
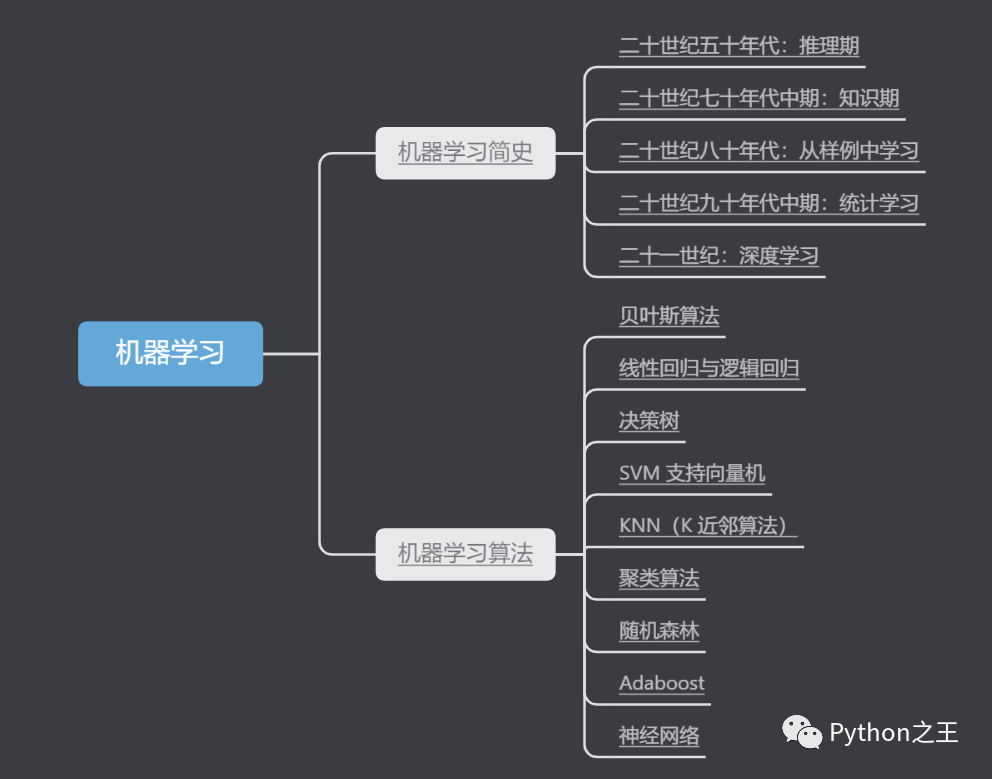
机器学习简史和常用算法的梳理
原文:https://maoli.blog.csdn.net/article/details/115803729
符号主义学习
连接主义学习
贝叶斯算法
线性回归与逻辑回归
决策树
SVM 支持向量机
KNN(K 近邻算法)
聚类算法
随机森林
Adaboost
神经网络
机器学习简史
机器学习是人工智能研究发展到一定阶段的必然产物,本章仅从笔者的视角对机器学习这五十年来的发展进行一个略述,疏漏错误之处烦请指正。下面这幅漫画中就展示了一个无奈的问题,三岁幼童可以轻松解决的问题却需要最顶尖的科学家花费数十年的光阴,或许机器学习离我们在电影里看到的那样还有很长一段路要走。
知识来源于哪里?知识来源于进化、经验、文化和计算机。对于知识和计算机的关系,可以引用 Facebook 人工智能实验室负责人 Yann LeCun 的一段话:将来,世界上的大部分知识将由机器提取出来,并且将长驻与机器中。而帮助计算机获取新知识,可以通过以下五种方法来实现:
填充现存知识的空白
对大脑进行仿真
对进化进行模拟
系统性的减少不确定性
注意新旧知识之间的相似点
对应以上这几种知识获取的途径,我们可以认为常见的人工智能的方向有:
| 派别 | 起源 | 擅长算法 |
|---|---|---|
| 符号主义(Symbolists) | 逻辑学、哲学 | 逆演绎算法(Inverse deduction) |
| 联结主义(Connectionists) | 神经科学 | 反向传播算法(Backpropagation) |
| 进化主义(Evolutionaries) | 进化生物学 | 基因编程(Genetic programming) |
| 贝叶斯派(Bayesians) | 统计学 | 概率推理(Probabilistic inference) |
| Analogizer | 心理学 | 核机器(Kernel machines) |
二十世纪五十年代:推理期
二十世纪五十年代到七十年代初,人工智能研究处于”推理期“,彼时人们以为只要能赋予机器逻辑推理的能力,机器就能具有智能。这一阶段的代表性作品有 A. Newell 和 H. Simon 的“逻辑理论家”程序,该程序于 1952 年证明了罗素和怀特海的名著《数学原理》中的 38 条定理,在 1963 年证明了全部的 52 条定理。不过随着时间的发展,人们渐渐发现仅具有逻辑推理能力是远远实现不了人工智能的。
二十世纪七十年代中期:知识期
从二十世纪七十年代中期开始,人工智能研究进入了“知识期”,在这一时期,大量的专家系统问世,在很多应用领域取得了大量成果。在本阶段诞生的技术的一个鲜明的代表就是模式识别,它强调的是如何让一个计算机程序去做一些看起来很“智能”的事情,例如识别“3”这个数字。而且在融入了很多的智慧和直觉后,人们也的确构建了这样的一个程序。从这个时代诞生的模式识别领域最著名的书之一是由 Duda & Hart 执笔的“模式识别(Pattern Classification)”。对基础的研究者来说,仍然是一本不错的入门教材。不过对于里面的一些词汇就不要太纠结了,因为这本书已经有一定的年代了,词汇会有点过时。自定义规则、自定义决策,以及自定义“智能”程序在这个任务上,曾经都风靡一时。有趣的是笔者在下文中也会介绍如何用深度学习网络去识别手写的数字,有兴趣的朋友可以去探究下使用模式识别与深度学习相比,同样是识别手写数字上的差异。
不过,专家系统面临“知识工程瓶颈”,即由人来把知识总结出来再教给计算机是相当困难的,于是人们开始考虑如果机器能够自己学习知识,该是一件多么美妙的事。
二十世纪八十年代:从样例中学习
R.S.Michalski 等人将机器学习分为了“从样例中学习”、“在问题求解和规划中学习”、“通过观察和发现学习”、“从指令中学习”等类别;E.A.Feigenbaum 等人在著作《人工智能手册》中,则把机器学习划分为了“机械学习”、“示教学习”、“类比学习”和“归纳学习”。机械学习又被称为死记硬背式学习,即把外界输入的信息全部记录下来,在需要时原封不动地取出来使用,这实际上没有进行真正的学习,仅仅是在进行信息存储和检索;示教学习和类比学习类似于 R.S.Michalski 等人所说的从指令中学习和通过观察和发现学习。归纳学习则相当于从样例中学习,即从训练样本中归纳出学习结果。二十世纪八十年代以来,被研究最多、应用最广的是“从样例中学习”,也就是广泛的归纳学习,它涵盖了监督学习、无监督学习等。
符号主义学习
在二十世纪八十年代,从样例中学习的一大主流就是符号主义学习,其代表包括决策树和基于逻辑的学习。符号学习一个直观的流程可以参考下图:
典型的决策树学习以信息论为基础,以信息熵的最小化为目标,直接模拟了人类对概念进行判定的树形流程。基于逻辑的学习的著名代表是归纳逻辑程序设计 Inductive Logic Programming,简称 ILP,可以看做机器学习与逻辑程序设计的交叉。它使用一阶逻辑,即谓词逻辑来进行知识表示,通过修改和扩充逻辑表达式来完成对于数据的归纳。符号主义学习占据主流地位与前几十年人工智能经历的推理期和知识期密切相关,最后,可以来认识几位符号主义的代表人物:
连接主义学习
二十世纪九十年代中期之前,从样例中学习的另一主流技术是基于神经网络的连接主义学习。下图就是典型的神经元、神经网络与著名的 BP 算法的示例。
与符号主义学习能产生明确的概念表示不同,连接主义学习产生的是黑箱模型,因此从知识获取的角度来看,连接主义学习技术有明显弱点。然而,BP 一直是被应用的最广泛的机器学习算法之一,在很多现实问题上发挥作用。连接主义学习的最大局限是其试错性。简单来说,其学习过程设计大量的参数,而参数的设置缺乏理论指导,主要靠手工调参;夸张一点来说,参数调节上失之毫厘,学习结果可能谬以千里。
二十世纪九十年代中期:统计学习
二十世纪九十年代中期,统计学习闪亮登场并且迅速占据主流舞台,代表性技术是支持向量机(Support Vector Machine)以及更一般的核方法(Kernel Methods)。正是由于连接主义学习技术的局限性凸显,人们才把目光转向以统计学习理论为直接支撑的统计学习技术。
二十一世纪:深度学习
深度学习掀起的热潮也许大过它本身真正的贡献,在理论和技术上并没有太多的创新,只不过是由于硬件技术的革命,计算机的速度大大提高了,使得人们有可能采用原来复杂度很高的算法,从而得到比过去更精细的结果。
二十一世纪初,连接主义学习又卷土重来,掀起了以深度学习为名的热潮。所谓深度学习,狭义的说就是“很多层”的神经网络。在若干测试和竞赛上,尤其是涉及语音、图像等复杂对象的应用中,深度学习技术取得了优越性能。之前的机器学习技术在应用中要取得好的性能,对于使用者的要求较高。而深度学习技术涉及的模型复杂度非常高,以至于只要下功夫“调参”,把参数调节好,性能往往就好。深度学习虽然缺乏严格的理论基础,但是显著降低了机器学习应用者的门槛,为机器学习走向工程实践带来了便利。深度学习火热的原因有:
数据大了,计算能力抢了,深度学习模型拥有大量参数,若数据样本少,则很容易过拟合。
由于人类进入了大数据时代,数据储量与计算设备都有了大发展,才使得连接主义学习技术焕发了又一春。
机器学习算法
算法基本上从功能或者形式上来分类。比如,基于树的算法,神经网络算法。这是一个很有用的分类方式,但并不完美。因为有许多算法可以轻易地被分到两类中去,比如说 Learning Vector Quantization 就同时是神经网络类的算法和基于实例的方法。正如机器学习算法本身没有完美的模型一样,算法的分类方法也没有完美的。
常用算法
下面我们对机器学习中常见的算法及其特征与使用场景进行简单梳理。
贝叶斯算法
贝叶斯算法是给予贝叶斯定理与特征条件独立假设的监督型分类方法,典型的算法有朴素贝叶斯、高斯朴素贝叶斯、多种名义朴素贝叶斯、平均单依赖估计、BBN、BN 等。该算法要求各特征间相互独立,对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。其典型的运用场景包括了:
文本分类 疾病预测 检测 SNS 社区中不真实账号 垃圾邮件过滤
线性回归与逻辑回归
线性回归的目的在于找出某一变量与其他多个变量之间的定量关系,并且是线性关系;逻辑回归则是将数据拟合到一个 logit 函数(或者叫做 logistic 函数)中,从而能够完成对事件发生的概率进行预测。线性回归模型太简单,如果数据呈线性关系可采用;逻辑回归相对来说模型更简单,好理解,实现起来,特别是大规模线性分类时比较方便。同样的线性分类情况下,如果异常点较多的话,无法剔除,首先 LR,LR 中每个样本都是有贡献的,最大似然后会自动压制异常的贡献。
决策树
决策树是利用训练数据集来构造决策树,用构造好的决策树对将来的新数据进行分类的监督型算法,典型的算法有 ID3、ID4、ID5、C4.0、C4.5、C5.0、CART 等,其常用于二元或者多元分类。该算法要求变量只能数值型、名称型,其核心概念中涉及信息熵、信息增益,在构造决策树时,实际上是选择信息增益 Max 的属性作为决策节点;算法 C4.5 引入来信息增益率的概念。决策树常用于以下场景:
金融行业用决策树做贷款风险评估 保险行业用决策树做推广预测 医疗行业用决策树生成辅助诊断处置模型 用户分级评估 分析对某种响应可能性影响最大的因素,比如判断具有什么特征的客户流失概率更高 为其他模型筛选变量。决策数找到的变量是对目标变量影响很大的变量。所以可以作为筛选变量的手段。
SVM 支持向量机
SVM 同样是监督型分类算法,基本想法就是求解能正确划分训练样本并且其几何间隔最大化的超平面。线性支持向量机既可以解决线性可分问题,又可以解决线性不可分问题。其构建过程如下:获取训练输入,将其映射至多维空间,使用回归算法找到可最佳分离两类输入数据的超平面(超平面是一个在 n 维空间中将空间划分为两个半空间的一个平面)。一旦支持向量机完成了受训,它就可以评估有关划分超平面的新输入数据,并将划分为其中一类,在 SVM 分类决策中起决定作用的是支持向量。
SVM 常用于模式识别领域中的文本识别,中文分类,人脸识别等;工程技术和信息过滤。
KNN(K 近邻算法)
KNN 是监督型分类算法,通过测量不同特征值之间的距离进行分类。它的的思路是:如果一个样本在特征空间中的 K 个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。K 通常是不大于 20 的整数。KNN 算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
KNN 要求事先要有正确样本,算法比较简单,完全依赖于数据,没有数学模型,所以应用在很简单的模型。其易于理解,易于实现,无需估计参数,无需训练;适合对稀有事件进行分类,特别适合于多分类问题(multi-modal,对象具有多个类别标签),KNN 比 SVM 的表现要好。不过当样本不平衡时,抗造能力差,并且计算量大。
KNN 的典型应用场景譬如约会网站的数据分类,或者手写数字识别。
聚类算法
聚类将数据集中的样本划分为若干个不相交的子集,每个子集可能对应一个潜在的类别,这些类别对聚类算法是未知的。其典型算法有 K-means,LVQ,高斯混合聚类,密度聚类,层次聚类等。聚类算法不需要训练集。
随机森林
随机森林是监督型分类算法,顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
随机森林主要包含了采样(有放回的采样)与完全分裂(叶子节点要么无法再分裂,要么要么里面的所有样本的都是指向的同一个分类)等步骤。随机森林对多元公线性不敏感,结果对缺失数据和非平衡的数据比较稳健,可以很好地预测多达几千个解释变量的作用;在数据集上表现良好,两个随机性的引入,使得随机森林不容易陷入过拟合。
在当前的很多数据集上,相对其他算法有着很大的优势,两个随机性的引入,使得随机森林具有很好的抗噪声能力。它能够处理很高维度(feature 很多)的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化。可生成一个 Proximities=(pij)矩阵,用于度量样本之间的相似性:, aij 表示样本 i 和 j 出现在随机森林中同一个叶子结点的次数,N 随机森林中树的颗数。
在创建随机森林的时候,对 generlization error 使用的是无偏估计,训练速度快,可以得到变量重要性排序(两种:基于 OOB 误分率的增加量和基于分裂时的 GINI 下降量,在训练过程中,能够检测到 feature 间的互相影响,容易做成并行化方法,实现比较简单。
Adaboost
Adaboost 是监督型聚合式分类算法,和随机森林有点像,区别在于随机森林是并行,Adaboost 是串行,上一个分类器的结果放入下一个分类器。Adaboost 最后的分类器 YM 是由数个弱分类器(weak classifier)组合而成的,相当于最后 m 个弱分类器来投票决定分类,而且每个弱分类器的话语权 α 不一样。
Adaboost 常用于二分类或多分类的应用场景,用于做分类任务的 baseline 无脑化,简单,不会 overfitting,不用调分类器。还可以用于特征选择(feature selection)。并且 Boosting 框架用于对 badcase 的修正,只需要增加新的分类器,不需要变动原有分类器。
神经网络
人工神经网络算法模拟生物神经网络,是一类模式匹配算法。一般分为输入层、隐藏层、输出层,隐藏层的层数根据算法需要来定,层数越多,模型越复杂,计算能力要求越高。对于输入层和隐藏层,每一个神经元代表输入,经过一系列计算得到输出,将输出作为下一层神经元的输入,以此类推,直到传递到输出层。
神经网络可以充分逼近任意复杂的非线性关系;所有定量或定性的信息都等势分布贮存于网络内的各神经元,故有很强的鲁棒性和容错性;采用并行分布处理方法,使得快速进行大量运算成为可能;可学习和自适应不知道或不确定的系统。


Python“宝藏级”公众号【Python之王】专注于Python领域,会爬虫,数分,C++,tensorflow和Pytorch等等。
近 2年共原创 100+ 篇技术文章。创作的精品文章系列有:
日常收集整理了一批不错的 Python 学习资料,有需要的小伙可以自行免费领取。
获取方式如下:公众号回复资料。领取Python等系列笔记,项目,书籍,直接套上模板就可以用了。资料包含算法、python、算法小抄、力扣刷题手册和 C++ 等学习资料!