
Meta新开源模型AudioCraft炸场!文本自动生成音乐
专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!
8月3日,全球社交、科技巨头Meta(Facebook、Instagram等母公司)宣布开源文本生成音乐模型Audiocraft(开源地址:https://github.com/facebookresearch/audiocraft)。
据悉,Audiocraft是一个混合模型,由MusicGen、AudioGen和EnCodec组合而成。仅用文本就能生成鸟叫、汽车喇叭声、脚步等背景音频,或更复杂的音乐,适用于游戏开发、社交、视频配音等业务场景。
MusicGen论文:https://arxiv.org/abs/2306.05284
AudioGen论文:https://arxiv.org/abs/2209.15352
高保真解码器论文:https://arxiv.org/abs/2210.13438

Meta表示,ChatGPT掀起的大语言模型热潮受到了全球各行业的热烈追捧,相继开发出了很多自动生成文本、图片、视频的大模型。但关于音频领域的不是很多,开源模型更是少的可怜,而音频模型又是一个复杂的领域。
因此,Meta结合自身多年AI技术和训练数据积累推出了Audiocraft,这也是目前功能最强大的开源音乐模型之一。
Audiocraft简单介绍
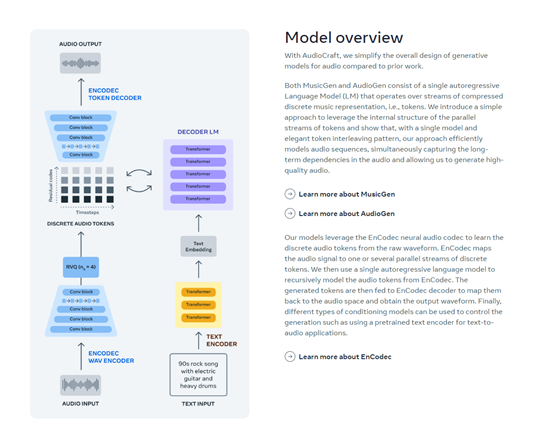
Audiocraft由MusicGen、AudioGen和EnCodec三个模型组合而成:
MusicGen是一个文本生成音乐的自回归语言模型,大约使用了40万份文本描述和元数据的录音,总计2万小时的授权音乐进行训练。可通过文本自动生成摇滚、流行、重金属、RPA等类型音乐。
AudioGen是一个文本生成音频的自回归语言模型,具备分离音频功能,例如,可识别背景声、说话声和物体发出的声音等。这有助于仅使用文本生成音频时,更准确贴近用户的目标音乐。
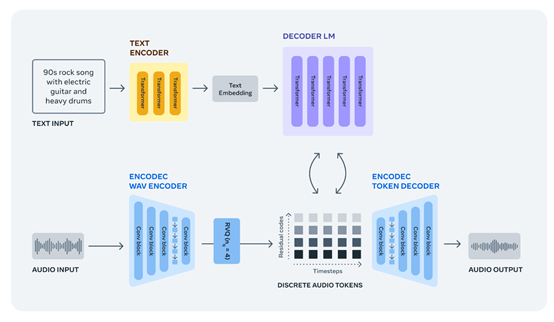
EnCodec是一个高保真音频、音乐的压缩和解压器,可以用最小的体积尽可能还原原始音乐,这对于打造高质量音频模型来说至关重要。EnCodec由编码器、量化器和解码器三大块组成。
1)编码器,通过获取未压缩的数据,并将其转换为更高维度和更低帧速率的表示。2)量化器,将编码器生成的“表示”压缩到目标大小,同时保留最重要的信息来重建原始信号。
3)解码器,将压缩信号转换回,与原始信号尽可能相似的波形。因为在低比特率下不可能进行完美的重建,所以,使用了鉴别器来提高音频生成样本的质量。
Audiocraft案例展示
Meta展示了Audiocraft通过文本自动生成各种音频、音乐的能力,并且质量与原始音乐几乎没有差别,以下是案例展示。
警笛声和嗡嗡作响的引擎接近并迅速通过
本文素材来源Meta,如有侵权请联系删除
END