
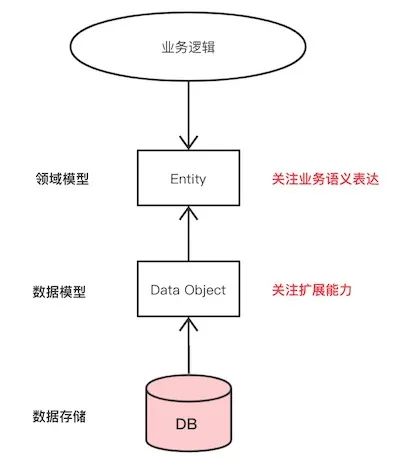
领域模型vs数据模型,应该怎么用?
点击上方“服务端思维”,选择“设为星标”
回复”669“获取独家整理的精选资料集
回复”加群“加入全国服务端高端社群「后端圈」
什么是领域模型?什么又是数据模型?两者可以等同吗?在实际应用中,怎么样才能用好它们?本文介绍领域模型和数据模型的概念定义,并举例说明两者相互混淆的错误用法,分享如何正确地应用它们。
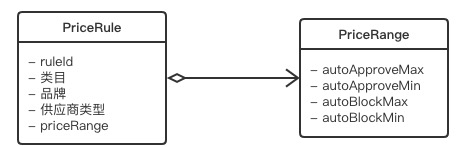


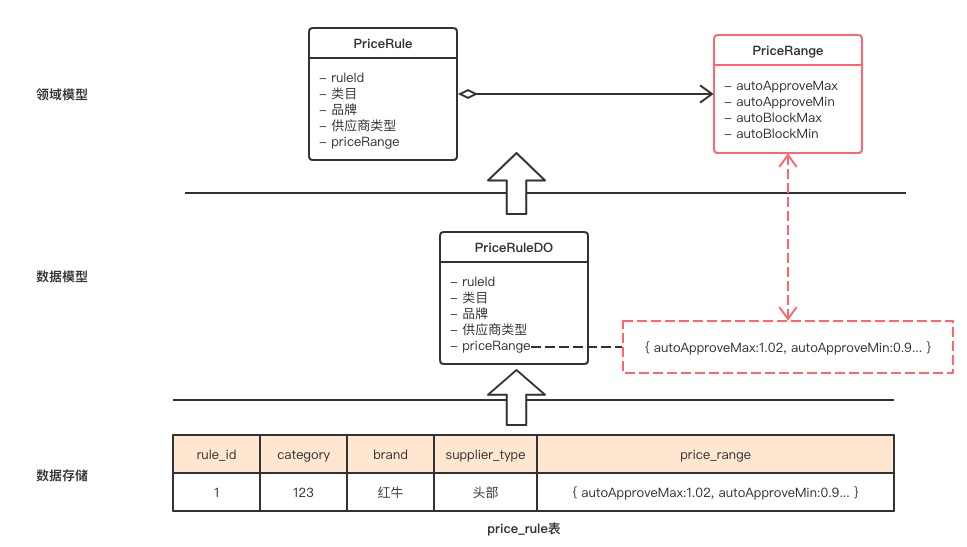
首先,维护一张数据库表肯定比两张的成本要小。
其次,其数据的扩展性更好。比如,新需求来了,需要增加一个建议价格(suggest price)区间,如果是两张表的话,我需要在price_range中加两个新字段,而如果是JSON存储的话,数据模型可以保持不变。

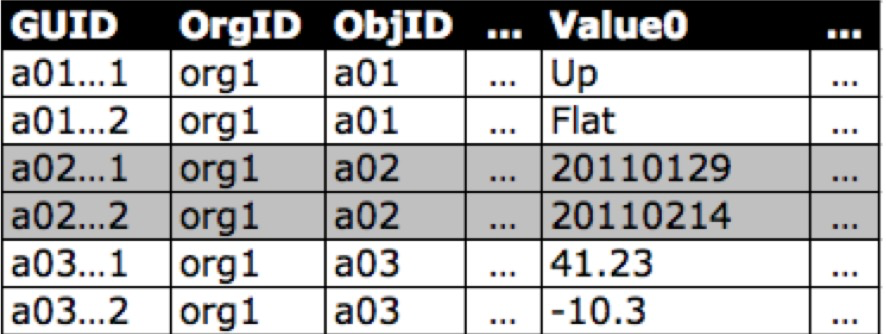
相关链接 [1]https://github.com/alibaba/COLA
[2]https://developer.salesforce.com/wiki/multi_tenant_architecture
— 本文结束 —

关注我,回复 「加群」 加入各种主题讨论群。
对「服务端思维」有期待,请在文末点个在看
喜欢这篇文章,欢迎转发、分享朋友圈


评论