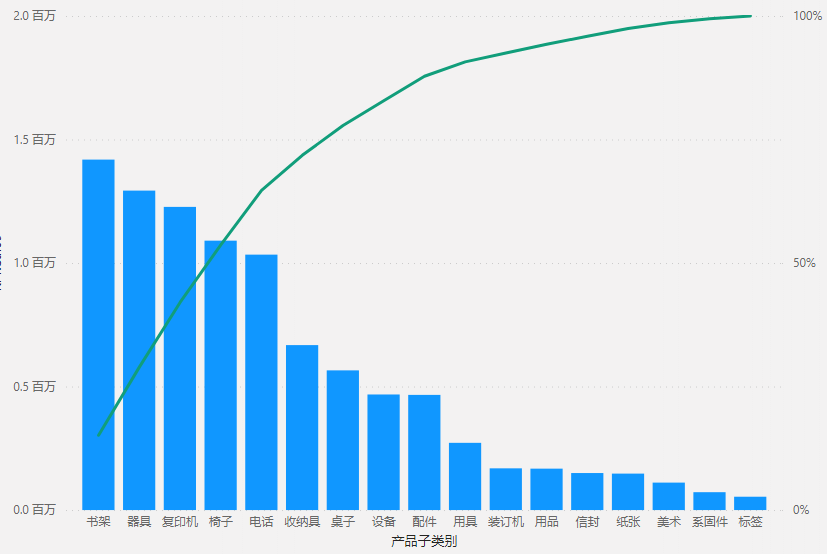
针对这条积累 % 的计算曲线,考虑以下 DAX 公式:
ABC.KPI.Cumulate% =
VAR vCurrentValue = [KPI.Sales]
VAR vItemList = ALLSELECTED( 'Model_产品'[产品子类别] )
VAR vItems =
FILTER(
vItemList , [KPI.Sales] >= vCurrentValue
)
RETURN CALCULATE( [KPI.Sales], vItems ) / CALCULATE( [KPI.Sales] , ALLSELECTED( 'Model_产品'[产品子类别] ) )其中,vItemList = ALLSELECTED( 'Model_产品'[产品子类别] ) 已经将数据模型的某列进行了暂存,而进一步对其进行计算,得到 vItems,更重要的是在最后的计算中,vItems 作为 CALCULATE 的筛选参数是否可以起到筛选的作用呢,毕竟 vItems 已经经过了四次转换:
第一次,ALLSELECTED ('Model_产品 '[产品子类别] );
第二次,赋给 vItemList;
第三次,FILTER;
第四次,vItems。
在四次转换后所得到的 vItems,即使你理解了上述的数据沿袭的概念,但此时你可以意识到以下两个重要的知识吗?
【重要知识】即使经过多达 4 次,且包括取出,暂存,过滤等操作,依然会保持数据沿袭,与原有数据模型有关系。
【重要启发】可以通过数据沿袭的特性构建逻辑清晰但形式多步复杂的计算流程,由于数据沿袭,整个计算流程完全自然与数据模型打通。
上述的 ABC.KPI.Cumulate% 的计算逻辑是正确的,而且,这正反应了这两点重要的知识。
结论
数据沿袭,表面是一个晦涩的概念,但其实它是数据模型在计算中的自然演化,保持对数据模型的联系。
注意:这里用了 “联系” 二字,而没有用 “关系” 二字。请你理解我们想强调的以及避免的混淆。
另外,在理解了数据沿袭的知识后,我们通过上述的【重要启发】构建很多复杂的计算而逻辑清晰,这篇文章就是为了后续的内容做的引子。有了数据沿袭,我们就可以设计出一些通用的模式,在随后的文章中会和大家分享。
最后,请你猜猜:上述 DataLineage.Error2 的计算会不会保持部分数据沿袭?请你在留言区写出你的想法吧。
在订阅了BI佐罗讲授的《BI真经》之《BI进行时》课程区,除了可以下载本文案例,还可以观看视频讲解。
Power BI 终极系列课程《BI真经》

BI真经 - 让数据真正成为你的力量
扫码与精英一起讨论 Power BI,验证码:data2021
点击“阅读原文”进入学习中心
↙