
炒股必看的时序预测基本方法 —— 移动平均(SMA、EMA、WMA)

时间序列预测
移动平均就是用当前时刻前期的观测值预测下一期的取值。
给定一个时间序列,观测值序列为。
可预测为前项的平均值,即:
其中,为滑动窗口大小表示需要往前推多少期。
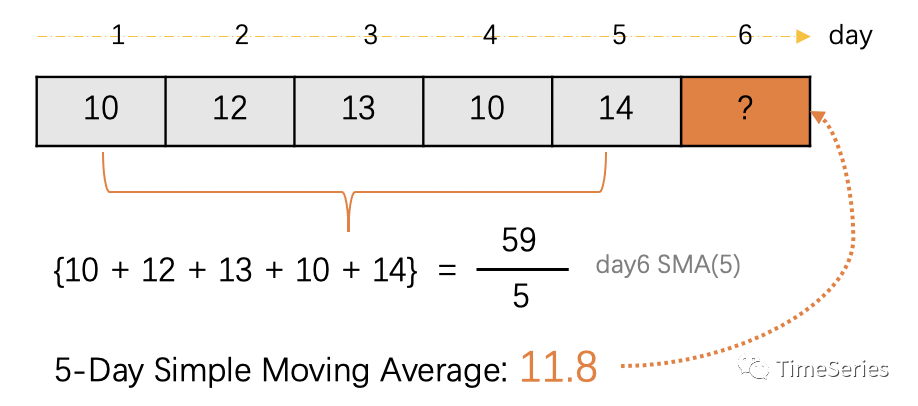
根据计算平均数的方法划分,移动平均可分为简单移动平均、指数移动平均、加权移动平均等。
移动平均是根据前若干个观测值,预测下期的取值。那下下期、下下下期该如何预测呢?可以考虑使用二次移动平均,也叫二项移动,即在一次移动平均的基础上再移动平均。
注意:移动平均用于预测场景时,尤其是多步预测,有个前提假设条件,序列相对平稳,没有趋势、季节性的情况。
描述趋势特征
移动平均能够去除时间序列的短期波动,使得数据变得平滑,从而可以方便看出序列的趋势特征。尤其在金融领域,移动平均线作为一种计算简单、易于解释的趋势性指标,可以从中看出市场的趋势和倾向。
下图显示了五粮液股票价格数据以及30日简单移动平均值。移动平均线平滑了股价的波动,从而显示了长期的波动趋势。
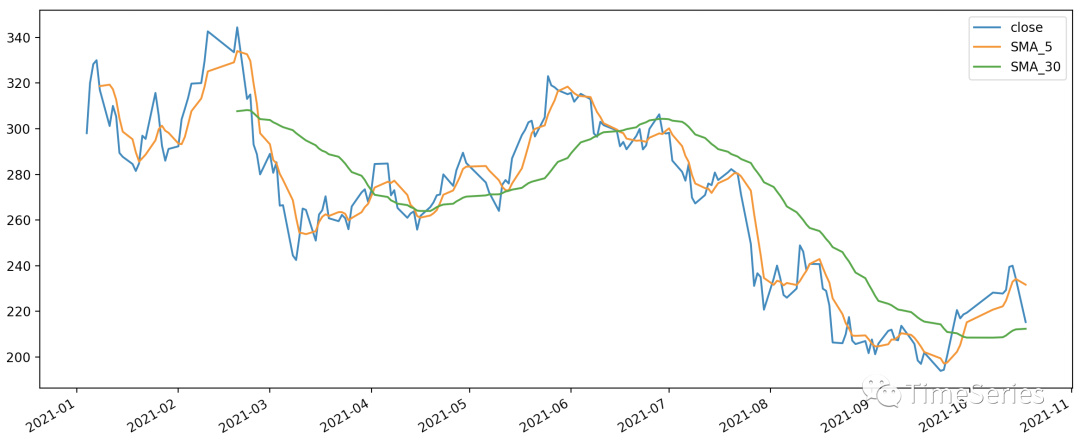 从上图可以看出,原序列波动较大,经移动平均后,随机波动明显减少;窗口大小越大,平滑后波动越小,滞后越明显。
从上图可以看出,原序列波动较大,经移动平均后,随机波动明显减少;窗口大小越大,平滑后波动越小,滞后越明显。
移动平均有两种方法:中心移动平均,尾部移动平均。中心移动平均,计算t时刻的移动平均值时同时使用t时刻之前的观测值及t时刻之后的观测值,牵扯到时间穿越问题,无法做预测,通常用来可视化;尾部移动平均,计算t时刻的移动平均值时仅使用t时刻之前的观测值,通常用来预测,也是本文学习的目标。
简单移动平均
简单移动平均(Simple Moving Average),是最容易使用的一种,也是最容易理解的。
其中,为窗口大小,表示t时刻的移动平均值。
以下为“五粮液”今年十一后七个交易日的收盘价移动平均线的实现代码:
import pandas as pd
import akshare as ak
df = ak.stock_zh_a_hist(symbol="000858", start_date="20211008", end_date='20211018')
df = df.set_index('日期')
df.index = pd.to_datetime(df.index)
df = df[['收盘']]
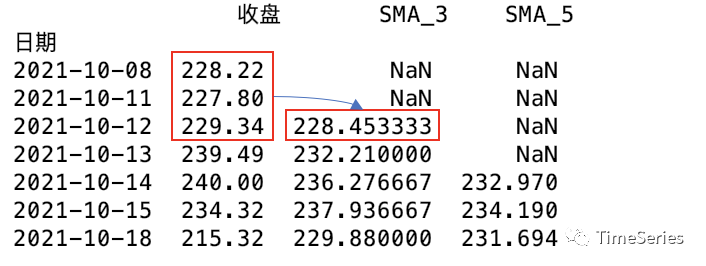
df['SMA_3'] = df['收盘'].rolling(window=3).mean()
df['SMA_5'] = df['收盘'].rolling(window=5).mean()
print(df)
加权移动平均
加权移动平均(Weighted Moving Average)与SMA类似,但是在计算平均数时并不是等量齐观,可以给最近的观测值相对历史观测值更大的权重。比如股票价格,最近的价格最有影响力,历史价格随着时间拉长影响力越小。
技术分析中,权重系数为n~0,即最近一个数值的权重为n,次近的为n-1,如此类推,直到0。
import numpy as np
import pandas as pd
import akshare as ak
df = ak.stock_zh_a_hist(symbol="000858", start_date="20211008", end_date='20211018')
df = df.set_index('日期')
df.index = pd.to_datetime(df.index)
df = df[['收盘']]
def WMA(close, n):
weights = np.array(range(1, n+1))
sum_weights = np.sum(weights)
res = close.rolling(window=n).apply(lambda x: np.sum(weights*x) / sum_weights, raw=False)
return res
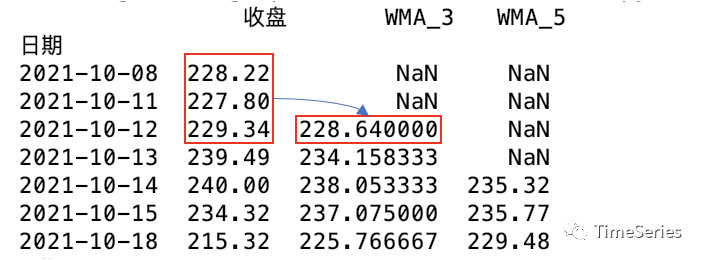
df['WMA_3'] = WMA(df['收盘'], 3)
df['WMA_5'] = WMA(df['收盘'], 5)
print(df)
这里再分享一个功能相同输出结果一样另一种比较有意思的实现方式:
def WMA(close, n):
return close.rolling(n).apply(lambda x: x[::-1].cumsum().sum() * 2 / n / (n + 1))
分母的实现:x[::-1].cumsum().sum()
说明:逆序累加,最后一个元素会参与n遍计算,第一个元素只会参与1次计算
:分子的实现:(n+1)*n/2
说明:(首项+尾项)*项数/2,熟悉的口号
指数移动平均

import pandas as pd
import akshare as ak
df = ak.stock_zh_a_hist(symbol="000858", start_date="20211008", end_date='20211018')
df = df.set_index('日期')
df.index = pd.to_datetime(df.index)
df = df[['收盘']]
df['SMA_3'] = df['收盘'].rolling(window=3).mean()
df['EMA_3'] = df['收盘'].ewm(span=3,min_periods=3).mean()
df['EMA_5'] = df['收盘'].ewm(span=5,min_periods=5).mean()
print(df)
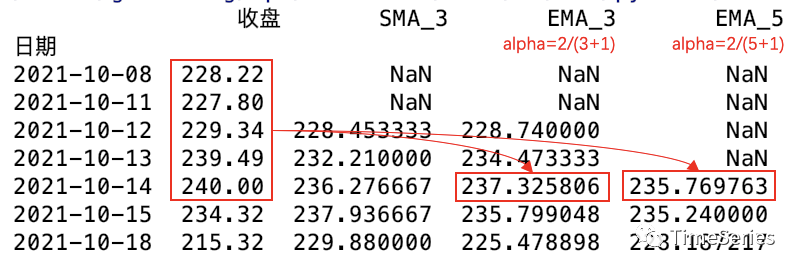
ewm()方法中可通过四选一[com or span or halflife or alpha]调整衰减系数。根据质心指定衰减,则;根据跨度指定衰减,则;根据半衰期指定衰减,则;
也可直接指定衰减系数alpha。adjust参数控制指数移动平均函数的计算方式。
adjust=False时,
adjust=True时(默认),
方法对比分析
从权重思维来看,三种方法都可以认为是加权平均。SMA:权重系数一致;WMA:权重系数随时间间隔线性递减;EMA:权重系数随时间间隔指数递减。
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# 窗口大小指定为30(30日均线时)
n = 30
# 简单移动平均-权重系数
weights_sma = np.ones(n)
# 加权移动平均-权重系数
weights_wma = range(1, n+1)
weights_wma /= np.sum(weights_wma)
weights_wma = weights_wma[::-1] # 按时间倒序
# 指数移动平均-加权系数(对应pandas.ewm(span=n))
alpha = 2 / (n+1)
dived = 1*(1-(1-alpha)**n)/(1-(1-alpha)) # 等比数列:a1*(1-q**n)/(1-q)
weights_ema = list(map(lambda i: (1-alpha)**i / dived, range(n)))
df = pd.DataFrame({'SMA(30)-Weights': weights_sma, 'WMA(30)-Weights': weights_wma, 'EMA(30)-Weights': weights_ema})
ticks = ['t'] + list(map(lambda i: 't-{}'.format(i), range(1,n)))
ax = df.plot.bar(subplots=True, figsize=(16, 6), title=['', '', ''])
ax[-1].set_xticklabels(ticks)
plt.show()
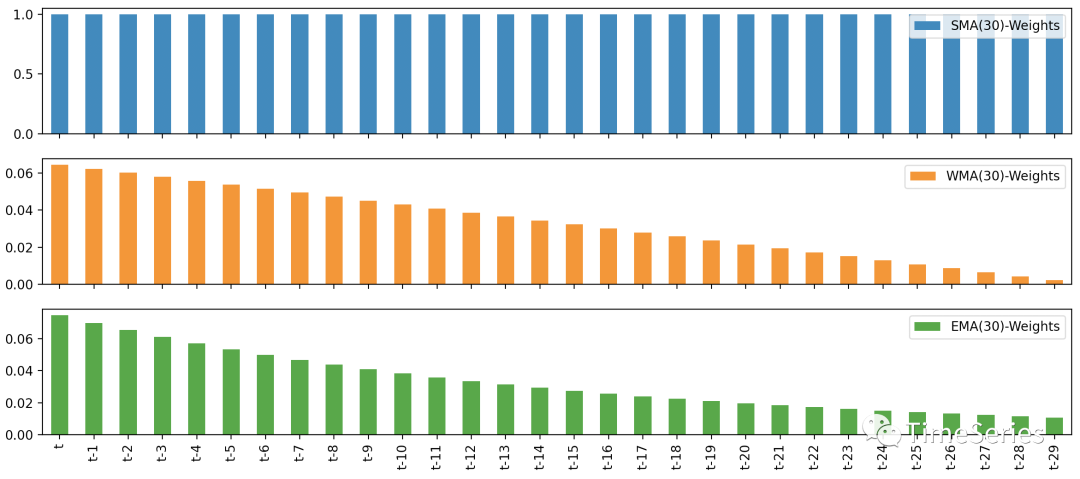 从上图中的权重系数随时间间隔衰减情况可以看出,指数移动平均系数衰减较快,也因此一般也能更快的发现趋势的变化。
从上图中的权重系数随时间间隔衰减情况可以看出,指数移动平均系数衰减较快,也因此一般也能更快的发现趋势的变化。
从实际股票分析场景看,先上图:
import numpy as np
import pandas as pd
import akshare as ak
from matplotlib import pyplot as plt
def SMA(close, n):
return close.rolling(window=n).mean()
def WMA(close, n):
return close.rolling(window=n).apply(lambda x: x[::-1].cumsum().sum() * 2 / n / (n + 1))
def EMA(close, n):
return close.ewm(span=n, min_periods=n).mean()
df = ak.stock_zh_a_hist(symbol="000858", start_date="20210101", end_date='20211018')
df = df.set_index('日期')
df.index = pd.to_datetime(df.index)
df = df[['收盘']]
df.columns = ['close']
df['SMA_30'] = SMA(df['close'], 30)
df['WMA_30'] = WMA(df['close'], 30)
df['EMA_30'] = EMA(df['close'], 30)
df.plot(figsize=(16, 6))
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
plt.xlabel('')
plt.show()
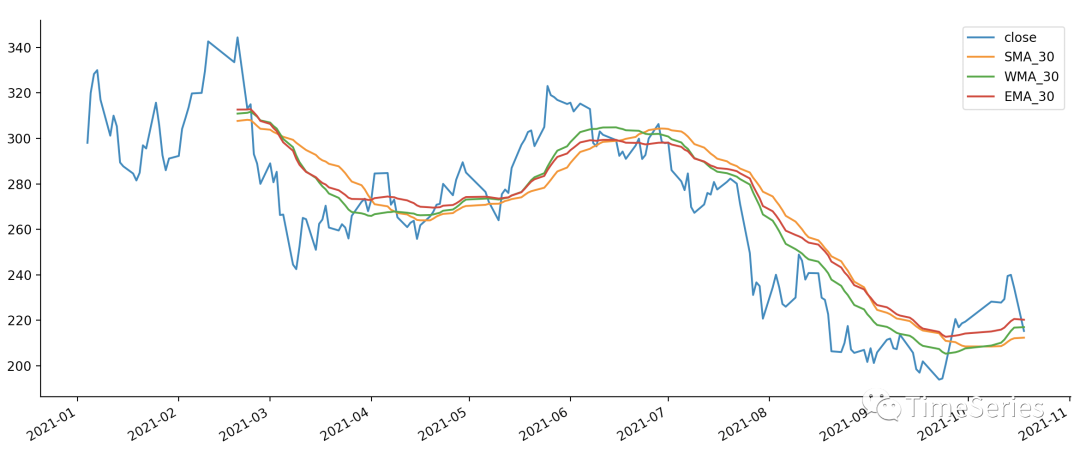 可以看出,三种方法均有一定的滞后性,所以在使用时用作判断长期趋势,短期股价分析还应结合更多指标。当然也可以互相组合使用,比如SMA+WMA,SMA+EMA;同时也可以通过设置窗口大小进行交叉分析,比如5日均线向上突破10日、30日均线股市中称之为“金叉”,利好。
可以看出,三种方法均有一定的滞后性,所以在使用时用作判断长期趋势,短期股价分析还应结合更多指标。当然也可以互相组合使用,比如SMA+WMA,SMA+EMA;同时也可以通过设置窗口大小进行交叉分析,比如5日均线向上突破10日、30日均线股市中称之为“金叉”,利好。
言而总之,移动平均虽预测能力有限,但仍有很多优点,计算简单,支持海量数据在线/实时计算,易于理解,可以描述序列长期趋势,也可当成一种最为简单的滤波器使用。作为时间序列预测的基本方法,了解其特性,在使用其他方法时若能灵活与之搭配或许也能产出意想不到的效果。
[1]https://www.math.pku.edu.cn/teachers/lidf/course/fts/ftsnotes/html/_ftsnotes/fts-mamod.html#ma-frcst
[2]https://forex-indicators.net/trend-indicators/moving-averages-ema-sma-wma
[3]https://blog.csdn.net/the_time_runner/article/details/101071591
[4]https://zhuanlan.zhihu.com/p/377045460
[5]https://www.cnblogs.com/xiaobajiu/p/7066490.html