
【建议收藏】MySQL 三万字精华总结 —分区、分表、分库和主从复制...
九、分区、分表、分库
MySQL分区
一般情况下我们创建的表对应一组存储文件,使用MyISAM存储引擎时是一个.MYI和.MYD文件,使用Innodb存储引擎时是一个.ibd和.frm(表结构)文件。
当数据量较大时(一般千万条记录级别以上),MySQL的性能就会开始下降,这时我们就需要将数据分散到多组存储文件,保证其单个文件的执行效率
能干嘛
- 逻辑数据分割
- 提高单一的写和读应用速度
- 提高分区范围读查询的速度
- 分割数据能够有多个不同的物理文件路径
- 高效的保存历史数据
怎么玩
首先查看当前数据库是否支持分区
MySQL5.6以及之前版本:
SHOW VARIABLES LIKE '%partition%';MySQL5.6:
show plugins;
分区类型及操作
RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区。mysql将会根据指定的拆分策略,,把数据放在不同的表文件上。相当于在文件上,被拆成了小块.但是,对外给客户的感觉还是一张表,透明的。
按照 range 来分,就是每个库一段连续的数据,这个一般是按比如时间范围来的,比如交易表啊,销售表啊等,可以根据年月来存放数据。可能会产生热点问题,大量的流量都打在最新的数据上了。
range 来分,好处在于说,扩容的时候很简单。
LIST分区:类似于按RANGE分区,每个分区必须明确定义。它们的主要区别在于,LIST分区中每个分区的定义和选择是基于某列的值从属于一个值列表集中的一个值,而RANGE分区是从属于一个连续区间值的集合。
HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
hash 分发,好处在于说,可以平均分配每个库的数据量和请求压力;坏处在于说扩容起来比较麻烦,会有一个数据迁移的过程,之前的数据需要重新计算 hash 值重新分配到不同的库或表
KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
看上去分区表很帅气,为什么大部分互联网还是更多的选择自己分库分表来水平扩展咧?
- 分区表,分区键设计不太灵活,如果不走分区键,很容易出现全表锁
- 一旦数据并发量上来,如果在分区表实施关联,就是一个灾难
- 自己分库分表,自己掌控业务场景与访问模式,可控。分区表,研发写了一个sql,都不确定mysql是怎么玩的,不太可控
❝随着业务的发展,业务越来越复杂,应用的模块越来越多,总的数据量很大,高并发读写操作均超过单个数据库服务器的处理能力怎么办?
这个时候就出现了数据分片,数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中。数据分片的有效手段就是对关系型数据库进行分库和分表。
区别于分区的是,分区一般都是放在单机里的,用的比较多的是时间范围分区,方便归档。只不过分库分表需要代码实现,分区则是mysql内部实现。分库分表和分区并不冲突,可以结合使用。
❝说说分库与分表的设计
MySQL分表
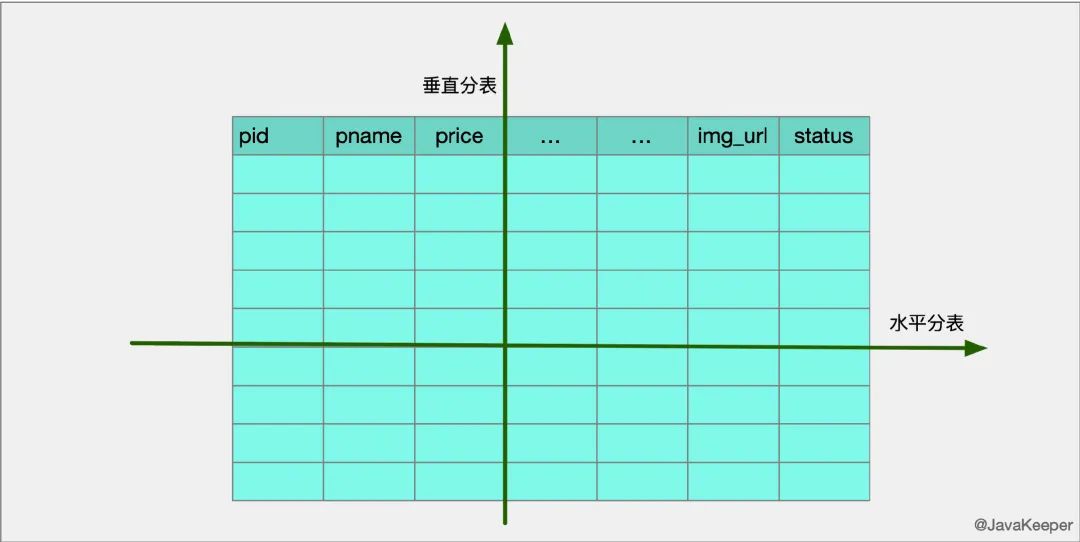
分表有两种分割方式,一种垂直拆分,另一种水平拆分。
垂直拆分
垂直分表,通常是按照业务功能的使用频次,把主要的、热门的字段放在一起做为主要表。然后把不常用的,按照各自的业务属性进行聚集,拆分到不同的次要表中;主要表和次要表的关系一般都是一对一的。
水平拆分(数据分片)
单表的容量不超过500W,否则建议水平拆分。是把一个表复制成同样表结构的不同表,然后把数据按照一定的规则划分,分别存储到这些表中,从而保证单表的容量不会太大,提升性能;当然这些结构一样的表,可以放在一个或多个数据库中。
水平分割的几种方法:
- 使用MD5哈希,做法是对UID进行md5加密,然后取前几位(我们这里取前两位),然后就可以将不同的UID哈希到不同的用户表(user_xx)中了。
- 还可根据时间放入不同的表,比如:article_201601,article_201602。
- 按热度拆分,高点击率的词条生成各自的一张表,低热度的词条都放在一张大表里,待低热度的词条达到一定的贴数后,再把低热度的表单独拆分成一张表。
- 根据ID的值放入对应的表,第一个表user_0000,第二个100万的用户数据放在第二 个表user_0001中,随用户增加,直接添加用户表就行了。
MySQL分库
❝为什么要分库?
数据库集群环境后都是多台 slave,基本满足了读取操作; 但是写入或者说大数据、频繁的写入操作对master性能影响就比较大,这个时候,单库并不能解决大规模并发写入的问题,所以就会考虑分库。
❝分库是什么?
一个库里表太多了,导致了海量数据,系统性能下降,把原本存储于一个库的表拆分存储到多个库上, 通常是将表按照功能模块、关系密切程度划分出来,部署到不同库上。
优点:
减少增量数据写入时的锁对查询的影响
由于单表数量下降,常见的查询操作由于减少了需要扫描的记录,使得单表单次查询所需的检索行数变少,减少了磁盘IO,时延变短
但是它无法解决单表数据量太大的问题
分库分表后的难题
分布式事务的问题,数据的完整性和一致性问题。
数据操作维度问题:用户、交易、订单各个不同的维度,用户查询维度、产品数据分析维度的不同对比分析角度。跨库联合查询的问题,可能需要两次查询 跨节点的count、order by、group by以及聚合函数问题,可能需要分别在各个节点上得到结果后在应用程序端进行合并 额外的数据管理负担,如:访问数据表的导航定位 额外的数据运算压力,如:需要在多个节点执行,然后再合并计算程序编码开发难度提升,没有太好的框架解决,更多依赖业务看如何分,如何合,是个难题。
❝配主从,正经公司的话,也不会让 Javaer 去搞的,但还是要知道
十、主从复制
复制的基本原理
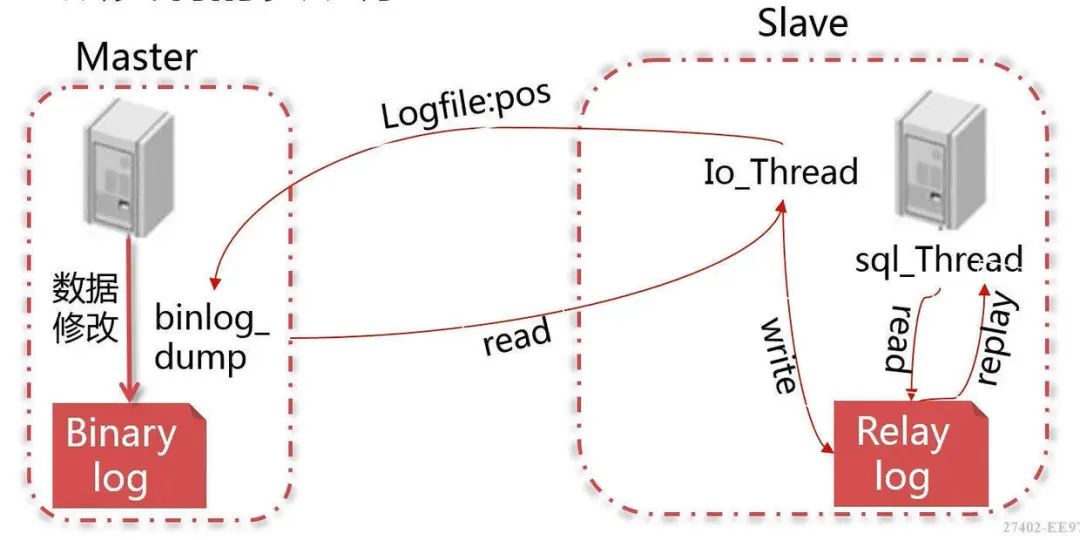
slave 会从 master 读取 binlog 来进行数据同步
三个步骤
 img
img
- master将改变记录到二进制日志(binary log)。这些记录过程叫做二进制日志事件,binary log events;
- salve 将 master 的 binary log events 拷贝到它的中继日志(relay log);
- slave 重做中继日志中的事件,将改变应用到自己的数据库中。MySQL 复制是异步且是串行化的。
复制的基本原则
- 每个 slave只有一个 master
- 每个 salve只能有一个唯一的服务器 ID
- 每个master可以有多个salve
复制的最大问题
- 延时
十一、其他问题
说一说三个范式
- 第一范式(1NF):数据库表中的字段都是单一属性的,不可再分。这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。
- 第二范式(2NF):数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖(部分函数依赖指的是存在组合关键字中的某些字段决定非关键字段的情况),也即所有非关键字段都完全依赖于任意一组候选关键字。
- 第三范式(3NF):在第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合第三范式。所谓传递函数依赖,指的是如 果存在"A → B → C"的决定关系,则C传递函数依赖于A。因此,满足第三范式的数据库表应该不存在如下依赖关系:关键字段 → 非关键字段 x → 非关键字段y
百万级别或以上的数据如何删除
关于索引:由于索引需要额外的维护成本,因为索引文件是单独存在的文件,所以当我们对数据的增加,修改,删除,都会产生额外的对索引文件的操作,这些操作需要消耗额外的IO,会降低增/改/删的执行效率。所以,在我们删除数据库百万级别数据的时候,查询MySQL官方手册得知删除数据的速度和创建的索引数量是成正比的。
- 所以我们想要删除百万数据的时候可以先删除索引(此时大概耗时三分多钟)
- 然后删除其中无用数据(此过程需要不到两分钟)
- 删除完成后重新创建索引(此时数据较少了)创建索引也非常快,约十分钟左右。
- 与之前的直接删除绝对是要快速很多,更别说万一删除中断,一切删除会回滚。那更是坑了。