
【文末送书】还在直接操作Redis?你Out啦!
共 7031字,需浏览 15分钟
·
2021-08-05 08:10
DAO接口只需继承CrudRepository,Spring Data Redis能为DAO组件提供实现类。
Spring Data Redis支持方法名关键字查询,只不过Redis查询的属性必须是被索引过的。
Spring Data Redis同样支持DAO组件添加自定义的查询方法—通过添加额外的接口,并为额外的接口提供实现类,Spring Data Redis就能将该实现类中的方法“移植”到DAO组件中。
Spring Data Redis同样支持Example查询。
And:比如在接口中可以定义“findByNameAndAge”。
Or:比如“findByNameOrAge”。
Is、Equals:比如“findByNameIs”“findByName”“findByNameEquals”。这种表示相同或相等的关键字不加也行。
Top、First:比如“findFirst5Name”“findTop5ByName”,实现查询前5条记录。
@RedisHash:该注解指定将数据类映射到Redis的Hash对象。
@TimeToLive:该注解修饰一个数值类型的属性,用于指定该对象的超时时长。
@Indexed:指定对普通类型的属性建立索引,索引化后的属性可用于查询。
@GeoIndexed:指定对Geo数据(地理数据)类型的属性建立索引。
spring.redis.host=localhostspring.redis.port=6379# 指定连接Redis的DB1数据库spring.redis.database=1# 连接密码spring.redis.password=32147# 指定连接池中最大的活动连接数为20spring.redis.lettuce.pool.maxActive = 20# 指定连接池中最大的空闲连接数为20spring.redis.lettuce.pool.maxIdle=20# 指定连接池中最小的空闲连接数为2spring.redis.lettuce.pool.minIdle = 2
public class Book{// 标识属性,可用于查询privateInteger id;// 带@Indexed注解的属性被称为“二级索引”,可用于查询privateString name;privateString description;privateDouble price;// 定义它的超时时长Longtimeout;// 省略getter、setter方法和构造器...}
public interface BookDaoextends CrudRepository<Book, Integer>,QueryByExampleExecutor<Book>{List<Book> findByName(Stringname);List<Book> findByDescription(StringsubDesc);}
(webEnvironment = SpringBootTest.WebEnvironment.NONE)public class BookDaoTest{private BookDaobookDao;publicvoid testSaveWithId(){varbook = new Book("疯狂Python","系统易懂的Python图书,覆盖数据分析、爬虫等热门内容", 118.0);// 显式设置id,通常不建议设置book.setId(2);book.setTimeout(5L); // 设置超时时长bookDao.save(book);}publicvoid testUpdate(){// 更新id为2的Book对象bookDao.findById(2).ifPresent(book -> {book.setName("疯狂Python讲义");bookDao.save(book);});}publicvoid testDelete(){// 删除id为2的Book对象bookDao.deleteById(2);}({"疯狂Java讲义, 最全面深入的Java图书, 129.0","SpringBoot终极讲义,无与伦比的SpringBoot图书, 119.0"})publicvoid testSave(String name, String description, Double price){varbook = new Book(name, description, price);bookDao.save(book);}(strings= {"疯狂Java讲义"})publicvoid testFindByName(String name){bookDao.findByName(name).forEach(System.out::println);}(strings= {"最全面深入的Java图书"})publicvoid testFindByDescription(String description){bookDao.findByDescription(description).forEach(System.out::println);}({"疯狂Java讲义, 最全面深入的Java图书"})publicvoid testExampleQuery1(String name, String description){// 创建样本对象(probe)vars = new Book(name, description, 1.0);// 不使用ExampleMatcher,创建默认的ExamplebookDao.findAll(Example.of(s)).forEach(System.out::println);}(strings= {"SpringBoot终极讲义"})publicvoid testExampleQuery2(String name){// 创建matchingAll的ExampleMatcherExampleMatchermatcher = ExampleMatcher.matching()// 忽略null属性,该方法可以省略//.withIgnoreNullValues().withIgnorePaths("description"); // 忽略description属性// 创建样本对象(probe)vars = new Book(name, "test", 1.0);bookDao.findAll(Example.of(s,matcher)).forEach(System.out::println);}}
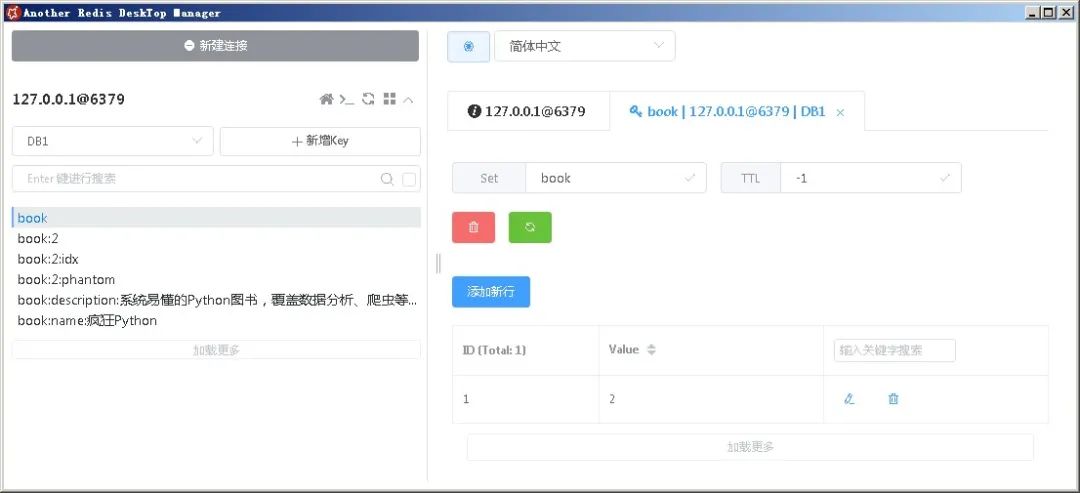
book:在该key对应的Set中添加新Book对象的id。
book:id:该key保存该Book对象的全部数据。
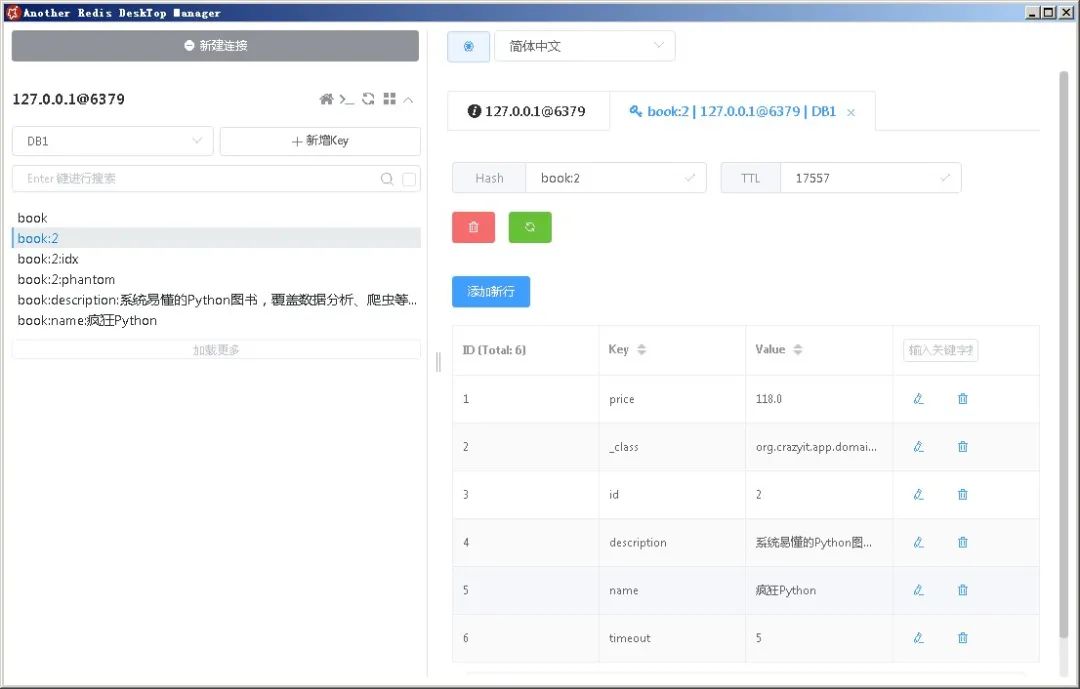
book:在该key对应的Set中添加新Book对象的id。
book:id:该key对应的Hash对象保存了该Book对象的全部数据。
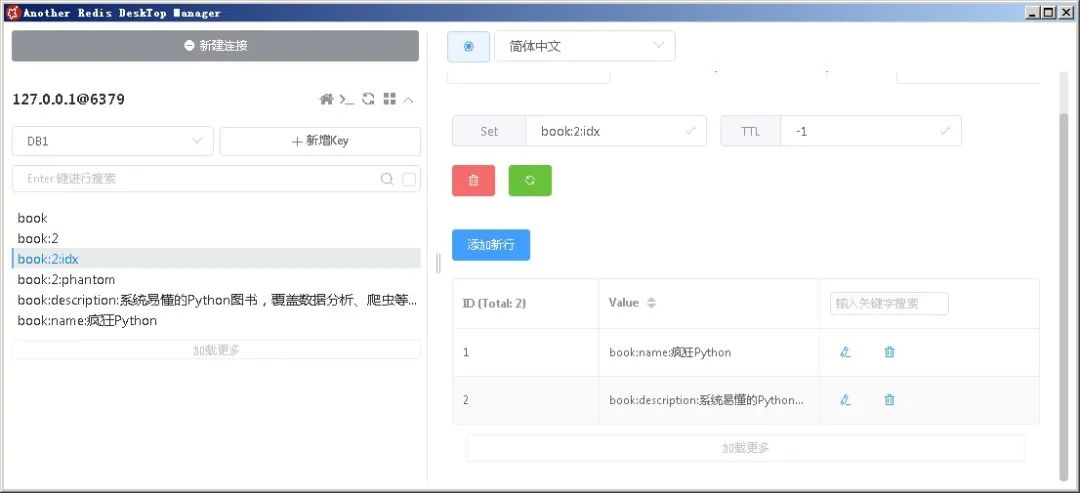
book:id:idx:该key对应的Set保存了该Book对象所有额外的key。
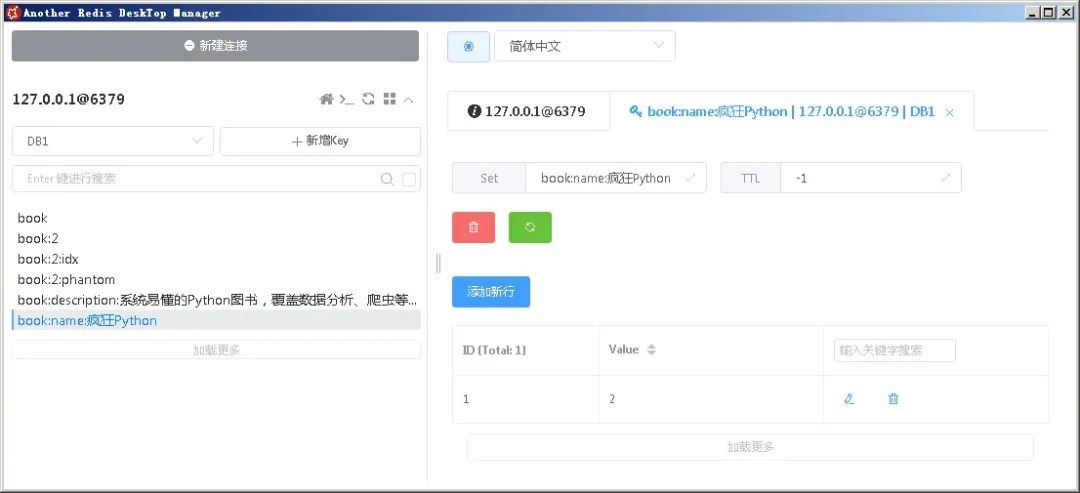
N个book:属性名:属性值:该key对应的Set保存了所有该属性都具有相同属性值的Book对象的id值。
小哈又来送书辣,这次是送5本《疯狂Spring Boot终极讲义》,直接在小程序抽奖助手上抽,小伙伴们在公众号回复关键字【抽奖】即可获取参与二维码,明晚八点开奖,包邮到家哦,感谢大家这么长时间以来对公众号的支持,感激感激哦~