
程序员修神之路--缓存架构不够好,系统容易瘫痪
“灵魂拷问
缓存能大幅度提高系统性能,也能大幅度提高系统瘫痪几率 怎么样防止缓存系统被穿透? 缓存的雪崩是不是可以完全避免?
前几篇文章我们介绍了缓存的优势以及数据一致性的问题,在一个面临高并发系统中,缓存几乎成了每个架构师应对高流量的首冲解决方案,但是,一个好的缓存系统,除了和数据库一致性问题之外,还存在着其他问题,给整体的系统设计引入了额外的复杂性。而这些复杂性问题的解决方案也直接了影响系统的稳定性,最常见的比如缓存的命中率问题,在一个高并发系统中,核心功能的缓存命中率一般要保持在90%以上甚至更高,如果低于这个命中率,整个系统可能就面临着随时被峰值流量击垮的可能,这个时候我们就需要优化缓存的使用方式了。
如果按照传统的缓存和DB的流程,一个请求到来的时候,首先会查询缓存中是否存在,如果缓存中不存在则去查询对应的数据库。假如系统每秒的请求量为10000,而缓存的命中率为60%,则每秒穿透到数据库的请求数为4000,对于关系型数据库mysql来说,每秒4000的请求量对于分了一主三从的Mysql数据库架构来说也已经足够大了,再加上主从的同步延迟等诸多因素,这个时候你的mysql已经行走在down机边缘了。
“缓存的最终目的,是在保证请求低延迟的情况下,尽最大努力提高系统的吞吐量
那缓存系统可能会影响系统崩溃的原因有那些呢?
缓存穿透
“缓存穿透是指:当一个请求到来的时候,在缓存中没有查找到对应的数据(缓存未命中),业务系统不得不从数据库(这里其实可以笼统的成为后端系统)中加载数据
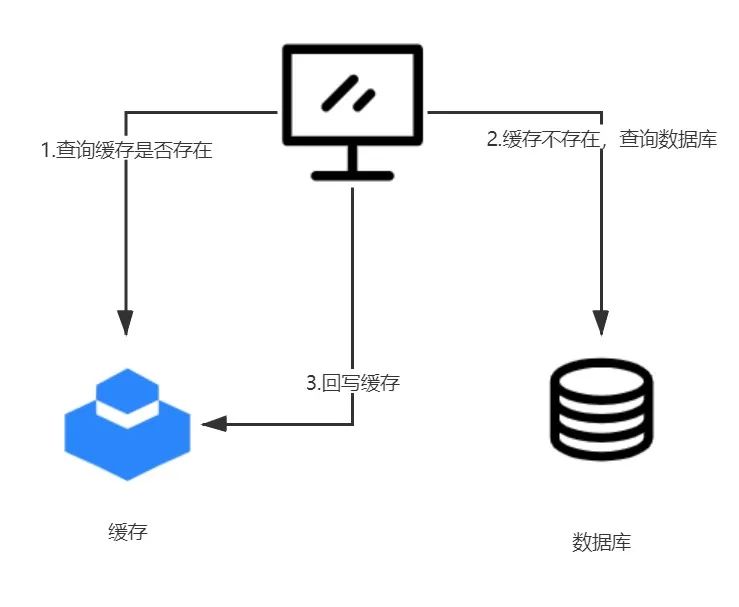
发生缓存穿透的原因根据场景分为两种:
请求的数据在缓存和数据中都不存在
当数据在缓存和数据库都不存在的时候,如果按照一般的缓存设计,每次请求都会到数据库查询一次,然后返回不存在,这种场景下,缓存系统几乎没有起任何作用。在正常的业务系统中,发生这种情况的概率比较小,就算偶尔发生,也不会对数据库造成根本上的压力。
最可怕的是出现一些异常情况,比如系统中有死循环的查询或者被黑客攻击的时候,尤其是后者,他会故意伪造大量的请求来读取不存在的数据而造成数据库的down机,最典型的场景为:如果系统的用户id是连续递增的int型,黑客很容易伪造用户id来模拟大量的请求。
请求的数据在缓存中不存在,在数据库中存在
这种场景一般属于业务的正常需求,因为缓存系统的容量一般是有限制的,比如我们最常用的Redis做为缓存,就受到服务器内存大小的限制,所以所有的业务数据不可能都放入缓存系统中,根据互联网数据的二八规则,我们可以优先把访问最频繁的热点数据放入缓存系统,这样就能利用缓存的优势来抗住主要的流量来源,而剩余的非热点数据,就算是有穿透数据库的可能性,也不会对数据库造成致命压力。
换句话说,每个系统发生缓存穿透是不可避免的,而我们需要做的是尽量避免大量的请求发生穿透,那怎么解决缓存穿透问题呢?解决缓存的穿透问题本质上是要解决怎么样拦截请求的问题,一般情况下会有以下几种方案:
回写空值
当请求的数据在数据库中不存在的时候,缓存系统可以把对应的key写入一个空值,这样当下次同样的请求就不会直接穿透数据库,而直接返回缓存中的空值了。这种方案是最简单粗暴的,但是要注意几点:
当有大量的空值被写入缓存系统中,同样会占用内存,不过理论上不会太多,完全取决于key的数量。而且根据缓存淘汰策略,可能会淘汰正常的数据缓存项 空值的过期时间应该短一些,比如正常的数据缓存过期时间可能为2小时,可以考虑空值的过期时间为10分钟,这样做一是为了尽快释放服务器的内存空间,二是如果业务产生相应的真实数据,可以让缓存的空值快速失效,尽快做到缓存和数据库一致。
//获取用户信息
public static UserInfo GetUserInfo(int userId)
{
//从缓存读取用户信息
var userInfo = GetUserInfoFromCache(userId);
if (userInfo == null)
{
//回写空值到缓存,并设置缓存过期时间为10分钟
CacheSystem.Set(userId, null,10);
}
return userInfo;
}
布隆过滤器
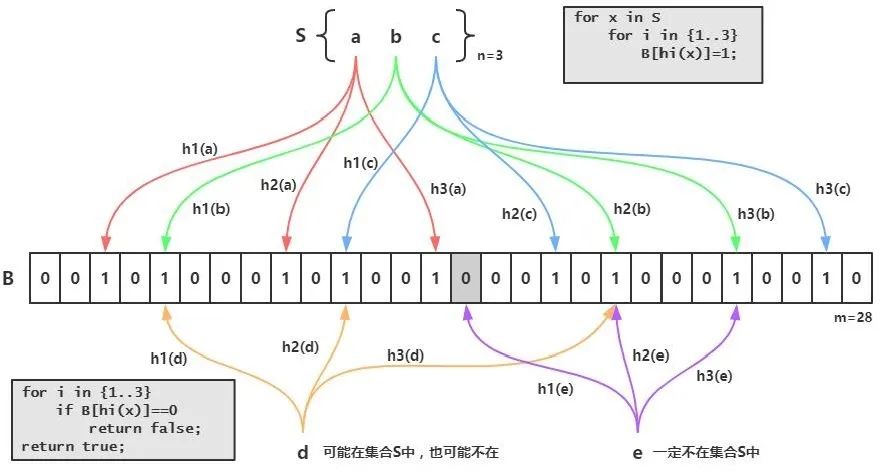
“布隆过滤器:将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力
布隆过滤器有几个很大的优势
占用内存非常小 对于判断一个数据不存在百分百正确
具体可以参见之前的文章或者百度脑补一下布隆过滤器:
由于布隆过滤器基于hash算法,所以在时间复杂度上是O(1),在应对高并发的场景下非常合适,不过使用布隆过滤器要求系统在产生数据的时候需要在布隆过滤器同时也写入数据,而且布隆过滤器也不支持删除数据,因为多个数据可能会重用同一个位置。
缓存雪崩
“缓存雪崩是指缓存中数据大批量同时过期,造成查询数据库数据量巨大,引起数据库压力过大导致系统崩溃。
与缓存穿透现象不同,缓存穿透是指缓存中不存在数据而造成会对数据库造成大量查询,而缓存雪崩是因为缓存中存在数据,但是同时大量过期造成。但是本质上是一样的,都是对数据库造成了大量的请求。
无论是穿透还是雪崩都面临着同样的数据会有多个线程同时请求,同时查询数据库,同时回写缓存的一致性问题。举例来说,当多个线程同时请求用户id为1的用户,这个时候缓存正好失效,那这多个线程同时会查询数据库,然后同时会回写缓存,最可怕的是,这个回写的过程中,另外一个线程更新了数据库,就造成了数据不一致,这个问题在之前的文章中着重讲过,大家一定要注意。
同样的数据会被多个线程产生多个请求是产生雪崩的一个原因,针对这种情况的解决方案是把多个线程的请求顺序化,使其只有一个线程会产生对数据库的查询操作,比如最常见的锁机制(分布式锁机制),现在最常见的分布式锁是用redis来实现,但是redis实现分布式锁也有一定的坑,可以参见之前的文章(如果使用的是Actor模型的话会在无锁的模式下更优雅的实现请求顺序化)
多个缓存key同时失效的场景是产生雪崩的主要原因,针对这样的场景一般可以利用以下几种方案来解决
设置不同过期时间
给缓存的每个key设置不同的过期时间是最简单的防止缓存雪崩的手段,整体思路是给每个缓存的key在系统设置的过期时间之上加一个随机值,或者干脆是直接随机一个值,有效的平衡key批量过期时间段,消掉单位之间内过期key数量的峰值。
public static int SetUserInfo(int userId)
{
//读取用户信息
var userInfo = GetUserInfoFromDB(userId);
if (userInfo != null)
{
//回写到缓存,并设置缓存过期时间为随机时间
var cacheExpire = new Random().Next(1, 100);
CacheSystem.Set(userId, userInfo, cacheExpire);
return cacheExpire;
}
return 0;
}
后台单独线程更新
这种场景下,可以把缓存设置为永不过期,缓存的更新不是由业务线程来更新,而是由专门的线程去负责。当缓存的key有更新时候,业务方向mq发送一个消息,更新缓存的线程会监听这个mq来实时响应以便更新缓存中对应的数据。不过这种方式要考虑到缓存淘汰的场景,当一个缓存的key被淘汰之后,其实也可以向mq发送一个消息,以达到更新线程重新回写key的操作。
缓存的可用性和扩展性
和数据库一样,缓存系统的设计同样需要考虑高可用和扩展性。虽然缓存系统本身的性能已经比较高了,但是对于一些特殊的高并发的热点数据,还是会遇到单机的瓶颈。举个栗子:假如某个明星出轨了,这个信息数据会缓存在某个缓存服务器的节点上,大量的请求会到达这个服务器节点,当到达一定程度的时候同样会发生down机的情况。类似于数据库的主从架构,缓存系统也可以复制多分缓存副本到其他服务器上,这样就可以将应用的请求分散到多个缓存服务器上,缓解由于热点数据出现的单点问题。
和数据库主从一样,缓存的多个副本也面临着数据的一致性问题,同步延迟问题,还有主从服务器相同key的过期时间问题。
至于缓存系统的扩展性同样的道理,也可以利用“分片”的原则,利用一致性哈希算法将不同的请求路由到不同的缓存服务器节点,来达到水平扩展的要求,这一点和应用的水平扩展道理一样。
写在最后
通过以上可以看出,无论是应用服务器的高可用架构还是数据库的高可用架构,还是缓存的高可用其实道理都是类似的,当我们掌握了其中一种就很容易的扩展到任何场景中。如果这篇文章对你有多帮助,请分享给身边的朋友,最后欢迎大家留言写下你们在日常开发中用到的其他关于缓存高可用,可扩展性,以及防止穿透和雪崩的方案,让我们一起进步!!

更多精彩文章