
10000字详解用户画像与实时数仓之架构与实践
用户画像与实时数据分析是互联网企业的数据核心。知乎数据赋能团队以 Apache Doris 为基础,基于云服务构建高响应、低成本、兼顾稳定性与灵活性的实时数据架构,同时支持实时业务分析、实时算法特征、用户画像三项核心业务流,显著提升对于时效性热点与潜力的感知力度与响应速度,大幅缩减运营、营销等业务场景中的人群定向成本,并对实时算法的准确率及业务核心指标带来明显增益。

一、前言
知乎业务中,随着各业务线业务的发展,逐渐对用户画像和实时数据这两部分的诉求越来越多。对用户画像方面,期望有更快、更准、更方便的人群筛选工具和方便的用户群体分析能力。对于实时数据方面,期望拥有可以实时响应的用户行为流,同时在算法特征、指标统计、业务外显等业务场景有愈来愈多的数据实时化的诉求。
拆分当前业务主要在实时数据和用户画像两大部分有难点,共包含如下的三个方向目标:
通过提供实时的业务指标,解决业务对热点、潜力的把控,助力生产、消费,提 升优质创作量及内容消费能力。 提供实时的复杂计算的外显指标,加强用户体验,解决业务侧通过后端脚本计算的高维护成本和复杂性,节约成本,提升人效。
以实时数据为基础,提供多样的实时算法特征,与算法团队共同提升 DAU、留存、用户付费等核心指标。
用户筛选,做到多维、多类型的定向筛选,并接入营销、广告、 运营平台等系统,提高业务效率,降低人员成本。 用户分析,做到多角度用户分析,定向用户分析报告 0 成本,助力业务部门快速把握核心客户市场。
本文就知乎平台的数据赋能团队,基于以上三个方向的目标,就这四个问题,来逐一介绍这方面的技术实践经验和心得体会:
如何通过实时数据驱动业务发展? 如何从 0 -> 1 搭建实时数据中心? 如何搭建一套高效快速的用户画像系统来解决历史系统的多种问题? 如何快速高效的开发业务功能和保证业务质量?
1.1 名词解释
二、面临的挑战和痛点
针对当前业务目标,主要有以下几个具体要求。
搭建热点、潜力等紧随时间的指标和相关的排行榜,直接支持业务发展。
要全面覆盖多维度用户筛选的多种需求。 多角度、多方式覆盖用户分析。
02 数据实效性
通过 UBS 建设提升实效性(下面介绍)
通过实时数据系统与 Apache Doris配合共同建设,提升到 10 分钟内更新(下面介绍)
03 接口实时性
(1)热点运营场景,期望用户画像服务能在秒级别快速筛选出大量人群,用户后续的推送等运营场景,如何解决?
通过用户画像系统与 Apache Doris 配合共同建设,提升人群筛选的速度(下面介绍)
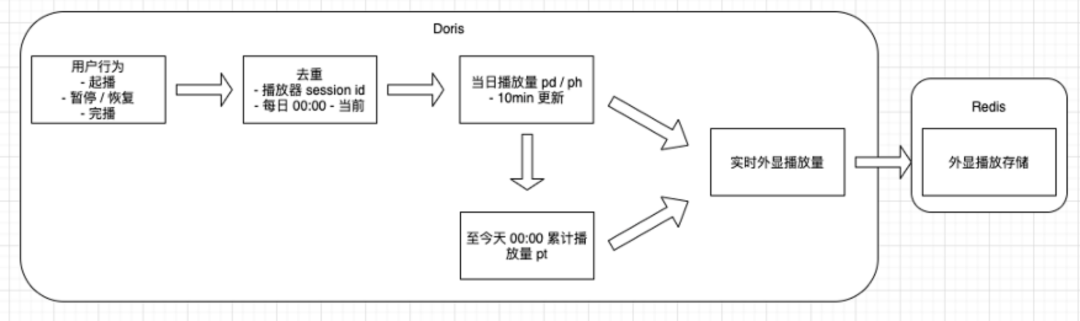
以播放量为例。在启播、暂停、完播、心跳等多个条件下,会同时有多个点,要进行去重。同时基于视频回答、视频的关系和双作者联合创作的关系,需要叠加,同时保证在父子内容异常状态的情况下过滤其中部分播放行为。
通过用户画像系统与 Apache Doris 配合共同建设,解决复杂的人群分析(下面介绍)
实时数据集成系统与 Apache Doris 配合共同建设,解决增 / 删 / 改逻辑(下面介绍)
通过选择 Lambda 架构作为数据架构解决(下面介绍)
三、实践及经验分享
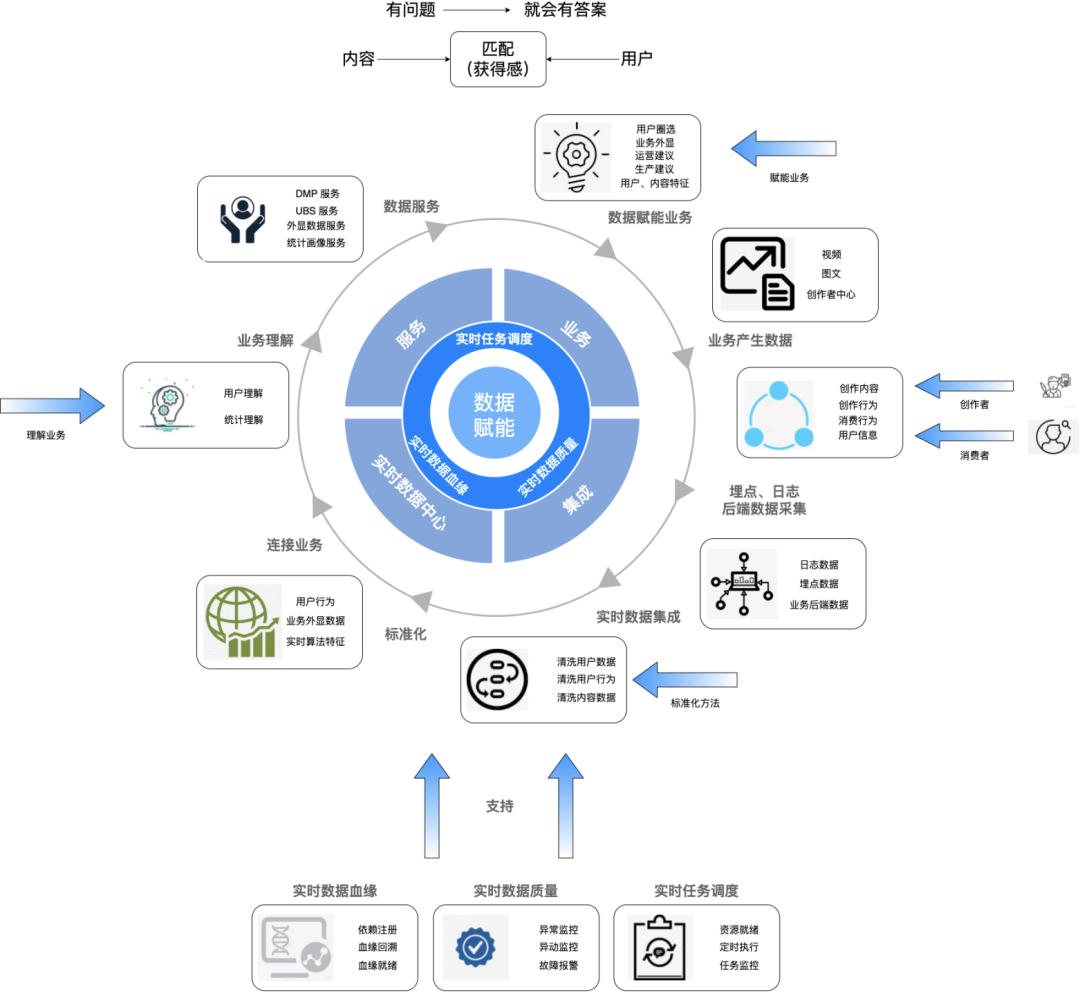
3.1 整体业务架构
应用层:负责当前我们的业务应用,直接为业务提供工具或提供业务的某些模块,与业务共担目标,为业务赋能。
业务模型层:支持应用层建设和一定的实时分析能力,同时也作为业务某一个流程的功能模块接入使用,为外部业务和自身应用层建设,与业务共担目标,为业务赋能。
业务工具层:支持应用层和业务模型层的开发,提供通用的工具,面向降低应用层和业务模型层的建设成本,提升整体建设的工程效能,保证业务稳定和数据质量准确。
基础设施:技术中台提供的基础设施和云服务,提供稳定可用的基础功能,保证上层建筑的稳定性。
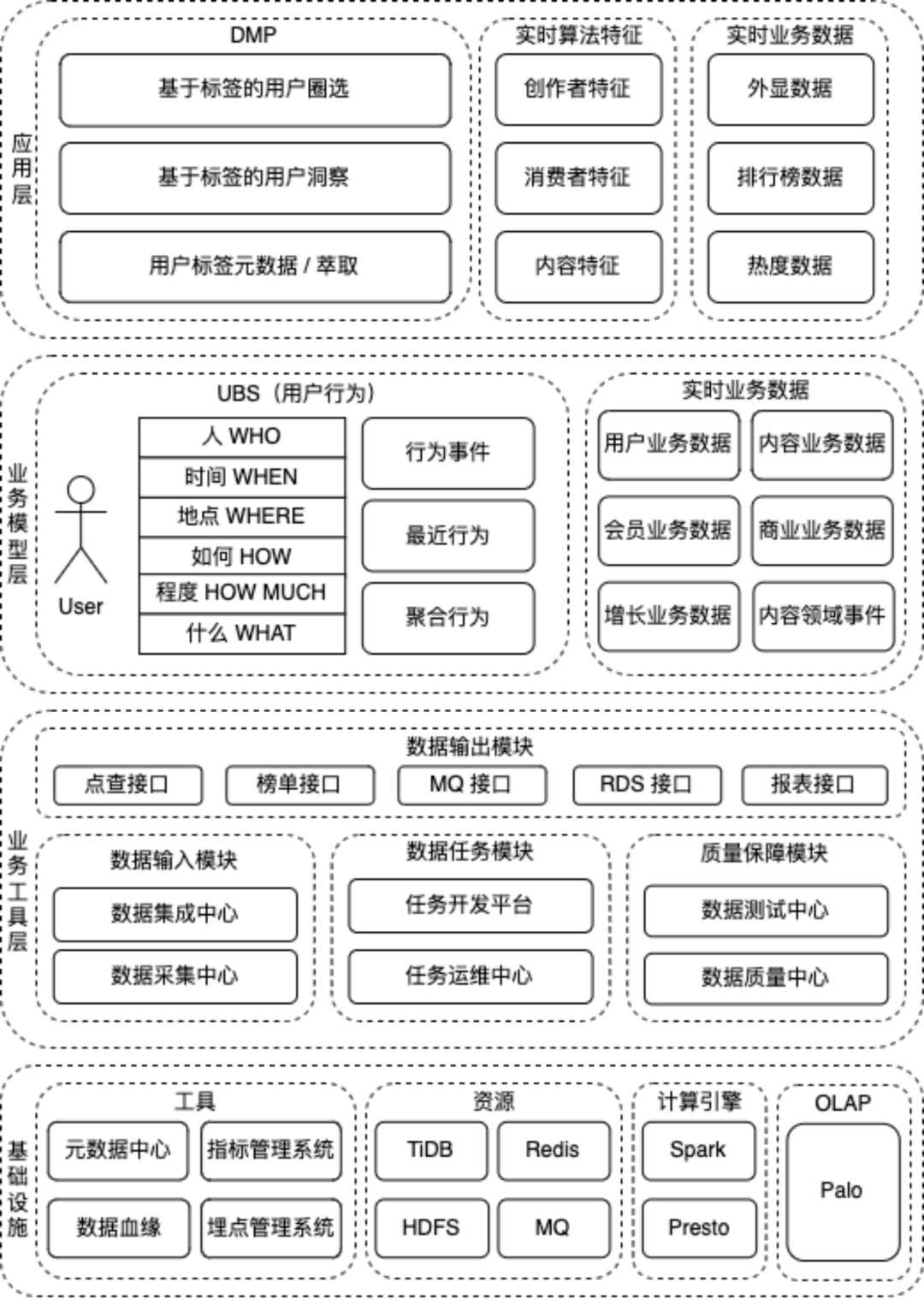
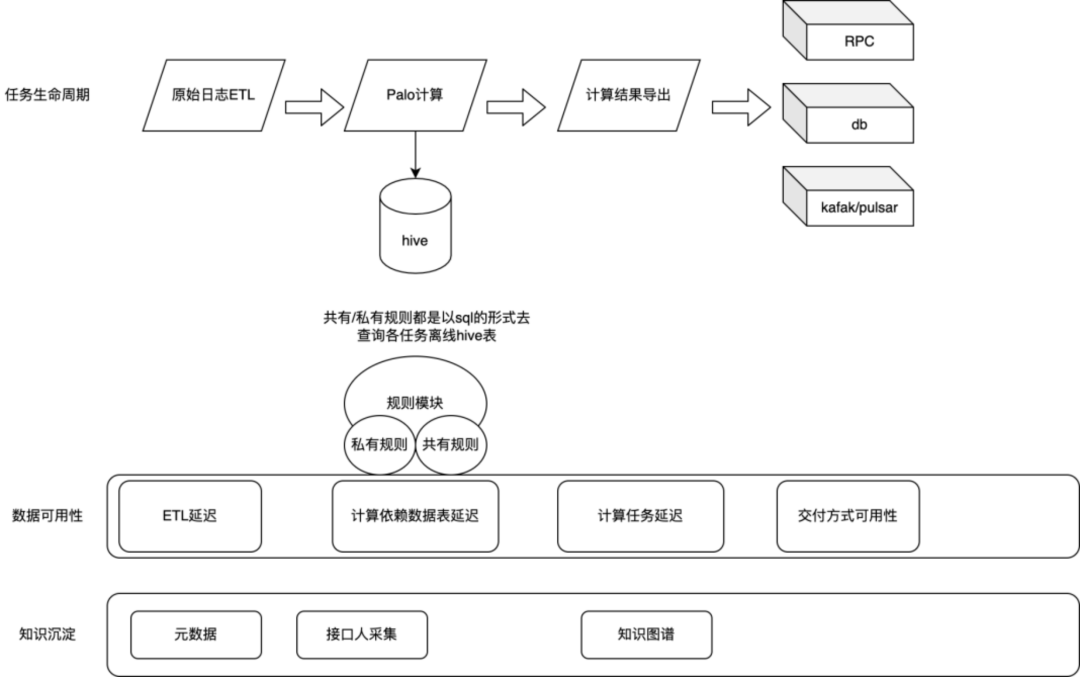
解决当前问题的数据架构,一般有 Lambda 架构和 Kappa 架构。针对当前业务特点,计算复杂、偶发的异常问题需要大数据量回溯等特性。当前实时数据的数据架构采用的是 Lambda 架构。大数据架构系列 -- Lambda架构初体验。由 Doris 承载分钟级的批处理,Flink 来承载秒级别简单逻辑的流处理。具体如下:
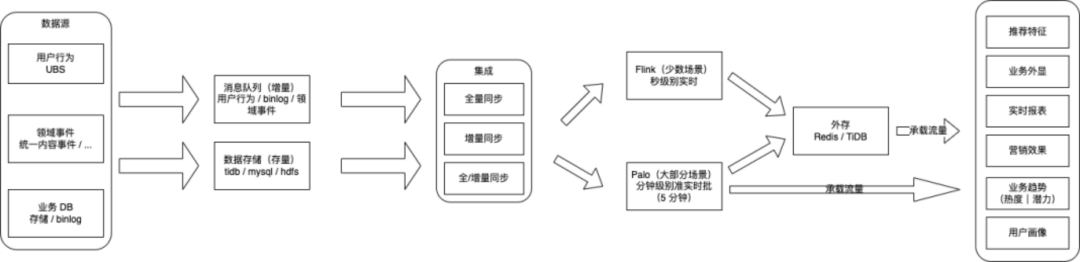
(1)实时业务数据。
通过提供实时的业务指标,解决业务对热点、潜力的把控,助力生产、消费,提 升优质创作量及内容消费能力。
提供实时的复杂计算的外显指标,加强用户体验,解决业务侧通过后端脚本计算的高维护成本和复杂性,节约成本,提升人效。
(2)实时算法特征。
以实时数据为基础,提供多样的实时算法特征,与推荐算法团队共同提升 DAU、留存、用户付费等核心指标。
02 面临的困难
(1) 依赖数据源多,计算规则复杂。以我们的播放量计算为例:
行为有多条,需要针对行为进行去重。
过滤和加和规则很多,需要依赖多个数据源的不同数据结果进行计算。
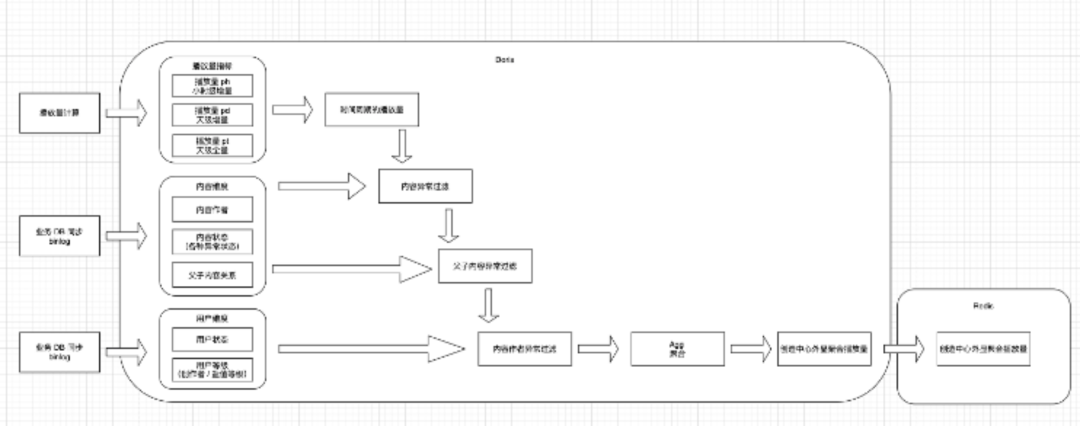
以算法特征为例,用户浏览某内容后,针对后续关联的一系列计算后,需要在一定时间内产出计算结果(10min 未产出后续推荐效果会有波动,26min 该特征的效果会降为 0)
需要调度系统中,同时能识别 kafka 流消费的进度和任务完成情况。
需要严格拉齐多个依赖的消费进度,当达到统一进度后,集中进行后续任务计算。
03 解决方案
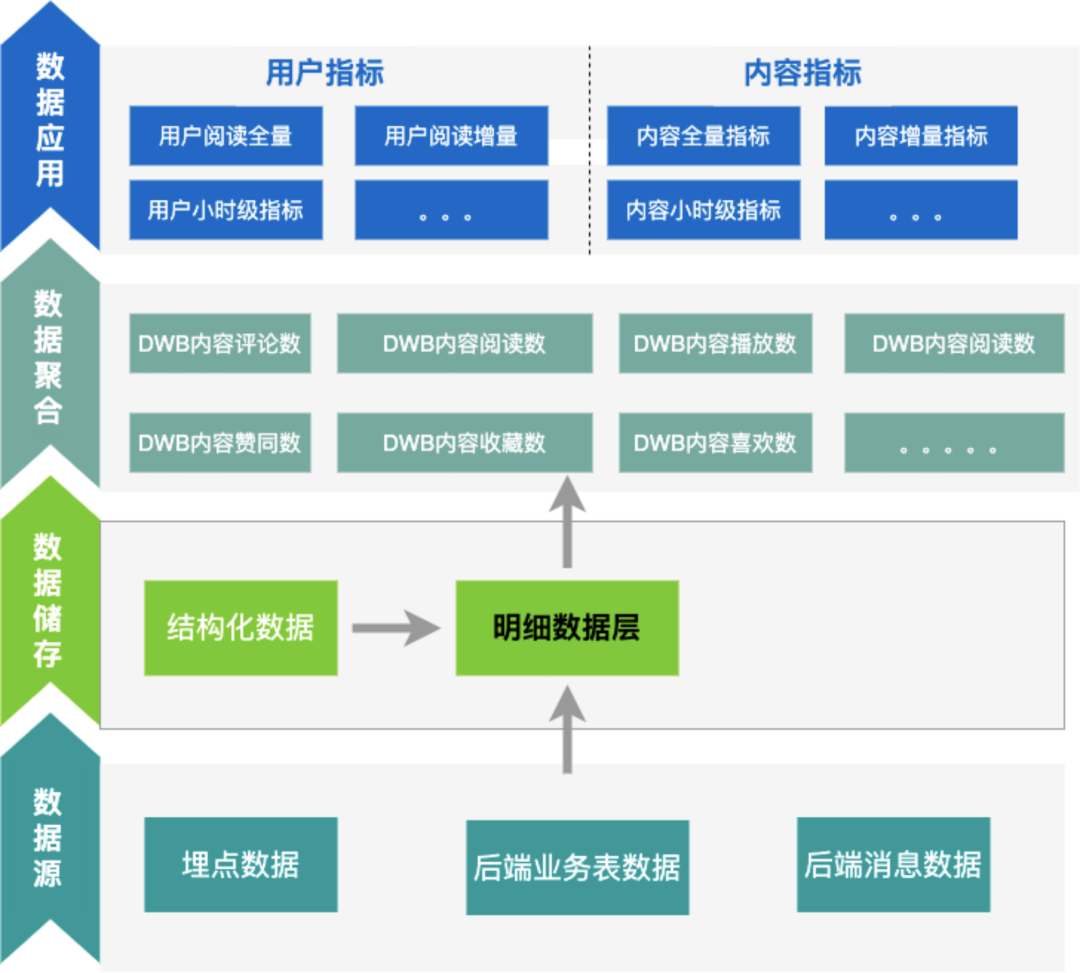
通过建设实时数据集成和实时数据调度的能力,保障数据接入和数据模型建设的速度,降低接入时间,提升业务接入效率(具体见下方)
通过建设实时数据质量中心,保障数据质量,降低发现数据质量问题的时间,提升发现效率,保证业务交付结果(具体见下方)
搭建写入延迟、计算延迟等监控,快速发现问题。
Doris 集群进行参数变更,调整批量写入的数据量、时间和频率等进行优化。 当前我们的 Load 主要有 Broker Load 和 Routine Load。其中时效性要求高的是 Routine Load。我们针对性的进行了参数调整。 Doris 增加了 Runtime Filter,通过 BloomFilter 提升 Join 性能。 Doris 集群在 0.14 版本中加入了 Runtime Filter 的过滤,针对 Join 大量 key 被过滤的情况有明显提升; 该变更针对我们当前的几个业务调度性能,有明显提升。时间从 40+s 提升至 10s 左右;
(1)用户检索。
重点在于快速完成人群包圈选同时在圈选条件变更过程中,需要快速计算出预计能圈的用户有哪些?
(2)用户分析。
重点在于多人群包的各个维度对比分析,通过分析结论找到最明显的用户特征(通过 TGI 值判断)
02 面临的困难
(1)数据规模大。
我们当前是 200+ 个标签,每个标签均有不同的枚举值,总计有 300+ 万的 tag。tag 对用户的打标量级在 900+ 亿条记录。由于标签每日更新导入量级十分大。
(2)筛选响应时间要求高。
(3)人群包除了 long 类型的用户 id 外,还需要有多种不同的设备 id 和设备 id md5 作为筛选结果。
(4)用户分析场景下,针对 300+ 万 tag 的多人群交叉 TGI 计算,需要在 10min 内完成。
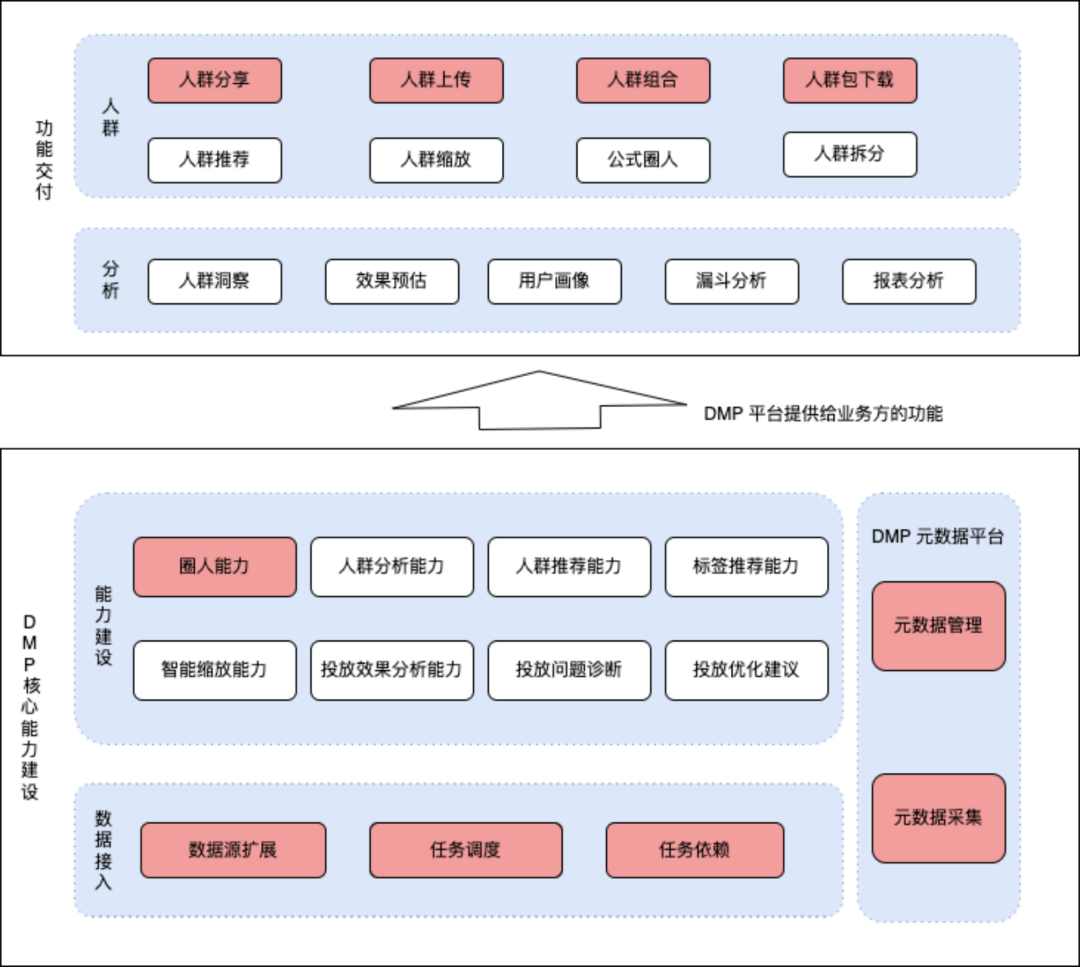
(2)DMP 业务流程:
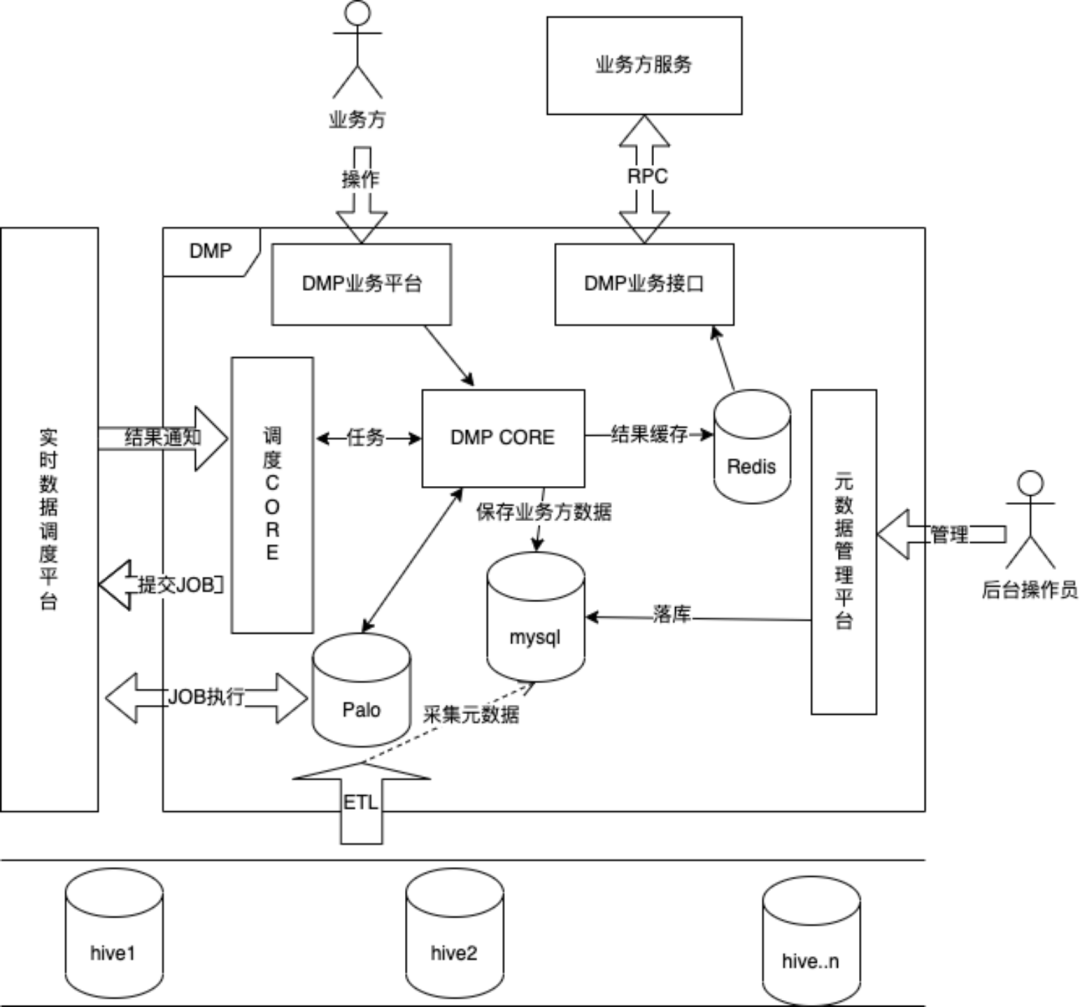
(3)性能问题针对性解决;数据规模大,提升导入性能,分而治之。
数据模型变更,拆分文件。
Doris 的存储是按照 Tablet 分散在集群上的。通过调整数据模型,确保分布均匀及每个文件尽可能的小。
导入变更,拆分导入。
由于每个 Broker Load 导入都是有性能瓶颈的,将 900+ 亿行数据,拆分为 1000+ 个 Broker Load 的导入任务,确保每个导入总量都足够小。
(4)提升人群筛选和人群分析的计算速度,分而治之。
业务逻辑变更,拆分用户。
将用户每 0 ~ 100 万拆分为一组。
针对全部用户的交并差,等价于对所有组用户交并差后的并集。
针对全部用户的交并差的总数,等价于对分组用户交并差后的总数进行 sum。
数据模型变更,拆分文件。
设置 bitmap 的分组参数,将分组设置为 colocate group。确保每个分组的交并差计算均在自己所在 BE 完成,无需 shuffle。
将 bitmap 表的分桶拆分更多,通过更多文件同时计算加速结果。
计算参数变更,提升并发。
由于计算过程通过分治的手段,拆分为多个小任务。通过提升并行度 parallel_fragment_exec_instance_num 再进一步优化计算速度。
上线后,接入了知乎多个主要场景的业务,支持多业务方的人群定向和分析能力。为业务带来曝光量、转化率等直接指标的提升。
同时在工具性能上,有如下表现:
导入速度。当前每日 900+ 亿行数据,在 3 小时内完成导入。
人群预估。人群预估基本可在 1s 内完成,P95 985ms。
人群圈选。人群圈选过程在 5s 内完成,整体圈人在 2min 左右。(待提升中介绍)
人群分析。人群分析过程在 5min 内完成。
缺乏定制的人群扩散能力。多业务场景对已有人群进行扩散有复杂且多样的需求。
缺乏用户人群染色,无法再多个环节完成用户效果的回收和进行后续的分析。
(2)性能提升
当前 Doris 的行列转换功能在建设中。在用户画像业务中,将用户 id 更换为设备 id,人群缩减(将具体人群包缩减为一个比较小的人群包用于后续运营动作)过程是通过业务代码实现的,降低了性能。 >> 后续结果由行列转换后,用户画像结果处理流程中会将设备 id 获取方式通过 join 维度表来实现,人群缩减通过 order by rand limit 来实现,会有比较明显的性能提升。当前 Doris 的读取 bitmap 功能在建设中。业务代码无法读取到 bitmap,只能先通过 bitmap_to_string 方法读取到转换为文本的 bitmap,加大了传输量,降低了圈选性能。 >> 后续可以直接读取 bitmap 后,业务逻辑中会替换为直接获取 bitmap,会极大程度的减少数据传输量,同时业务逻辑可以针对性缓存。针对人群预估逻辑,当前是通过例如 bitmap_count(bitmap_and) 两个函数完成的,后续 Doris 会提供 bitmap_and_count 合并为一个函数,替换后可提升计算效率。
3.4 工具层建设经验分享
3.4.1 数据集成
01 业务场景
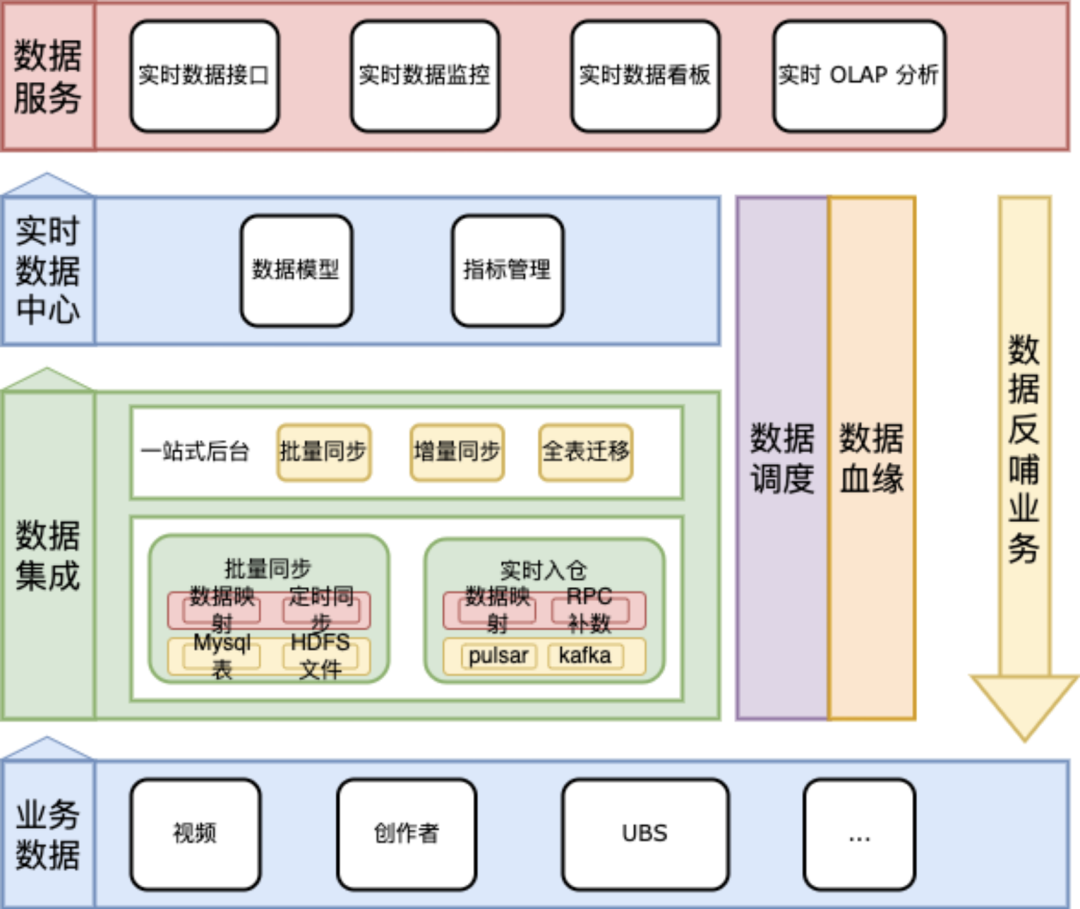
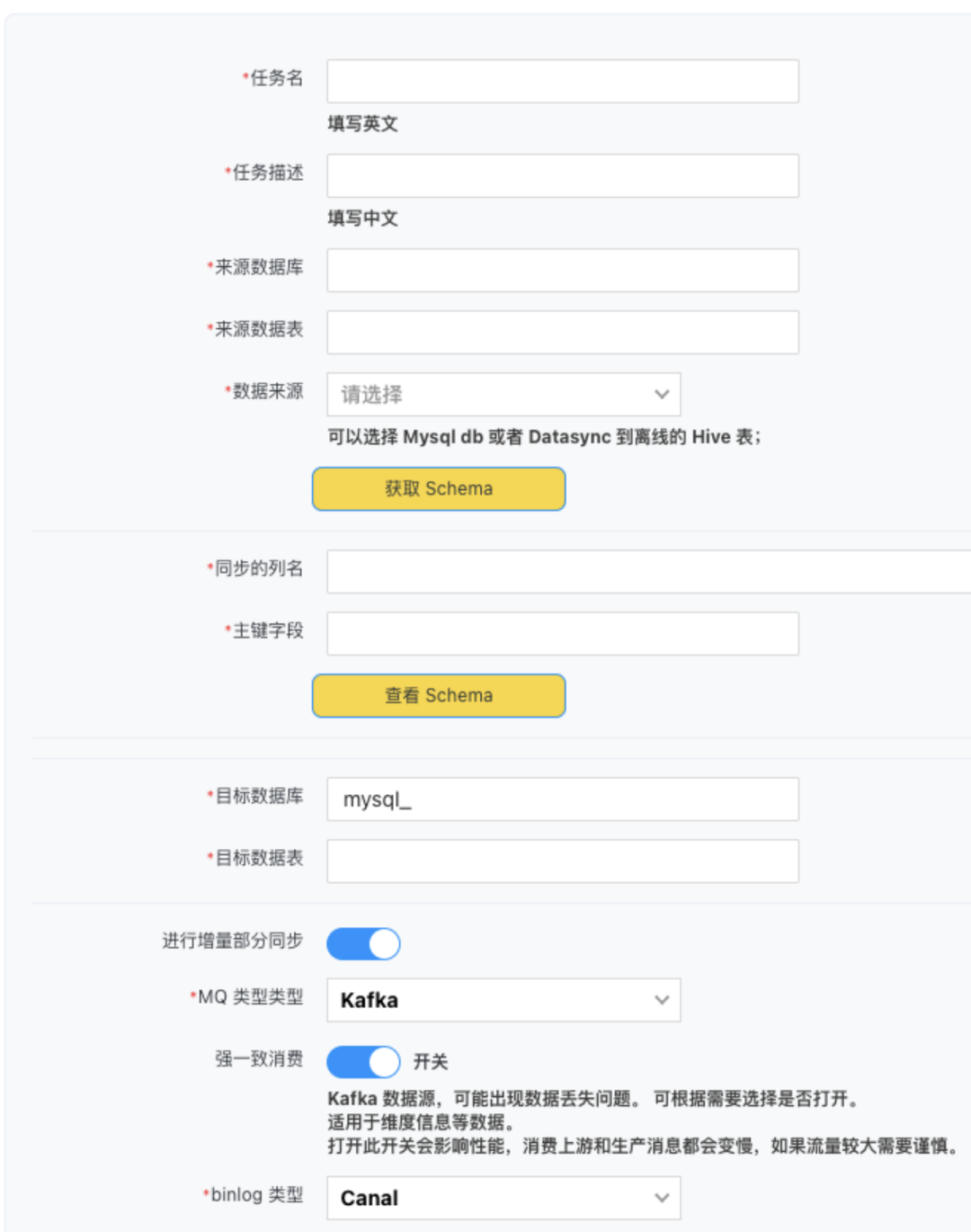

早期使用 Doris 开发实时数据业务过程中,由于需要某个数据全/增量同步,同时进行数据转换。需要建 Doris 数据模型,完成全量数据导入,建设增量数据 ETL 和 Routine Load 等开发,需要 1 名工程师 1 天才能将一张表接入到 Doris 中并进行全增量实时同步。
中间链路多,缺乏报警,针对重要的链路,建设打点和报警成本高,需要 0.5 天左右。
全量:原始数据库 TiDB -> 中间部分(DataX)-> Doris
增量:原始数据库 TiDB -> TiCDC -> Canal Binlog Kafka -> ETL(填充数据)-> Kafka -> Routine Load -> Doris
仅需要 10min 的配置,数据集成包含模型,数据导入及中间 ETL 的转化和额外数据补充以及 Routine Load 全部建好。业务层无需感知数据中间链路,仅需要描述我期望那个表被同步。
上线后无需业务关心,完成第一步配置后,后续的监控和报警以及一致性,集成全面解决。
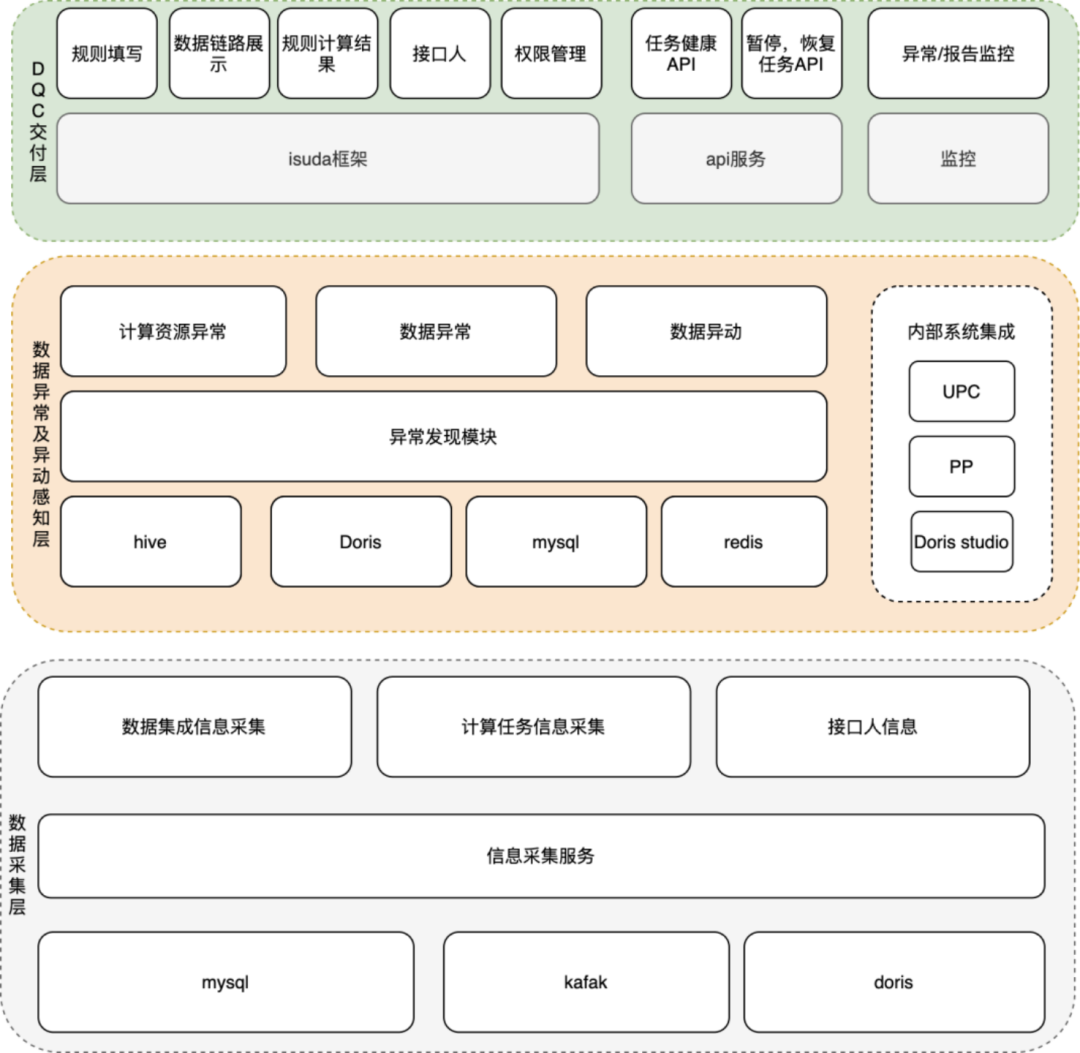
我们在初期通过 Doris 建设实时数据的过程中,是通过 Routine Load 后的数据,再定时任务执行后续计算逻辑,后再将计算结果导出到承载存储,如 Redis、Zetta(知乎自研 HBase 协议) 中完成外部压力承载。在这个过程中遇到了如下问题:
(1)依赖未就绪后续任务就执行。如最近 24 小时的曝光,在 15:05 运行昨日 15:00至今日 15:00 的查询。此时如果 Routine Load 仅导入到 14:50 的数据,这次执行结果异常;
(2)Doris 资源有限,但很多任务都是某些整点整分钟的,一次性大量的计算任务造成集群崩溃;
(3) 任务是否执行成功,任务是否延迟,是否影响到业务,无报警无反馈;
(4) 导出存储过程通用,重复代码开发,每次都需要 0.5 - 1 人天的时间开发写入和业务接口。
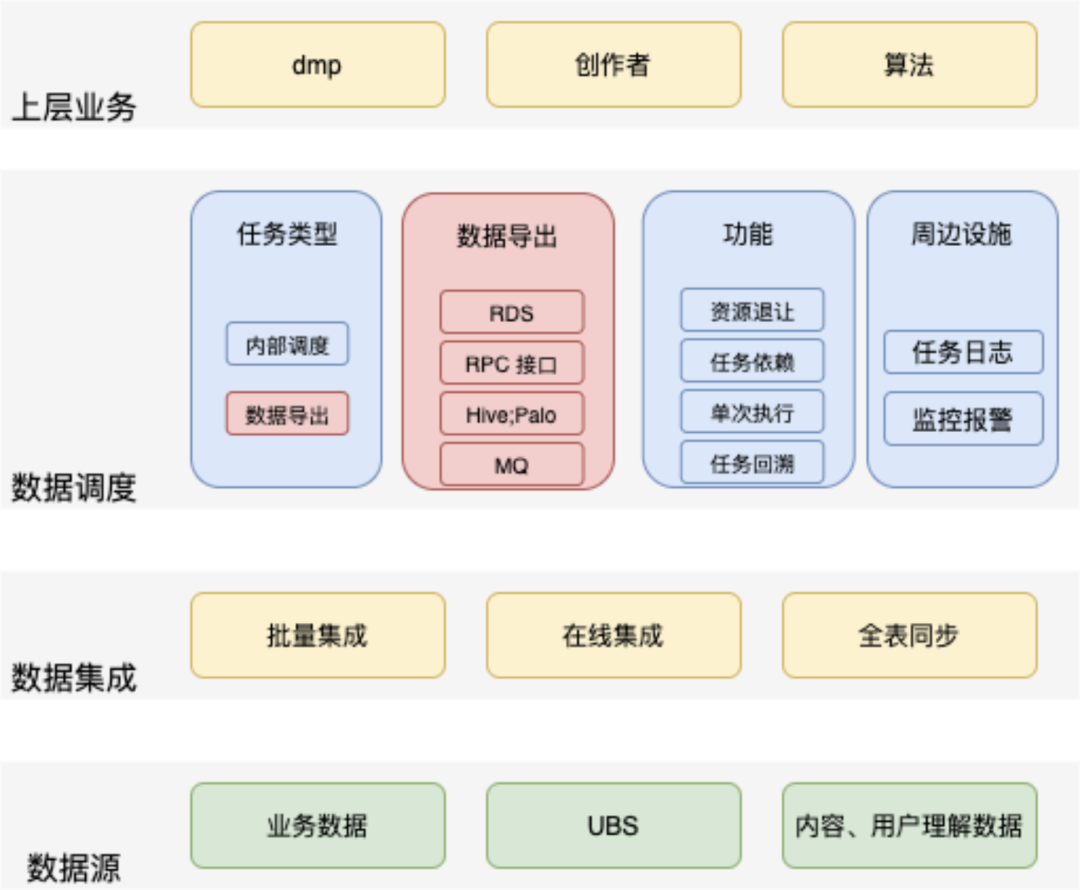
(2)流程图
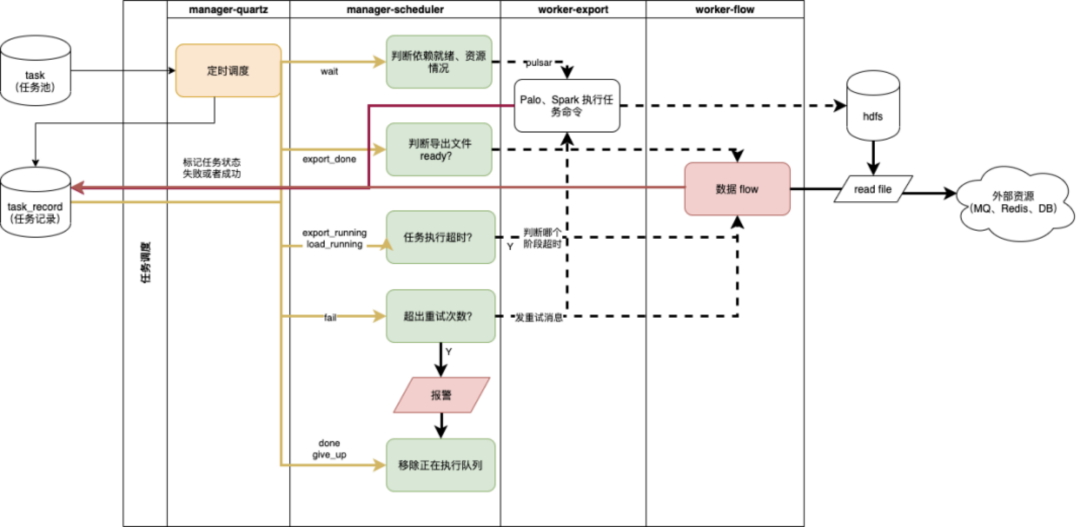
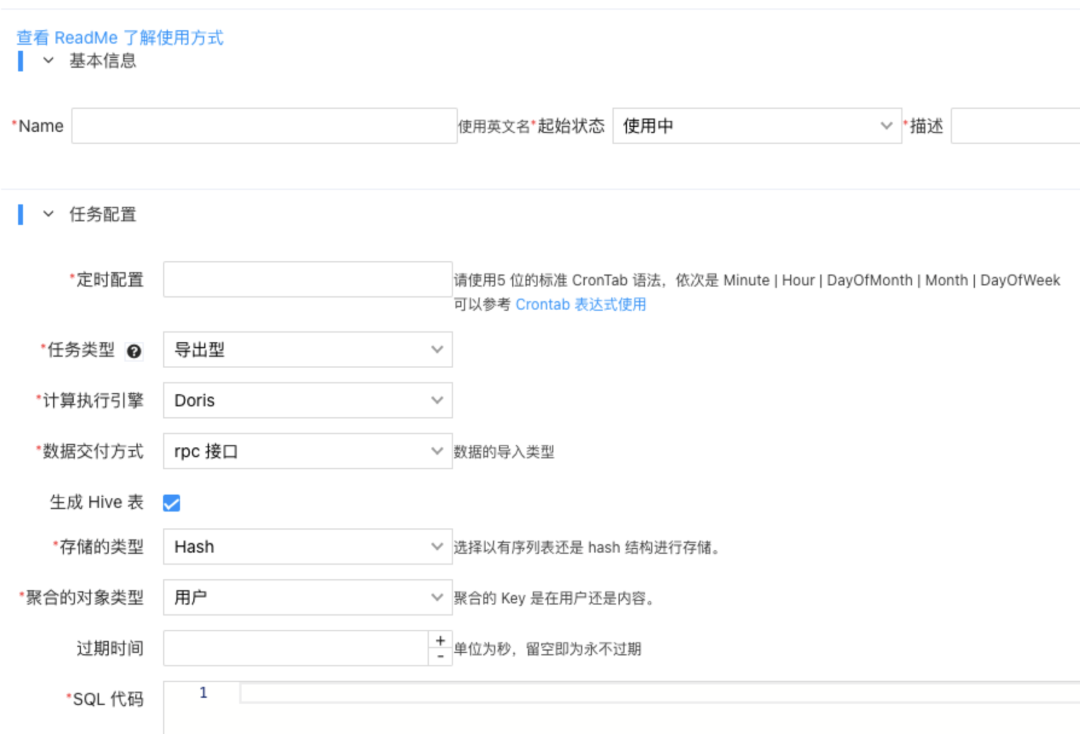
建立任务依赖机制,通过 kafka 的 offset 和前置表是否完成计算,判断当前计算任务能否执行。后续再也没有出现过数据还未导入就先开始进行数据计算的情况。 通过退让策略,监控当前 Doris 指标,在高负载情况下避免提交 SQL。避峰趋谷,完成资源最大利用。后续通过这种方案,一定程度的避免了瞬时跑高整体集群的问题。 全链路监控任务执行情况,和延迟情况,一旦延迟报警,及时沟通解决和恢复业务。一旦任务延迟,监控可非常快速的发现相关问题,多数情况能在业务可接受范围内完成恢复。 上线后,原先需要 1 天的工程能力开发时间降低至 0。只需要在 Doris 中有一个可查询的 SQL,经过简单配置即可完成一定时间交付给业务相关数据、排行榜的需求。
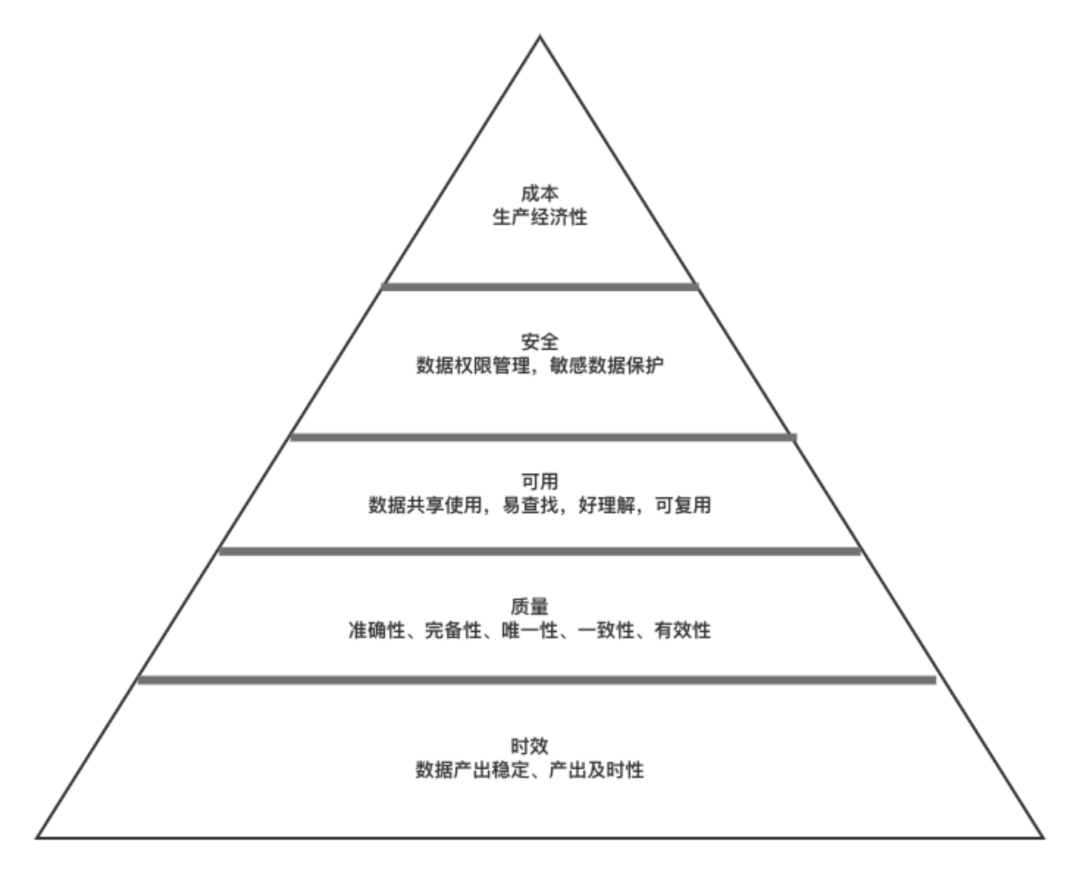
(1)完整性:数据完整性问题包括:模型设计不完整,例如:唯一性约束不完整、参照不完整;数据条目不完整,例如:数据记录丢失或不可用;数据属性不完整,例如:数据属性空值。不完整的数据所能借鉴的价值就会大大降低,也是数据质量问题最为基础和常见的一类问题;
(2)一致性: 多源数据的数据模型不一致,例如:命名不一致、数据结构不一致、约束规则不一致。数据实体不一致,例如:数据编码不一致、命名及含义不一致、分类层次不一致、生命周期不一致……相同的数据有多个副本的情况下的数据不一致、数据内容冲突的问题;
(3)准确性: 准确性也叫可靠性,是用于分析和识别哪些是不准确的或无效的数据,不可靠的数据可能会导致严重的问题,会造成有缺陷的方法和糟糕的决策;
(4)唯一性:
用于识别和度量重复数据、冗余数据。重复数据是导致业务无法协同、流程无法追溯的重要因素,也是数据治理需要解决的最基本的数据问题;
(5)关联性: 数据关联性问题是指存在数据关联的数据关系缺失或错误,例如:函数关系、相关系数、主外键关系、索引关系等。存在数据关联性问题,会直接影响数据分析的结果,进而影响管理决策;
(6)真实性:
数据必须真实准确的反映客观的实体存在或真实的业务,真实可靠的原始统计数据是企业统计工作的灵魂,是一切管理工作的基础,是经营者进行正确经营决策必不可少的第一手资料;
(7)及时性:
数据的及时性是指能否在需要的时候获到数据,数据的及时性与企业的数据处理速度及效率有直接的关系,是影响业务处理和管理效率的关键指标。

03 效果
(2)某任务中间逻辑监控
该任务中间计算中其中部分规则未达标,导致该任务未通过。

早期无类似 DQC 系统保证的前提下,我们很多问题都是天级别甚至上线后,才发现存在数据异常,出现过 3 次问题,造成的返工和交付不靠谱的情况,对业务影响巨大。 早期开发中,在开发过程需要不断针对各种细节规则进行比对,总会花费一定时间逐层校验,成本巨大。
(2)上线后
在上线 1 个月内,通过 DQC 系统规则,当前已发现了 14 个错异常,在 1 - 2h 左右发现,立即修复。对业务的影响降低到最小。
在系统上线后,在开发过程中,开发完相关数据,如有异常,就产生了异常报警,大幅节省了人工发现的成本,因为修复时间早,在后续开发启动前,就已经修复,极大程度降低开发过程中的返工成本。
四、总结与展望
01 针对实时业务数据
提供了基于时效性的热点、潜力的把控。加速业务在生产、消费方面的使用,进而提升优质创作量及用户对内容消费能力。 同时提供了提供实时的复杂计算的外显指标,加强用户体验,下线了业务后端通过脚本计算指标的方法,降低了业务的复杂性,节约了成本,提升人效。
02 针对实时算法特征
提供了基于创作者、内容、消费者的实时算法特征,与算法团队共同在多个项目中,针对 DAU、留存、用户付费等核心指标有了明显的提升。
完善和升级用户筛选,做到多维、多类型的定向筛选,并接入了运营平台、营销平台等系统,提高了业务效率,降低了业务人员进行人群定向的成本。 搭建和完善用户分析,做到多角度用户分析,定向用户分析报告 0 成本,助力业务部门快速把握核心客户市场。
4.1.2 工具建设方面
完成了实时数据领域和用户领域的布局,建设了相关的开发和维护工具,解决了先前在此方面无基础设施,无业务工具,开发成本高的问题。
搭建了集成、调度、质量系统。通过工具的方式降低了业务发展和迭代的成本,让业务快速发展,同时也保证了交付质量提高了业务基线。
4.1.3 人员组织方面
自上而下的拆分了实时数据和用户画像的能力,分为应用层、业务模型层、业务工具层和基础设施层。通过组织划分,明确了不同层次的边界和加速了业务目标的达成。
搭建并完善了多层次团队人员梯队。根据针对不同方向的同学,给予不同的 OKR 目标,做到跨层次方向隔离,同层次方向一致,同模块目标一致。共同为整体实时数据与用户画像服务建设而努力。
强化基础能力工具层的建设,持续降低基于实时数据方面的建设、交付成本。
提升数据质量工具覆盖能力,为业务模型提供质量保障,并提供基于实时数据的画像质量保障能力。
基于当前业务诉求,部分场景针对 5 分钟级实时无法满足,进一步探索秒级别复杂情况实时能力,并提供能力支持。
加强并针对用户画像、用户理解、用户洞察 & 模型等进一步建设。通过与具体业务结合,建设贴合业务场景的用户理解成果和相应的分析能力,找到业务的留存点。
进一步加强新的工具能力的建设,通过建设用户理解工具、用户分析工具,降低产生理解及对业务分析的成本,提升业务效率,快速发现业务价值。
推荐阅读: