
从DPU的崛起谈谈计算体系变革


导读:最近DPU概念异常火爆,从Mellanox、Fungible、NVIDIA到Intel,各路诸侯纷纷加入战场,各种概念Smart NIC、DPU、IPU层出不穷,各种SDK,FunOS、DOCA、IPDK令人眼花缭乱,比当年AI还要火爆。
下载链接:
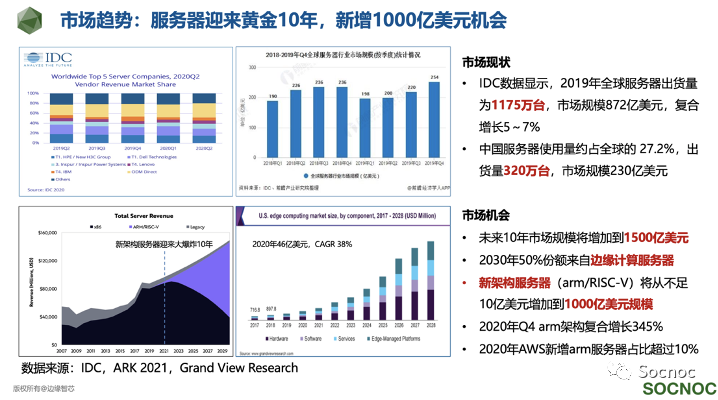
数据中心的核心支柱服务器是一个非常有意思和残酷的产业,容易垄断,淘汰又非常快,一不留神就退出了历史的舞台。
和20年前x86通过占领个人PC市场反攻数据中心/大型机市场这种“农村包围城市”的打法一样,今天的arm/risc-v架构通过占领手机,物联网等终端设备,开始进入数据中心市场。但和20年前不一样的是,Intel面对的竞争不是来自同行,而是客户“自下而上”的竞争。例如2020年苹果宣布2年内替换Intel CPU到自研Apple Silicon;AWS云服务中新增服务器中自研arm架构比例也已经超过10%了。这种“不对称”竞争将加速x86架构的衰落,所以ARK预测这次架构的变革可能只需要10年。如果按照两三年一代的迭代速度,留给Intel的机会可能也就3代产品的时间了。
在这次服务器架构变革还有一个非常有意思的地方,通常大家忽视的一个地方,未来10年服务器的增量大头会发生在边缘计算领域,预计2029年边缘服务器将达到700-900亿美元规模,将占据服务器市场规模的50%左右。所以我们认为“第三颗”大芯片的机会应该更快的在边缘计算领域发生。
数据为中心的计算时代

最早提出“数据为中心”Data-centric计算时代这个概念的是硅谷创业公司Fungible。在数据为中心的架构中,计算更加靠近网络,即流量产生或者到达的地方,通过增加一个SoC的方式卸载host CPU对流量处理的开销。
根据Fungible和AWS的统计,在大型数据中心中,流量处理占到了计算的30%左右,即数据中心中30%的计算是在作流量处理,这个开销被形象的叫做数据中心税(Datacenter Tax)。借用某某资本的总结,数据为中心的计算架构的好处是降低了CPU到加速卡的路径,是数据传输效率更高,性能更好。
最早提出这个概念的Fungible同时给自己的芯片取了一个特有的名字“DPU”,同时认为DPU将成为计算机仅次于CPU、GPU的“第三颗”大芯片出现。Fungible认为自己的使命是解决数据为中心的时代的网络流量问题。DPU的出现是为了解决数据中心中存在三个方面共五大问题:

按照技术出现的时间顺序和特点,我们将DPU的发展分为三个阶段:
这个可以称为DPU的史前时代。解决节点间流量问题的最简单的方式是增加网卡的处理能力,通过在网卡上面引入SoC或者FPGA的方式加速某些特定流量应用,从而加强网络的可靠性,降低网络延迟,提升网络性能。其中Xilinx和Mellanox在这个领域进行的比较早,可惜由于战略能力不足,错失了进一步发展的机会,逐渐被DPU取代,最终被淘汰。其中Mellanox被Nvidia收购,Xilinx被AMD拿下。智能网卡成为DPU的应用产品而存在。(Marvell会如何选择我们拭目以待)
这个阶段是数据芯片真正开始被重视的阶段。最开始由Fungible在2019年提出,但没有引起太多反响。Nvidia将收购来的Mellanox重新包装之后,2020年10月重新定义了DPU这个概念,DPU这个概念一炮而红。有意思的是Nvidia对DPU的定义完全不同于Fungible,在Nvidia的博客上有一段非常有意思的评价。
虽然Fungible号称DPU是要解决很多网络问题。但回归本质,一个性能强大的x86都没有解决的问题,为什么一个嵌入式SoC可以干得更加好呢?这个是一个非常严肃也是一个需要正面回答的问题。显然Fungible回避了这个本质问题,而是用了一个120瓦的SoC来处理流量问题。然而Nvidia却从另一个纬度回答了这个问题,那就是DPU只应该处理网络路径(network data path initialization)和异常(exception processing),而不是其他的(nothing more)。
Nvidai的做法非常简单同时也非常容易理解,毕竟卖GPU比卖DPU更加赚钱,而Nvidia不会放过一切增加GPU销量的机会。但仔细看一下这句话,其实暗含了一个Nvidia的技术路线exception processing!
对于“第三颗”芯片这么重要的战场,自然少不了Intel的加入。Intel的解决方案非常简单粗暴。DPU的存在不就是为了解决流量卸载问题么,我用FPGA就好了!DPU不就是想管理云平台么?那好,我再送一个CPU就好了。于是乎Intel的方案变成了FPGA+Xeon-D的模式,通过PCB版的方式放在一个智能网卡上(估计功耗要超过200瓦)。
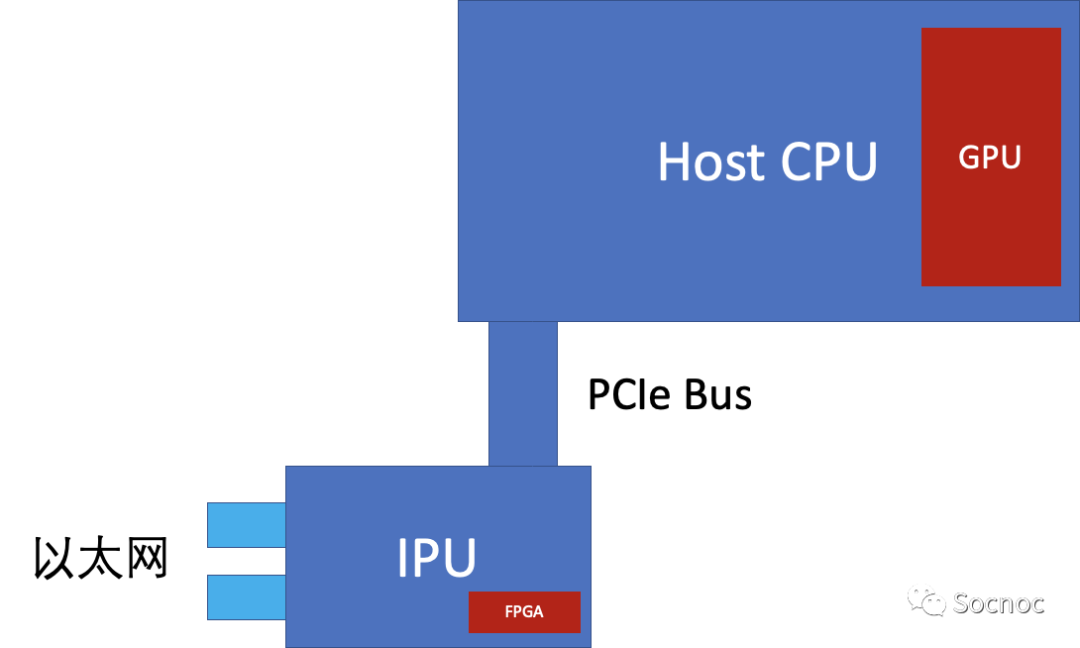 |
同时Intel给这个方案取了一个非常有意思的名字“基础设施处理器”。显然Intel将IPU定位成host CPU上面一个“外挂”的小CPU,而且未来这个“外挂”CPU和FPGA会封装到一个芯片中,形成一个奇怪的通过PCIe总线互联的两个CPU系统。这种一个总线多个CPU的架构,Intel在GPU Phi中已经用过。
从系统上来看,这个架构非常简洁,我们觉得应该也是DPU应该发展的方向。但同时IPU引发了一个架构性的问题,“这个架构中到底IPU是中心,还是host CPU是中心?”。目前Intel只给出了一个非常模棱两可的介绍,回避了这个问题。我们认为真正解决了这个问题的芯片才能成为未来真正的“第三颗”大芯片,甚至是主要芯片。
显然Intel和Nvidia都看到了这个机会,DPU/IPU真正有价值而且极具价值的在于,谁处理exception?到底是host CPU还是DPU?如果是DPU?那么其他设备比如GPU的exception谁处理呢?
经过几年的发展,数据芯片(DPU/IPU)的地位一直在提升,正在成为“第三颗”大芯片。
对比一下当前Fungible、Nvidia和Intel的技术路线我们总结如下:
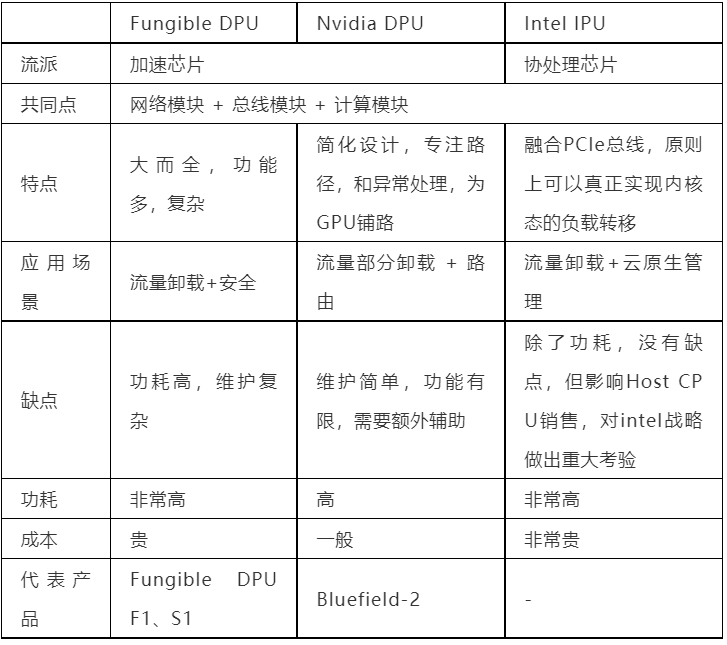
DPU/IPU的重要性已经达成了共识。但围绕DPU的定位存在一些争论,不同的公司根据自己技术特点选择不同技术路线。
数据中心的问题和技术发展的趋势需求
数据中心作为当前信息化的基石,在过去50年发展相当迅猛。随着算力的提升,数据中心的能耗也越来越大,通常从广义上讲,数据中心面对三个核心问题:
性能问题(scale-up):如何提升计算性能,简单说就是单台服务器越算越快,这个有点难度,目前性能最强大的CPU应该是ARM架构的富岳(Fugaku); 规模问题(scale-out):第二个问题就是系统效率问题,如果一台服务器算力不够(大部分数据中心应用一台服务器是不够的),那么我们就需要多台服务器组成集群进行集群计算。如何接入更加多的服务器?并高效率的统筹各个服务器的运行状态和效率也是一个非常复杂和需要解决的问题,通常这个问题是一个系统架构和网络问题; 能耗问题(power):第三个问题是能耗问题。如何降低能耗、提升计算效率,从传统追求性能的技术路线,变成追求效能的技术路线?中国在这一方面战略上远远领先其他国家,特别是“碳达峰、碳中和3060”基本方针的提出。如果中国能早日实现计算上的“碳中和”,让CPU可以仅仅消耗极小的能耗即可运转的话,对能源安全和信息格局将发生巨大影响。
性能和能耗问题是一个非常复杂又有趣的问题,但不是我们DPU的重点,未来我们将介绍一篇如何用DPU和低功耗CPU也可以达到高性能高吞吐量计算的架构,今天我们接着DPU的技术路线继续。
按照DPU开始的定义,DPU核心是解决数据中心第二问题:“如何解决多节点服务器互联效率问题”。按照Fungible的结论,当前数据中心互联架构无法适应超大型数据中心(mega datacenter)和超小型数据中心(edge datacenter),所以Fungible提出用DPU和TrueFabric技术解决这个问题。 的确有些数据中心非常大,几万台甚至十几万台服务器互联组成集群;有些特别小,可能只有十几台服务器互联。那么Fungible这种技术路线是不是可以解决这个问题呢?有没有更加友好的技术路线呢?
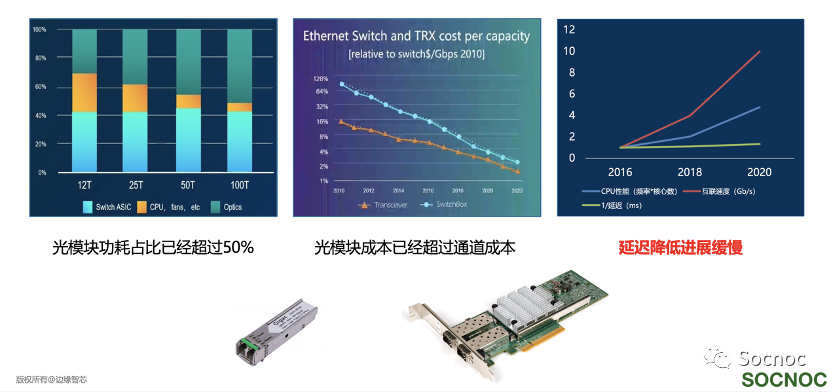
数据中心互联通常采用光通信方式,随着容量的提升在100T当量下,光模块的功耗占比超过了互联整体成本的50%,并且光模块成本也已经超过了通道成本(也就是说光模块加起来比交换机盒子贵了),但是随着吞吐率的激增,互联延迟缺没有明显降低。
那一方面数据中心的用户,下游云计算产业的需求是对设备越来越颗粒化的管理和资源调配。在云计算3.0架构下,云管理平台(IaaS)希望对设备(CPU、GPU、FPGA、AI、NIC等)继续更加细致的管理,最好可以对每个设备进行独立操作(远程替换、升级、资源分配)。当然这种管理最好基于TCP/IP协议的Restful API接口。如果进一步,希望每个微服务(CPU运行应用)之间的TCP/IP通讯也可以在新型网络架构中加速。

云计算2.0以服务器为单元,实现计算资源的软件定义,IaaS软件通过对服务器CPU的控制,实现CPU、内存、储存、网络的资源分配。而云计算3.0时代,设备单元将以“个体”、“独立”的方式被云平台(IaaS)管理和控制,整个设备单元以机柜(rackscale disaggregated hardware)方式存在。同时一切以API调用为主!
在Fungible的基础上,我们总结了数据中心互联DPU芯片需要解决的几大问题如下:

DPU的技术细节
接下来我们将从系统角度分析当前DPU做的什么事情,解决了哪些问题。
服务器互联和网络架构是一个非常复杂并且涉及到非常多的环节,为了简化问题,我只将DPU会涉及到的环节显示出来,如下图:
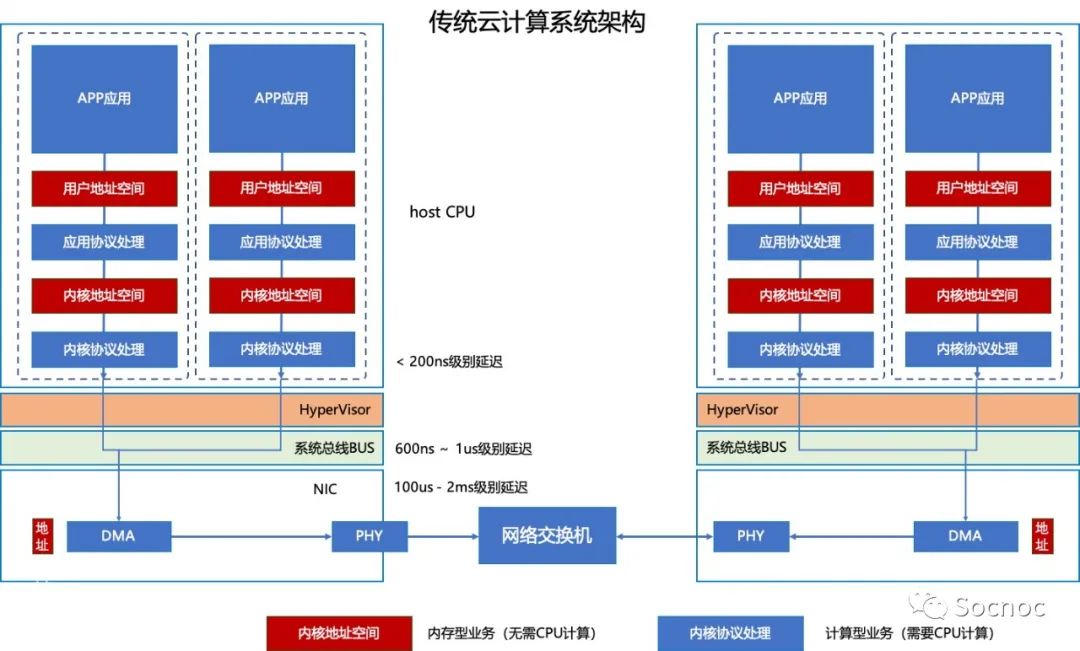
计算模块:主要由host CPU承担(部分由网卡上面的DMA小芯片承担)。当一个微服务(APP应用)和另外一个微服务(APP应用)通讯的时候,按照节点内(同一个host CPU上),和节点间(不同host CPU)上,数据流涉及的环节分别如下:
这是传统服务器和服务器互联的应用场景,这种场景中数据主要经历用户空间、内核空间、hypervisor、总线、网卡、PHY、交换机等一些列路径。在这些路径中:
host CPU环节:现代CPU计算非常快,延迟一般由计算量确定。如果协议复杂、延迟就高,主频高,延迟就低。由于大部分协议都在host CPU上处理,所以传统意义上提高主频可以降低延迟; HyperVisor路径:HyperVisor和系统OS一般深度耦合,是IaaS计算平台的核心,计算量不大,主要工作是资源调度和计算切换(context switch)。一般云计算应用场景,资源(CPU、内存等)存在一定量的超售(也就是一个CPU卖了2-4个用户,用户通过分时间使用CPU)。由于内存的速率和CPU存在一个数量级的差异,频繁的计算切换将严重影响CPU的效率,使得CPU处于等待数据读取和写入阶段。同时因为网络需要考虑状态(TCP时序等),一旦切换发生很有可能需要重新开始计算一部分数据,导致了无形中浪费了计算资源,也增加了延迟; 系统总线模块:这个模块开始就是纯硬件模块了,一般的软件架构师不关注这一块,一般的网络芯片架构师也不设计这一块,是被忽视的部分。我们列出来是因为我们DPU+将在这一块上做文章,同时在DPU中也得包含这个部分。技术提升比较简单,提升总线频率即可; 网卡模块:这个是重头戏,工作内容却非常简单,就是将网络报文转化成光电信号发出去。由于CPU需要处理大量的工作,所以增加一个DMA(一个小的MCU做简单的网络协议处理功能)协助CPU干活。基本上现在Smart NIC和DPU就是对这个模块进行升级,让一个MCU干更多复杂的事情; PHY、网络交换机部分:这一块就是以太网协议的设备了。
这种数据模式是微服务的基本通讯方式。基本路径和节点间互联一样,唯一的区别是路由由Hypervisor(NAT或者端口,软路由)或者网卡(Bridge,硬路由)处理,即网络报文不需要额外交换机设备即可处理。这种方式是云计算的基本处理方式。
在分布式系统中(云计算、分布式数据库、分布式存储等),微服务同时存在多节点上,所以节点间、节点内通讯共存。在这种模式上,每个微服务相当于一个跨服务器间的“进程”。这种情况下,多台服务器互联成为一个“大服务器”。其中网络形成一个网络拓扑,称为Fabric。所以DPU的目标就是构建一个快速的Fabric网络,用于云计算应用。

综上可以看到当前数据中心(包括小型集群)都构建在一个网络Fabric基础上,在这个Fabric上提供统一基于TCP/IP协议的微服务架构。构成这个网络Fabric的基础就是以太网技术,而技术发展目标就是提升吞吐率和降低延迟。
上面已经介绍了网络Fabric是微服务和云计算发展的必然趋势。这个网络Fabric就像一张数据网,数据在中间流动。所以Fungible和Nvidia把组成这个Fabric的芯片命名为DPU,数据处理芯片。那DPU如何构建这个Fabric?如何降低网络延迟呢?
DPU如何创新?刚刚介绍了在数据流中,内核协议处理部分和微服务应用相关性很小。所以一个想法就是将内核模块下沉到DMA上,这样就需要一个更加强大的MCU。最开始Xillinx和Intel都用FPGA来替代传统的DMA(网络芯片),达到应用加速的目的。在这种架构下,数据处理发生在host CPU之前,所以可以改善应用通讯的延迟,主要原因是:
网络处理发生在中断前,这个没有改进延迟,但节省了CPU的等待时间 FPGA是独占式处理网络任务,不需要context switch,极大降低了高负载应用情况下的切换带来的延迟,极大的降低了网络抖动 可以把一些需要硬件加速的通用计算用FPGA加速,进一步释放CPU
通过DPU互联我们可以有效的降低网络延迟和抖动,构建一个网络Fabric。

由于上述创新和Nvidia的大V效应,DPU很快热了起来。现在DPU最大的问题就是“过热”,功耗太高了。以前一个网络DMA芯片功耗才5瓦左右,现在一个DPU动则100瓦以上(Fungible F1 120瓦)。大部分应用场景无法用承受这么大功耗的网络设备。尤其是在100/200G以上,光模块功耗已经超过网络设备的情况下,再增加一个100瓦的网络DPU,会极大的提升网络的能源消耗。所以必须解决DPU功耗问题。
另外一个问题和架构有关,如果仔细看看DPU的架构不难发现,基本上DPU包括三个模块:1)网络模块,2)计算模块,3)总线模块。其中计算模块可以理解为以前网络DMA芯片的升级版本,从一个简单的ASIC升级成了一个强大的CPU或者网络处理器;网络模块是NIC的核心部件,接口为100/200G,同时提供网络交换功能,本质是一个小型的网络交换芯片;而总线模块是因为需要互联host CPU进行协议转换,也需要互联DPU内置CPU,一般采取PCIe 4.0/5.0为主。
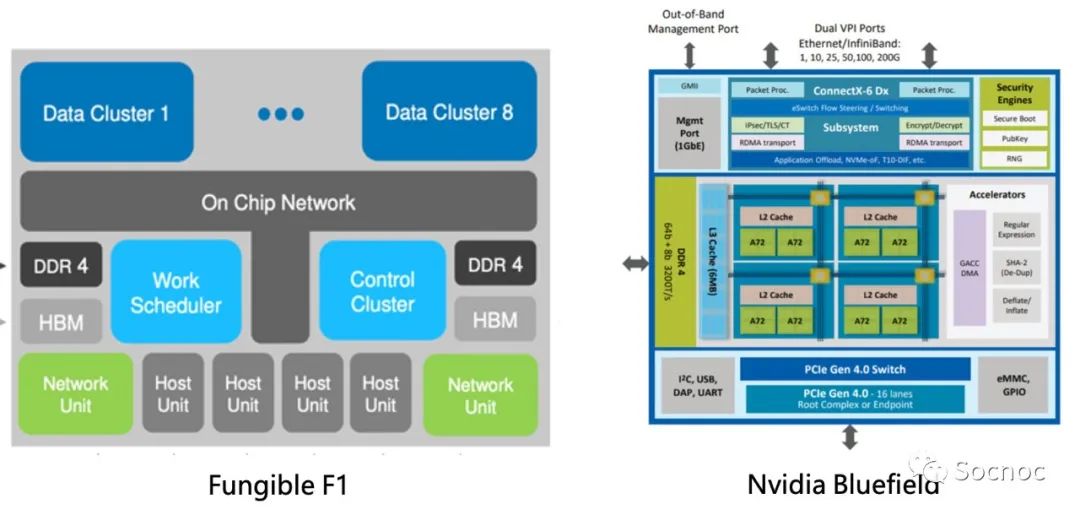
如果不是Fungible把F1叫做DPU用于智能网络,我觉得把这颗芯片当作一个路由器或者防火墙芯片也是绰绰有余的。考虑到Fungible具备强大的路由器、防火墙背景,这就不难理解了。我感觉Fungible的技术路线就是将防火墙芯片变成小放在网卡设备上,给每一台服务器提供一个防火墙芯片。但120瓦的功耗的确有点高。个人觉得这条技术路线不是DPU应该做的事情。
Nvidia很快就发现了这个问题,他们觉得如果用DPU处理CPU的任务是不可能的。DPU的CPU只应该做路径初始化和异常处理,有点类似L2/L3层交换机的意思。所以Nvidia的DPU就只放了几颗arm cpu,增加可编程能力而已。功耗也明显降低了下来。
和功耗一样现在的DPU成本太高了,基于DPU的解决方案变没有降低网络互联的成本。
目前DPU都是面向数据中心的应用场景。但服务器增长空间更多在边缘计算中心,而且未来边缘计算互联将成为网络技术趋势,所以DPU必须考虑边缘计算场景。
下一代数据中心(集群)将以Data Fabric作为支撑,而DPU是这个新Fabric的核心。
为什么芯片会催生新的计算架构
DPU区别于Smart NIC最显著的特点,DPU本身构建了一个新的网络拓扑,而不是简单的数据处理卸载计算。最开始Fungible就是因为发展了自己的TCP协议,极大的降低了以太网互联的延迟和抖动问题,从而定义了DPU芯片。
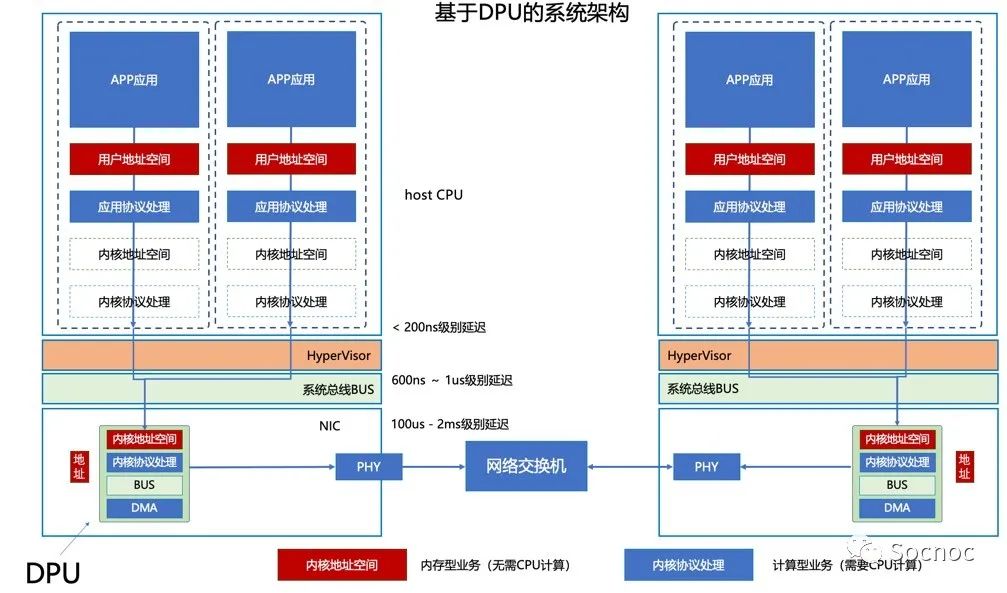
DPU可以构建新的协议,Smart NIC一般只是加速协议处理 DPU可以构建总线拓扑,Smart NIC是一个设备,无法构建新的总线拓扑 DPU可以作为中心芯片(可以直接控制SSD等设备),而Smart NIC无法直接控制SSD、GPU等
Nvidia对DPU和Smart NIC做了一个非常详细的介绍,但没有到核心架构上。DPU可以脱离host CPU存在,而Smart NIC不行。这个本质的区别就是DPU可以构建自己的总线系统,从而控制和管理其他设备,也就是一个真正意义上的中心芯片,第三颗芯片。这个也是为什么Smart NIC出来这么多年,只有Fungible可以说他们的芯片是DPU!
总线是一个非常珍贵的资源,可以做很多事情!Fungible的架构师明显意思到了这一点,做了非常有意思的解决方案。DPU复用!我们见过利用SR-IOV技术在一个服务器中虚拟化多个网卡VF的技术来实现多张网卡的,但很少见到一张网卡被多个服务器使用的?当然回到Fungbile DPU功耗达到120瓦的实际情况下,我们必须多“复用”这个DPU达到降低使用成本的目的。Fungible的架构师还真的就这么干了一个系统。
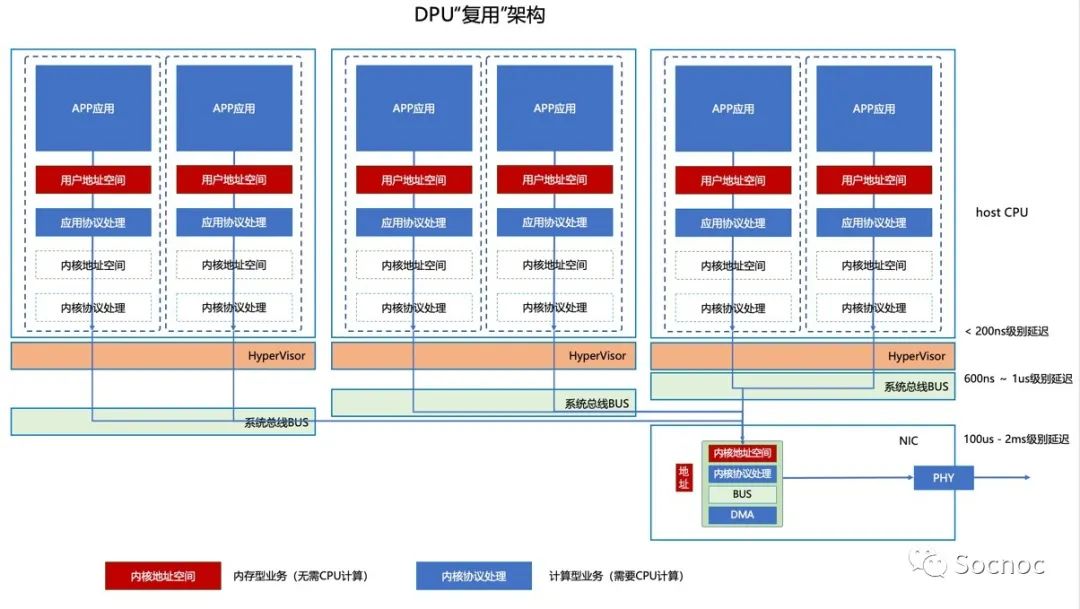
在DPU复用架构中,DPU实际上起到了交换ASIC作用,也就是说DPU可以互联一个小集群。目前Fungible是支持8个,Nvidia的BlueFiled应该也不会超过8个。
DPU的复用看似是Fungible一个无奈的选择(功耗和成本太高、需要降低TCO),但却创造了一个全新的计算架构。传统的以CPU为中心的计算体系,要让位给DPU为了。未来我们将单独从架构上分析为什么这个趋势是不可避免的。
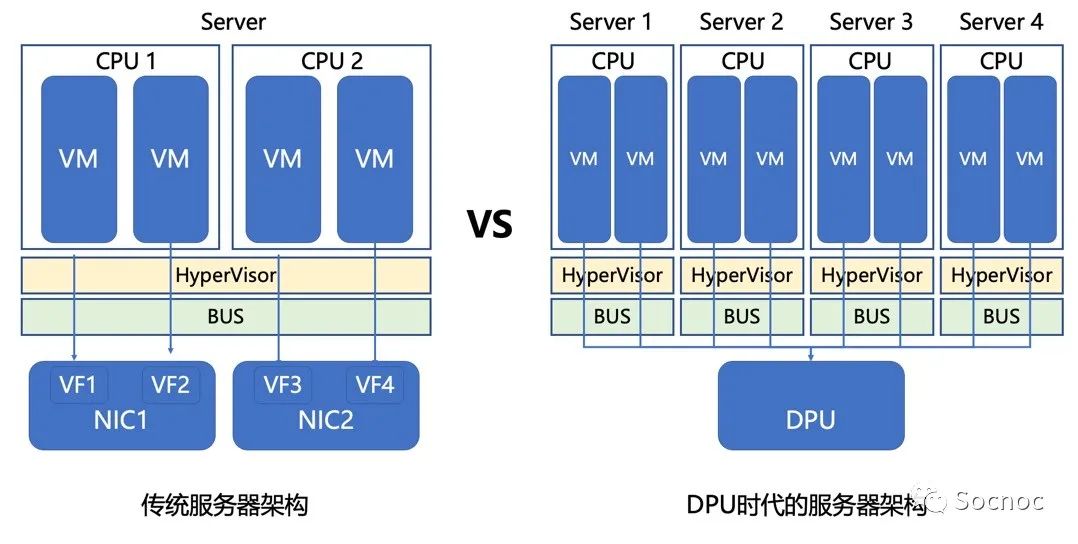
传统服务器架构中,服务器设计以CPU为中心,CPU通过初始化总线树,给每一个设备分配ID,然后所有设备按照总线协议进行协作。网卡通过SR-IOV技术可以通过软硬件协同的方式加速虚拟化环境中的网络性能,这种网络处理方式中,Mellonax的ConnectX性能比较突出。如果需要多路CPU,就通过CPU总线的方式扩展一路、双路、四路、甚至八路CPU加强计算能力。这种架构通用计算能力强悍,但重复计算较多(每个VM都需要处理相似的网络计算),对CPU的开销比较大,成本非常高。这个就是30% Datacenter tax的来源。
在DPU复用架构中,DPU相当于一个网络交换机,互联多个CPU服务器,形成一个计算集群。由于网络协议栈和一些公共计算由DPU提前处理完成,在这个集群中,CPU和CPU通讯减少了很多开销,达到了降低延迟的效果。或者反过来说,就是不需要强大的CPU了。这样可以极大降低8路互联集群的CPU成本,同时增强网络数据处理能力。在云计算领域具备非常明显的竞争优势。所以成为当前技术发展最热门的方向。
目前DPU是没有一个明确的定义的。虽然大家都强调以数据处理为主,但实际上做的都是Smart NIC的事情。同时明显Fungbile的出发是以网络架构为中心,以网络安全为手段的技术路线,本质上是一个L4(协议层)的公司在试图解决L2/L3(Fabric和路由)的问题,而Nvidia是以设备为中心,以GPU数据加速为手段,本质上是一个L1(设备层)的公司在解决L2/L3(Fabric和路由)的问题,两个公司的技术背景和技术路线也存在明显的差别。其他公司就只能算是一个Smart NIC公司了,打着DPU的旗号干加速的事情。
虽然Fungible和Nvidia都意识到了DPU的重要性,时间上具备领先优势,也做出了新架构的解决方案。但Intel发布的IPU进一步强调了在基础架构上数据芯片的重要性,干脆把IaaS模块全部下沉到了DPU上,将这个DPU重新命名为IPU。虽然Intel目前还没有明确表明自己IPU的架构,但可以预见Intel将整合网络、软件平台、总线技术的技术力量。
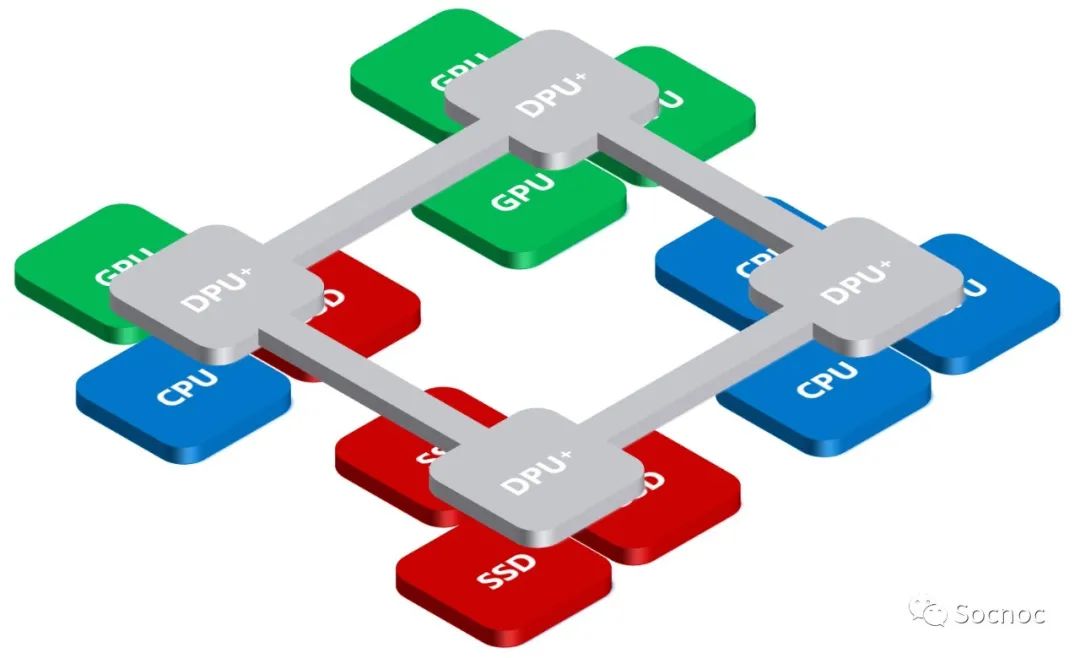
虽然目前DPU/IPU的定义没有标准,但数据芯片作为未来计算架构的支撑已经成为必然趋势。
下载链接:
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕,知识点深度讲解,提供182页完整版下载。
获取方式:点击“阅读原文”即可查看PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
