
17个机器学习的常用算法!
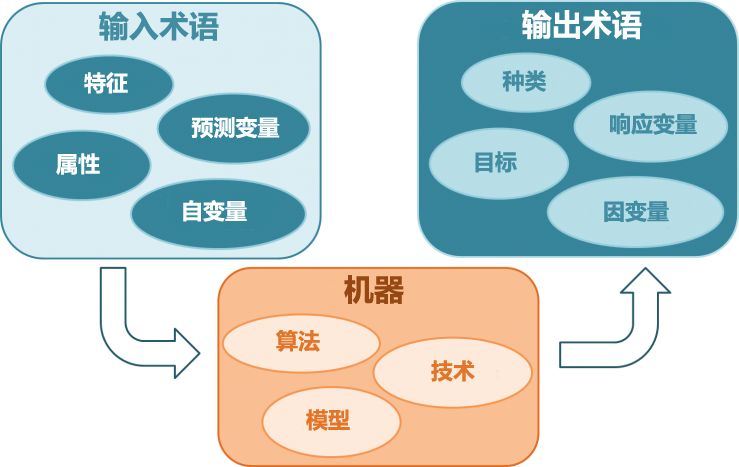
1. 监督式学习:
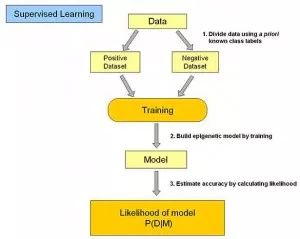
2. 非监督式学习:
3. 半监督式学习:
4. 强化学习:
5. 算法类似性
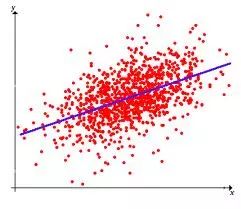
6. 回归算法:
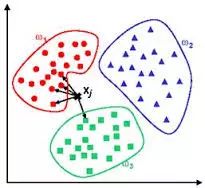
7. 基于实例的算法
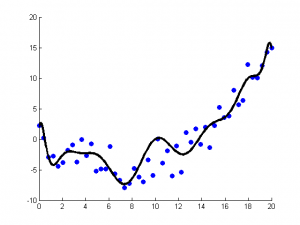
8. 正则化方法
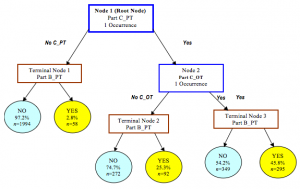
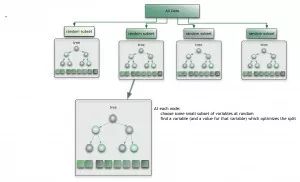
9. 决策树学习
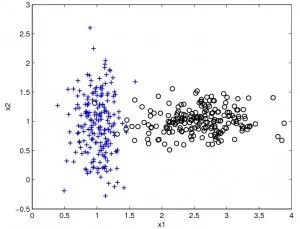
10. 贝叶斯方法
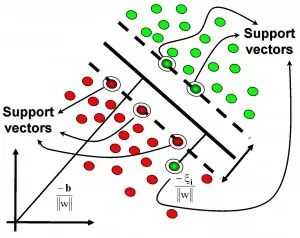
11. 基于核的算法
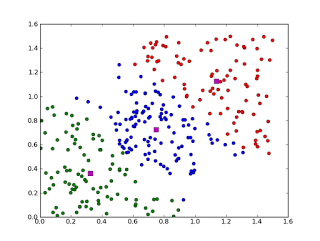
12.聚类算法
13. 关联规则学习
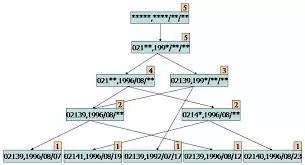
14. 人工神经网络
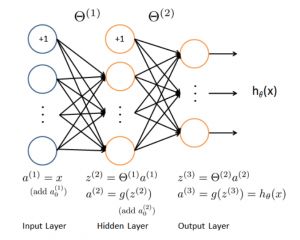
15. 深度学习
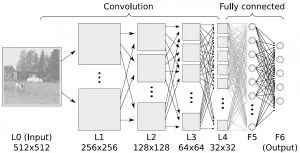
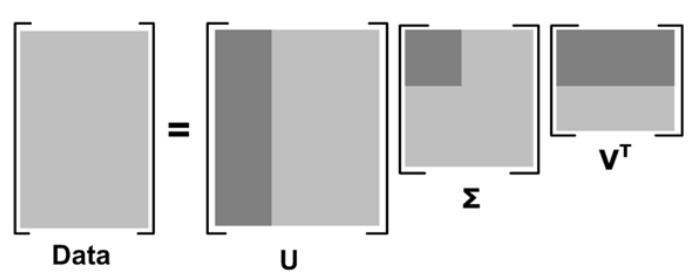
16. 降低维度算法
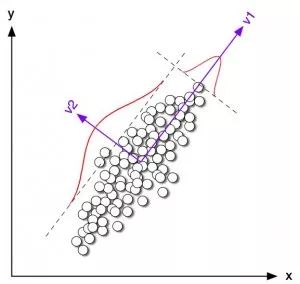
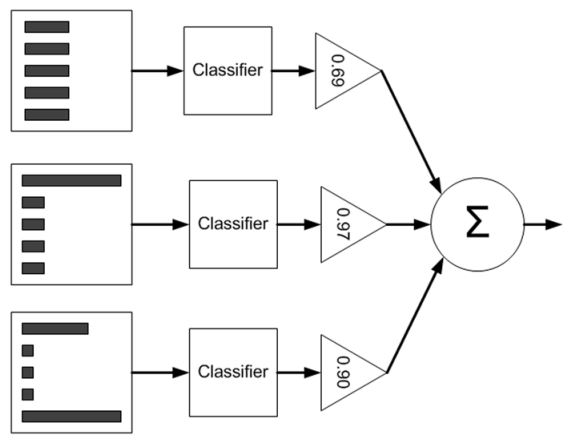
17. 集成算法:
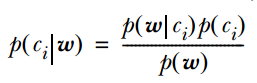
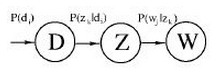
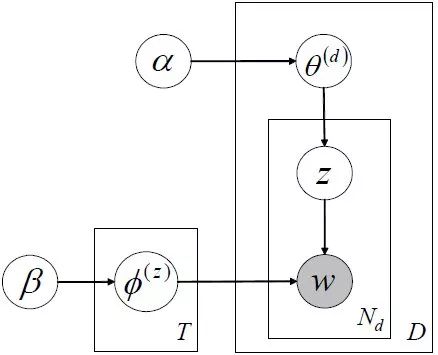
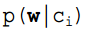 的计算方法,而由朴素贝叶斯的前提假设可知,
的计算方法,而由朴素贝叶斯的前提假设可知,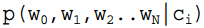 =
=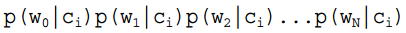 ,因此一般有两种,一种是在类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本的总和;第二种方法是类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本中所有特征出现次数的总和。中的某一项为0,则其联合概率的乘积也可能为0,即2中公式的分子为0,为了避免这种现象出现,一般情况下会将这一项初始化为1,当然为了保证概率相等,分母应对应初始化为2(这里因为是2类,所以加2,如果是k类就需要加k,术语上叫做laplace光滑, 分母加k的原因是使之满足全概率公式)。
,因此一般有两种,一种是在类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本的总和;第二种方法是类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本中所有特征出现次数的总和。中的某一项为0,则其联合概率的乘积也可能为0,即2中公式的分子为0,为了避免这种现象出现,一般情况下会将这一项初始化为1,当然为了保证概率相等,分母应对应初始化为2(这里因为是2类,所以加2,如果是k类就需要加k,术语上叫做laplace光滑, 分母加k的原因是使之满足全概率公式)。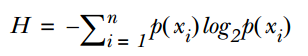
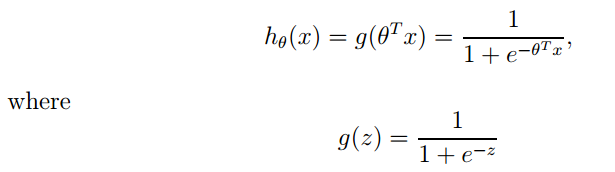
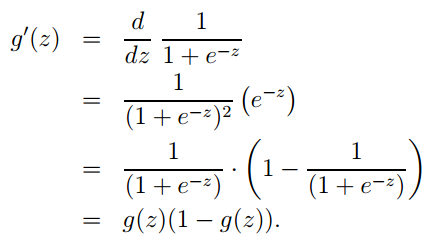
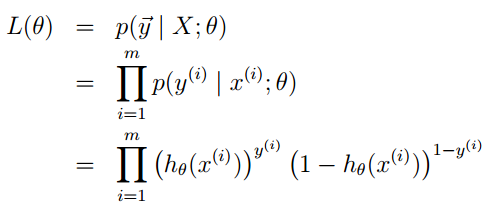
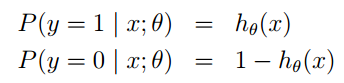
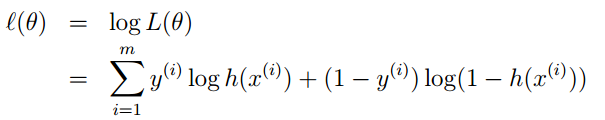
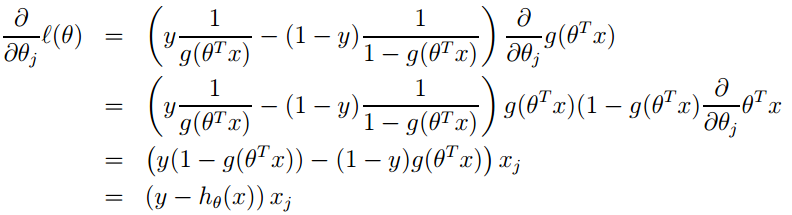

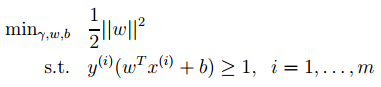
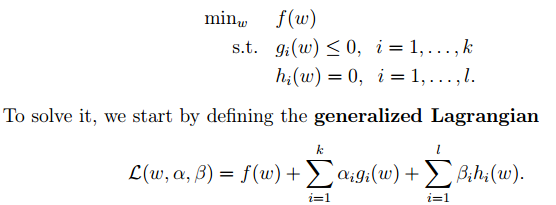
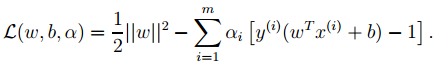
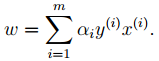
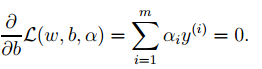
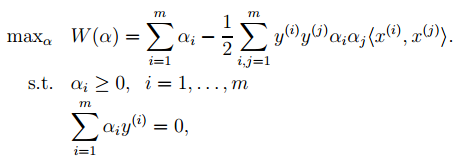
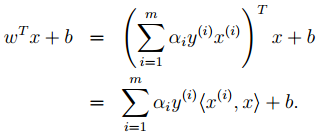
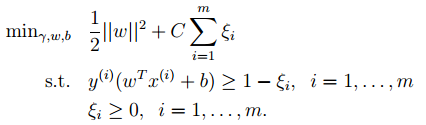
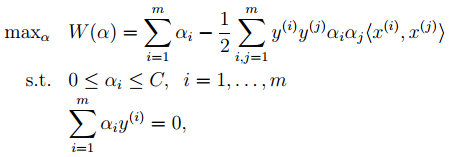
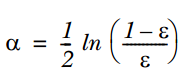
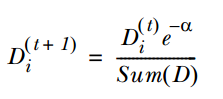
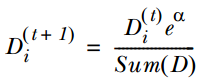
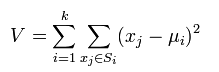
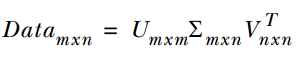


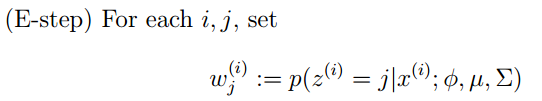
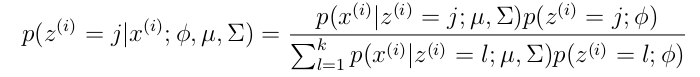


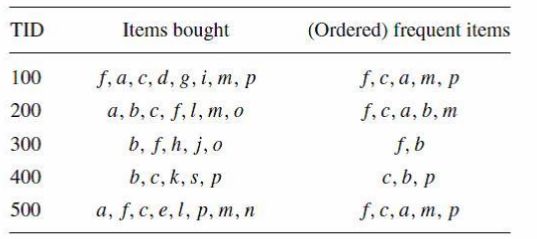
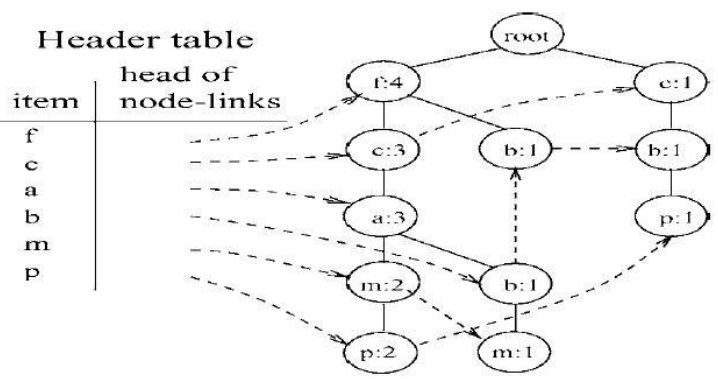
推荐阅读:
评论