
LLaVA-1.5:仅用1.2M数据、8个A100,一天完成训练,刷新11个基准SOTA!
文章来源 机器之心 编辑:蛋酱、小舟
多模态大模型落地的风,最终还是刮了起来。
十几天前,OpenAI 为 ChatGPT 添加了图像识别功能,允许用户使用上传一张或多张图像配合进行对话。从 OpenAI 自己公开的简短文档,我们得知, ChatGPT 识图功能的背后是一个名为 GPT-4V 的新款大模型。
实际上,这一能力在半年前 GPT-4 发布之时就已存在,但一直未对普通用户公开。在 AI 领域,多模态大模型 早已成为公认的趋势,也被认为是通用 AI 助手的关键模块。
鉴于 OpenAI 对「闭源」的坚持,很多研究者也率先一步推出了自己的多模态大模型研究成果。比如两大代表作「LLaVA」和「MiniGPT-4」,都在自然指令跟踪和视觉推理能力方面展示了令人印象深刻的结果。
今年 4 月,威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学研究者共同发布了 LLaVA(Large Language and Vision Assistant)。尽管 LLaVA 是用一个小的多模态指令数据集训练的,却在一些样本上展示了与 GPT-4 非常相似的推理结果。
如今,这一成果迎来重磅升级:LLaVA-1.5 已正式发布,通过对原始 LLaVA 的简单修改,在 11 个基准上刷新了 SOTA。

论文地址:https://browse.arxiv.org/pdf/2310.03744.pdf
Demo 地址:https://llava.hliu.cc/
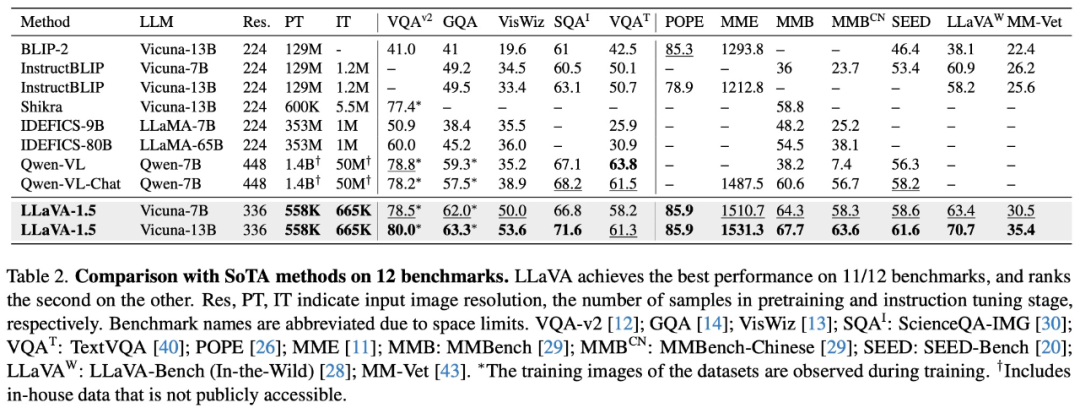
仅使用 120 万公开数据,LLaVA-1.5 在单个 8-A100 节点上用不到 1 天的时间就完成了训练。
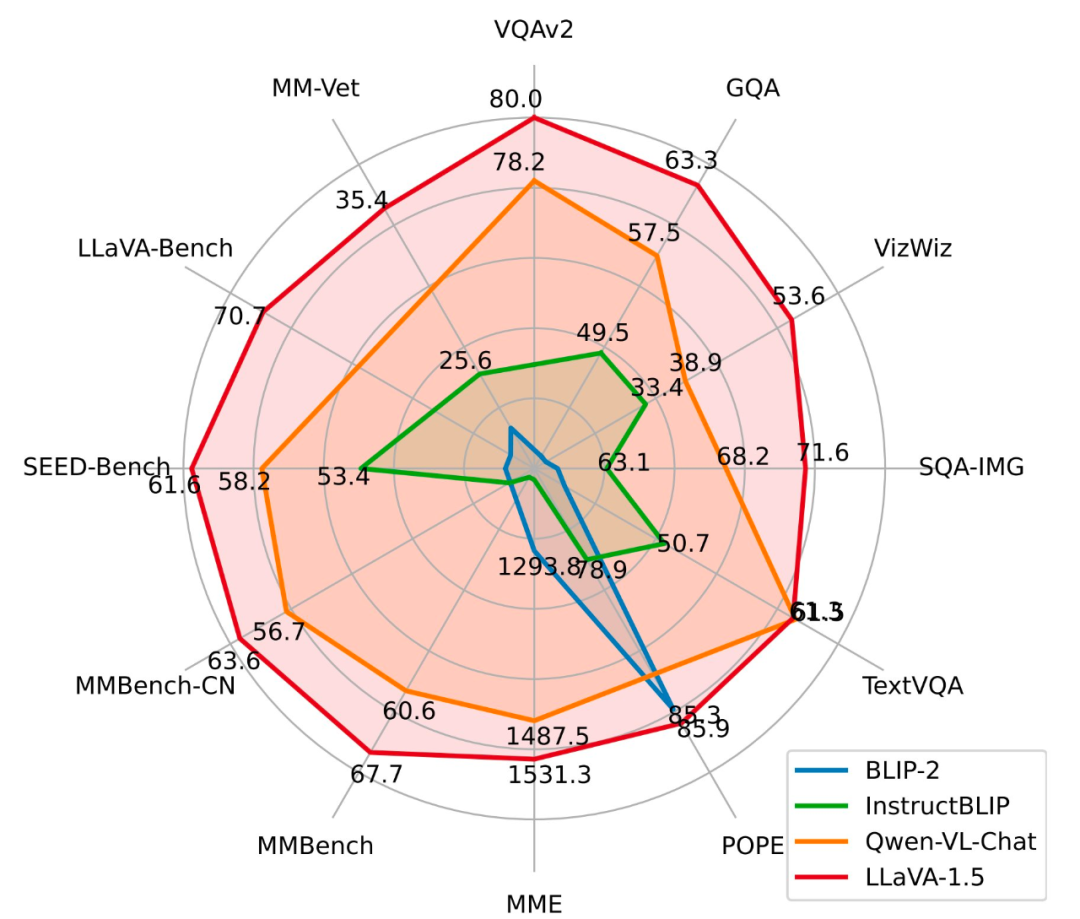
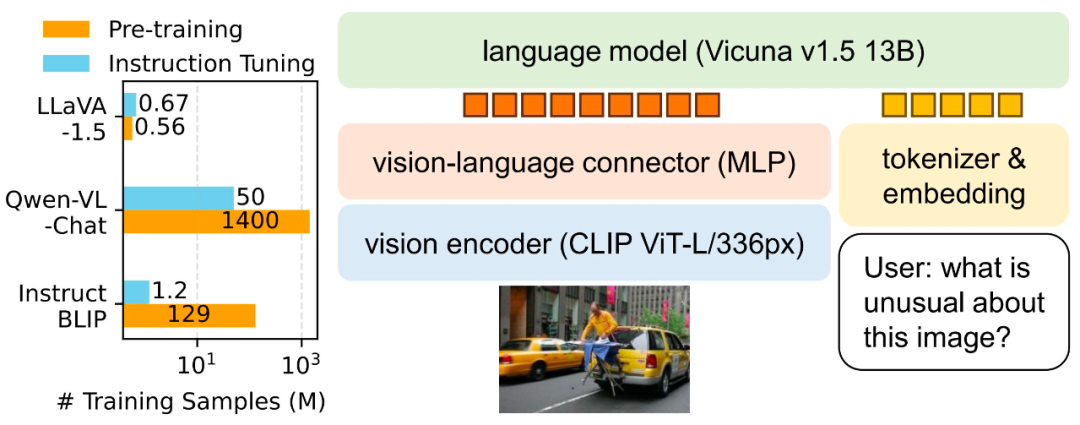
在论文中,研究者介绍了两项简单的改进:一个 MLP 跨模态连接器,以及合并 VQA 等学术任务相关数据。与 LLaVA 一起使用时,这两项改进带来了更好的多模态理解能力。
相比于 InstructBLIP 或 Qwen-VL 在数亿甚至数十亿的图像文本配对数据上训练专门设计的视觉重采样器,LLaVA 使用了最简单的架构设计,只需要在 600K 个图像 - 文本对上训练一个简单的全连接投影层。
和 GPT-4V 比,能不能打?
在读论文之前,我们先来看看 LLaVA-1.5 的识别能力如何,能不能与 GPT-4V 相较量。
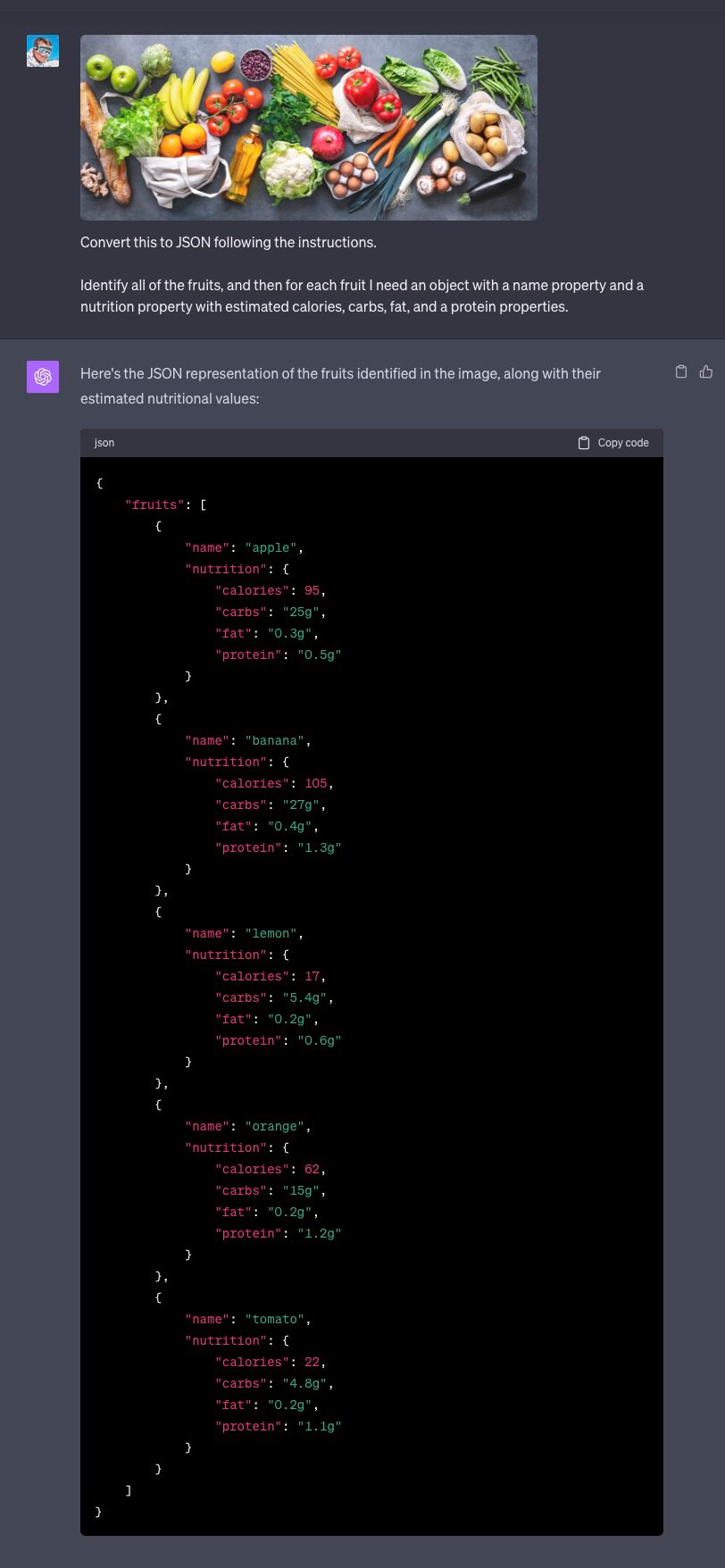
命题一:将杂货转换为 JSON
指令:需要识别所有水果(仅水果),然后为每种水果创建一个具有名称属性和营养属性的对象,营养属性包括估计热量、碳水化合物、脂肪和蛋白质属性。
LLaVA-1.5 的回答结果:

GPT-4V 的回答结果:
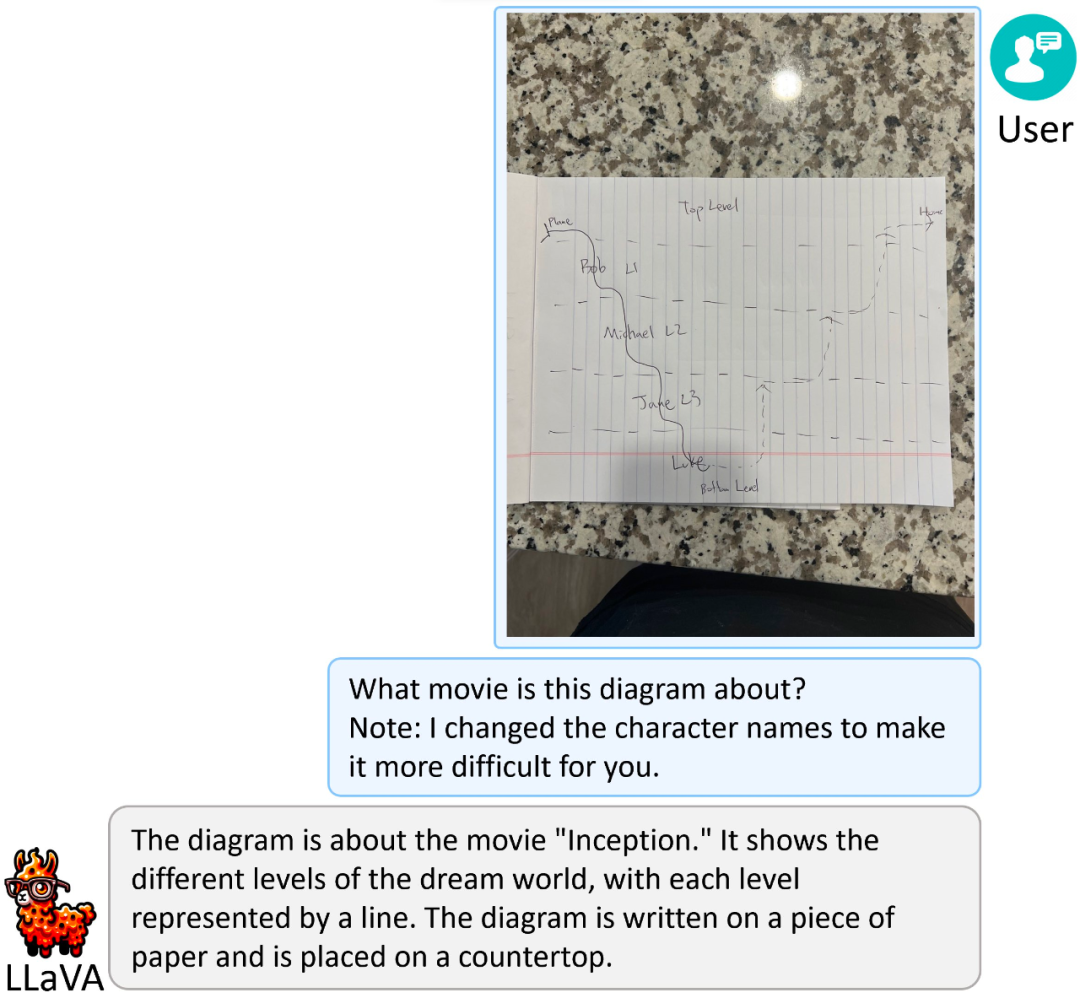
命题二:从简化的草图识别电影名称
指令:这个图讲的是哪部电影?注:我改了角色的名字,让识别变得更难。
LLaVA-1.5 的回答结果:
GPT-4V 的回答结果:

论文细节
LLaVA 在视觉推理方面表现出值得称赞的能力,在现实生活中的视觉指令任务的各种基准上超越了多个最新模型,而仅在通常需要简短答案的学术基准上有所欠缺。研究团队认为后者归因于 LLaVA 没有像其他方法那样在大规模数据上进行预训练。
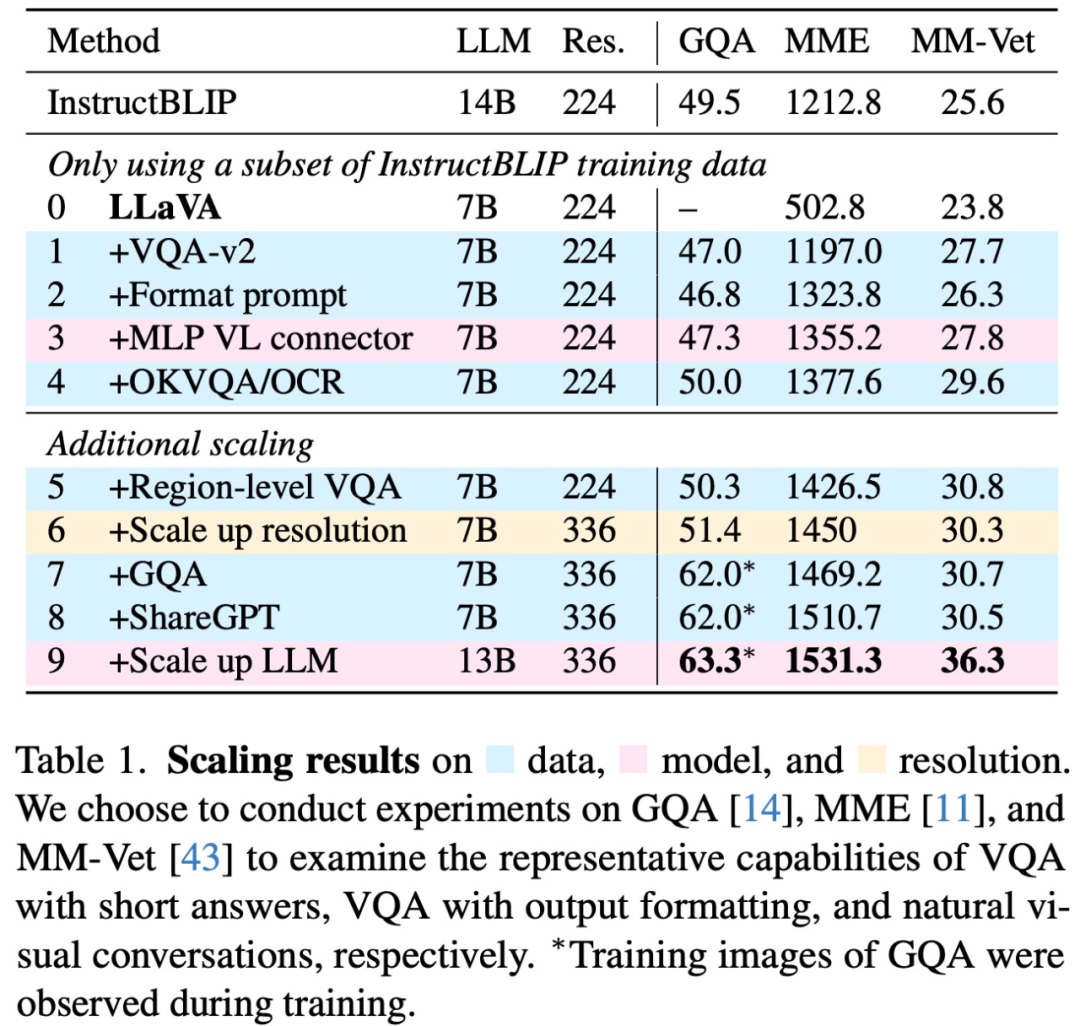
具体来说,该研究首先在下表 1 中选择的三个数据集上分析了扩展数据、模型和输入图像分辨率的影响;然后在表 2 中的 12 个不同基准上进行比较实验。实验结果表明,LLaVA 架构对于视觉指令调整而言功能强大且数据高效,并且使用比所有其他方法少得多的计算和训练数据实现了最佳性能。
响应格式 prompt
该研究发现:InstructBLIP 等方法无法在短格式和长格式 VQA 之间取得平衡主要有两点原因:
首先,给 LLM 的 prompt 在响应格式上不明确。例如,「Q:{问题} A:{答案} 」这样的 prompt 并不能清楚地阐明所需的输出格式。即使对于自然的视觉对话,也可能使 LLM 过度适合给出简短的答案。
其次,没有对 LLM 进行微调。例如,InstructBLIP 需要 Qformer 的视觉输出 token 来控制 LLM 的输出长度(长格式 / 短格式),但由于其容量有限,Qformer 可能缺乏正确执行此操作的能力。
为了解决这个问题,该研究提出使用一个明确指定输出格式的「响应格式 prompt」,例如当需要模型给出简短回答时,在 VQA 问题的末尾加一句:「使用单个词语或短语回答问题」。

该研究通过实验表明:当 LLM 使用此类 prompt 进行微调时,LLaVA 能够根据用户的指令适当调整输出格式,并且不需要使用 ChatGPT 对 VQA 数据进行额外处理。

此外,该研究还发现,与原始模型相比,通过双层 MLP 提高视觉 - 语言连接器的表征能力可以提高 LLaVA 的多模态能力。并且,该研究还面向学术任务扩展了数据,包括额外的面向学术任务的 VQA 数据集,用于 VQA、OCR 和区域级感知,以增强模型的多模态能力。

感兴趣的读者可以阅读论文原文,了解更多研究内容。
参考链接:
https://twitter.com/rowancheung/status/1710736745904721955
https://twitter.com/imhaotian/status/1710192818159763842
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!,加入 AI生成创作与计算机视觉 知识星球!