
【建议收藏】MySQL 三万字精华总结 —查询和事务(三)
五、MySQL查询
❝count(*) 和 count(1)和count(列名)区别 ps:这道题说法有点多
执行效果上:
count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL count(1)包括了所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
执行效率上:
列名为主键,count(列名)会比count(1)快 列名不为主键,count(1)会比count(列名)快 如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*) 如果有主键,则 select count(主键)的执行效率是最优的 如果表只有一个字段,则 select count(*) 最优。
❝MySQL中 in和 exists 的区别?
exists:exists对外表用loop逐条查询,每次查询都会查看exists的条件语句,当exists里的条件语句能够返回记录行时(无论记录行是的多少,只要能返回),条件就为真,返回当前loop到的这条记录;反之,如果exists里的条件语句不能返回记录行,则当前loop到的这条记录被丢弃,exists的条件就像一个bool条件,当能返回结果集则为true,不能返回结果集则为false in:in查询相当于多个or条件的叠加
SELECT * FROM A WHERE A.id IN (SELECT id FROM B);
SELECT * FROM A WHERE EXISTS (SELECT * from B WHERE B.id = A.id);
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:
❝UNION和UNION ALL的区别?
UNION和UNION ALL都是将两个结果集合并为一个,两个要联合的SQL语句 字段个数必须一样,而且字段类型要“相容”(一致);
UNION在进行表连接后会筛选掉重复的数据记录(效率较低),而UNION ALL则不会去掉重复的数据记录;
UNION会按照字段的顺序进行排序,而UNION ALL只是简单的将两个结果合并就返回;
SQL执行顺序
手写
SELECT DISTINCTFROMJOINON WHEREGROUP BYHAVINGORDER BYLIMIT
机读
FROM <left_table>ON <join_condition><join_type> JOIN <right_table>WHERE <where_condition>GROUP BY <group_by_list>HAVING <having_condition>SELECTDISTINCT <select_list>ORDER BY <order_by_condition>LIMIT <limit_number>
总结
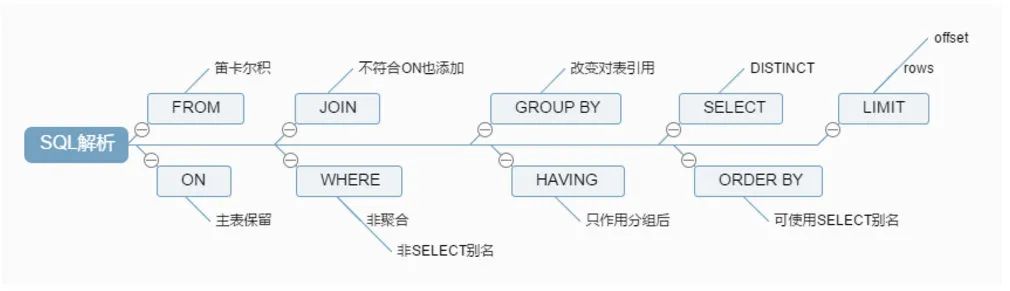
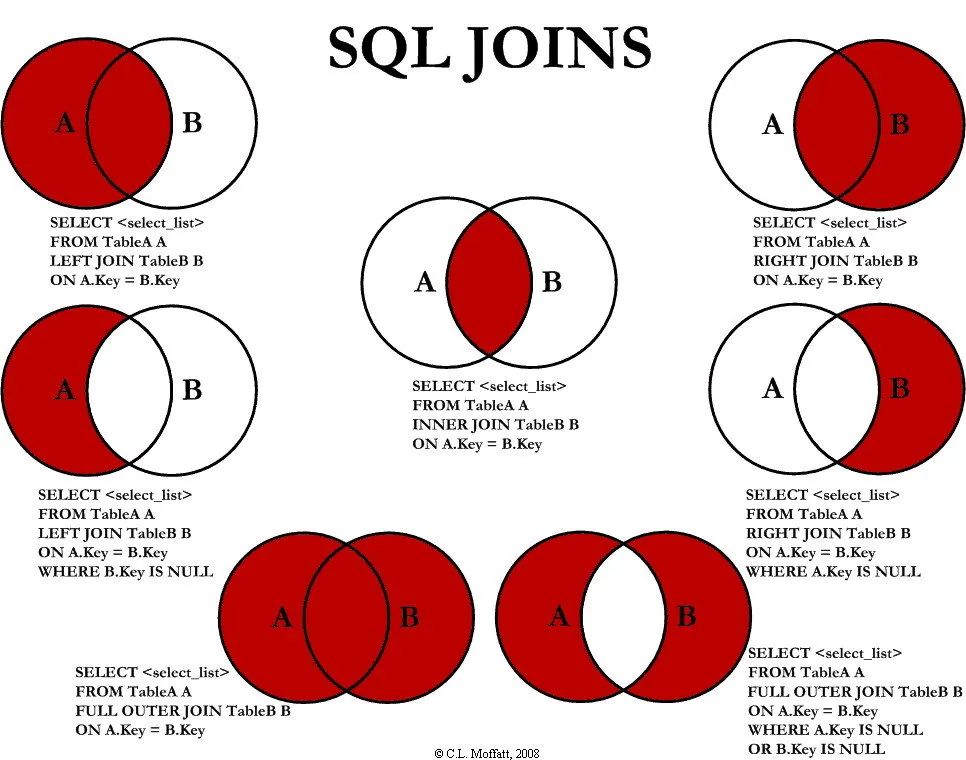
❝mysql 的内连接、左连接、右连接有什么区别?
什么是内连接、外连接、交叉连接、笛卡尔积呢?
Join图
六、MySQL 事务
❝事务的隔离级别有哪些?MySQL的默认隔离级别是什么?
什么是幻读,脏读,不可重复读呢?
MySQL事务的四大特性以及实现原理
MVCC熟悉吗,它的底层原理?
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
ACID — 事务基本要素
事务是由一组SQL语句组成的逻辑处理单元,具有4个属性,通常简称为事务的ACID属性。
A (Atomicity) 原子性:整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样 C (Consistency) 一致性:在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏 I (Isolation)隔离性:一个事务的执行不能其它事务干扰。即一个事务内部的操作及使用的数据对其它并发事务是隔离的,并发执行的各个事务之间不能互相干扰 D (Durability) 持久性:在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚
并发事务处理带来的问题
更新丢失(Lost Update):事务A和事务B选择同一行,然后基于最初选定的值更新该行时,由于两个事务都不知道彼此的存在,就会发生丢失更新问题 脏读(Dirty Reads):事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据 不可重复读(Non-Repeatable Reads):事务 A 多次读取同一数据,事务B在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果不一致。 幻读(Phantom Reads):幻读与不可重复读类似。它发生在一个事务A读取了几行数据,接着另一个并发事务B插入了一些数据时。在随后的查询中,事务A就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
幻读和不可重复读的区别:
不可重复读的重点是修改:在同一事务中,同样的条件,第一次读的数据和第二次读的数据不一样。(因为中间有其他事务提交了修改) 幻读的重点在于新增或者删除:在同一事务中,同样的条件,,第一次和第二次读出来的记录数不一样。(因为中间有其他事务提交了插入/删除)
并发事务处理带来的问题的解决办法:
“更新丢失”通常是应该完全避免的。但防止更新丢失,并不能单靠数据库事务控制器来解决,需要应用程序对要更新的数据加必要的锁来解决,因此,防止更新丢失应该是应用的责任。
“脏读” 、 “不可重复读”和“幻读” ,其实都是数据库读一致性问题,必须由数据库提供一定的事务隔离机制来解决:
一种是加锁:在读取数据前,对其加锁,阻止其他事务对数据进行修改。 另一种是数据多版本并发控制(MultiVersion Concurrency Control,简称 MVCC 或 MCC),也称为多版本数据库:不用加任何锁, 通过一定机制生成一个数据请求时间点的一致性数据快照 (Snapshot), 并用这个快照来提供一定级别 (语句级或事务级) 的一致性读取。从用户的角度来看,好象是数据库可以提供同一数据的多个版本。
事务隔离级别
数据库事务的隔离级别有4种,由低到高分别为
READ-UNCOMMITTED(读未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。 READ-COMMITTED(读已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。 REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。 SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
查看当前数据库的事务隔离级别:
show variables like 'tx_isolation'
下面通过事例一一阐述在事务的并发操作中可能会出现脏读,不可重复读,幻读和事务隔离级别的联系。
数据库的事务隔离越严格,并发副作用越小,但付出的代价就越大,因为事务隔离实质上就是使事务在一定程度上“串行化”进行,这显然与“并发”是矛盾的。同时,不同的应用对读一致性和事务隔离程度的要求也是不同的,比如许多应用对“不可重复读”和“幻读”并不敏感,可能更关心数据并发访问的能力。
Read uncommitted
读未提交,就是一个事务可以读取另一个未提交事务的数据。
事例:老板要给程序员发工资,程序员的工资是3.6万/月。但是发工资时老板不小心按错了数字,按成3.9万/月,该钱已经打到程序员的户口,但是事务还没有提交,就在这时,程序员去查看自己这个月的工资,发现比往常多了3千元,以为涨工资了非常高兴。但是老板及时发现了不对,马上回滚差点就提交了的事务,将数字改成3.6万再提交。
分析:实际程序员这个月的工资还是3.6万,但是程序员看到的是3.9万。他看到的是老板还没提交事务时的数据。这就是脏读。
那怎么解决脏读呢?Read committed!读提交,能解决脏读问题。
Read committed
读提交,顾名思义,就是一个事务要等另一个事务提交后才能读取数据。
事例:程序员拿着信用卡去享受生活(卡里当然是只有3.6万),当他埋单时(程序员事务开启),收费系统事先检测到他的卡里有3.6万,就在这个时候!!程序员的妻子要把钱全部转出充当家用,并提交。当收费系统准备扣款时,再检测卡里的金额,发现已经没钱了(第二次检测金额当然要等待妻子转出金额事务提交完)。程序员就会很郁闷,明明卡里是有钱的…
分析:这就是读提交,若有事务对数据进行更新(UPDATE)操作时,读操作事务要等待这个更新操作事务提交后才能读取数据,可以解决脏读问题。但在这个事例中,出现了一个事务范围内两个相同的查询却返回了不同数据,这就是不可重复读。
那怎么解决可能的不可重复读问题?Repeatable read !
Repeatable read
重复读,就是在开始读取数据(事务开启)时,不再允许修改操作。MySQL的默认事务隔离级别
事例:程序员拿着信用卡去享受生活(卡里当然是只有3.6万),当他埋单时(事务开启,不允许其他事务的UPDATE修改操作),收费系统事先检测到他的卡里有3.6万。这个时候他的妻子不能转出金额了。接下来收费系统就可以扣款了。
分析:重复读可以解决不可重复读问题。写到这里,应该明白的一点就是,不可重复读对应的是修改,即UPDATE操作。但是可能还会有幻读问题。因为幻读问题对应的是插入INSERT操作,而不是UPDATE操作。
什么时候会出现幻读?
事例:程序员某一天去消费,花了2千元,然后他的妻子去查看他今天的消费记录(全表扫描FTS,妻子事务开启),看到确实是花了2千元,就在这个时候,程序员花了1万买了一部电脑,即新增INSERT了一条消费记录,并提交。当妻子打印程序员的消费记录清单时(妻子事务提交),发现花了1.2万元,似乎出现了幻觉,这就是幻读。
那怎么解决幻读问题?Serializable!
Serializable 序列化
Serializable 是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。简单来说,Serializable会在读取的每一行数据上都加锁,所以可能导致大量的超时和锁争用问题。这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。
比较
| 事务隔离级别 | 读数据一致性 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|
| 读未提交(read-uncommitted) | 最低级被,只能保证不读取物理上损坏的数据 | 是 | 是 | 是 |
| 读已提交(read-committed) | 语句级 | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 事务级 | 否 | 否 | 是 |
| 串行化(serializable) | 最高级别,事务级 | 否 | 否 | 否 |
需要说明的是,事务隔离级别和数据访问的并发性是对立的,事务隔离级别越高并发性就越差。所以要根据具体的应用来确定合适的事务隔离级别,这个地方没有万能的原则。
MySQL InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读)。我们可以通过SELECT @@tx_isolation;命令来查看,MySQL 8.0 该命令改为SELECT @@transaction_isolation;
这里需要注意的是:与 SQL 标准不同的地方在于InnoDB 存储引擎在REPEATABLE-READ(可重读)事务隔离级别下使用的是Next-Key Lock 算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)是不同的。所以说InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读)已经可以完全保证事务的隔离性要求,即达到了 SQL标准的 SERIALIZABLE(可串行化)隔离级别,而且保留了比较好的并发性能。
因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是READ-COMMITTED(读已提交):,但是你要知道的是InnoDB 存储引擎默认使用REPEATABLE-READ(可重读)并不会有任何性能损失。
MVCC 多版本并发控制
MySQL的大多数事务型存储引擎实现都不是简单的行级锁。基于提升并发性考虑,一般都同时实现了多版本并发控制(MVCC),包括Oracle、PostgreSQL。只是实现机制各不相同。
可以认为 MVCC 是行级锁的一个变种,但它在很多情况下避免了加锁操作,因此开销更低。虽然实现机制有所不同,但大都实现了非阻塞的读操作,写操作也只是锁定必要的行。
MVCC 的实现是通过保存数据在某个时间点的快照来实现的。也就是说不管需要执行多长时间,每个事物看到的数据都是一致的。
典型的MVCC实现方式,分为乐观(optimistic)并发控制和悲观(pressimistic)并发控制。下边通过 InnoDB的简化版行为来说明 MVCC 是如何工作的。
InnoDB 的 MVCC,是通过在每行记录后面保存两个隐藏的列来实现。这两个列,一个保存了行的创建时间,一个保存行的过期时间(删除时间)。当然存储的并不是真实的时间,而是系统版本号(system version number)。每开始一个新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。
REPEATABLE READ(可重读)隔离级别下MVCC如何工作:
SELECT
InnoDB会根据以下两个条件检查每行记录:
只有符合上述两个条件的才会被查询出来
InnoDB只查找版本早于当前事务版本的数据行,这样可以确保事务读取的行,要么是在开始事务之前已经存在要么是事务自身插入或者修改过的
行的删除版本号要么未定义,要么大于当前事务版本号,这样可以确保事务读取到的行在事务开始之前未被删除
INSERT:InnoDB为新插入的每一行保存当前系统版本号作为行版本号
DELETE:InnoDB为删除的每一行保存当前系统版本号作为行删除标识
UPDATE:InnoDB为插入的一行新纪录保存当前系统版本号作为行版本号,同时保存当前系统版本号到原来的行作为删除标识
保存这两个额外系统版本号,使大多数操作都不用加锁。使数据操作简单,性能很好,并且也能保证只会读取到符合要求的行。不足之处是每行记录都需要额外的存储空间,需要做更多的行检查工作和一些额外的维护工作。
MVCC 只在 COMMITTED READ(读提交)和REPEATABLE READ(可重复读)两种隔离级别下工作。
事务日志
InnoDB 使用日志来减少提交事务时的开销。因为日志中已经记录了事务,就无须在每个事务提交时把缓冲池的脏块刷新(flush)到磁盘中。
事务修改的数据和索引通常会映射到表空间的随机位置,所以刷新这些变更到磁盘需要很多随机 IO。
InnoDB 假设使用常规磁盘,随机IO比顺序IO昂贵得多,因为一个IO请求需要时间把磁头移到正确的位置,然后等待磁盘上读出需要的部分,再转到开始位置。
InnoDB 用日志把随机IO变成顺序IO。一旦日志安全写到磁盘,事务就持久化了,即使断电了,InnoDB可以重放日志并且恢复已经提交的事务。
InnoDB 使用一个后台线程智能地刷新这些变更到数据文件。这个线程可以批量组合写入,使得数据写入更顺序,以提高效率。
事务日志可以帮助提高事务效率:
使用事务日志,存储引擎在修改表的数据时只需要修改其内存拷贝,再把该修改行为记录到持久在硬盘上的事务日志中,而不用每次都将修改的数据本身持久到磁盘。 事务日志采用的是追加的方式,因此写日志的操作是磁盘上一小块区域内的顺序I/O,而不像随机I/O需要在磁盘的多个地方移动磁头,所以采用事务日志的方式相对来说要快得多。 事务日志持久以后,内存中被修改的数据在后台可以慢慢刷回到磁盘。 如果数据的修改已经记录到事务日志并持久化,但数据本身没有写回到磁盘,此时系统崩溃,存储引擎在重启时能够自动恢复这一部分修改的数据。
目前来说,大多数存储引擎都是这样实现的,我们通常称之为预写式日志(Write-Ahead Logging),修改数据需要写两次磁盘。
事务的实现
事务的实现是基于数据库的存储引擎。不同的存储引擎对事务的支持程度不一样。MySQL 中支持事务的存储引擎有 InnoDB 和 NDB。
事务的实现就是如何实现ACID特性。
事务的隔离性是通过锁实现,而事务的原子性、一致性和持久性则是通过事务日志实现 。
❝事务是如何通过日志来实现的,说得越深入越好。
事务日志包括:重做日志redo和回滚日志undo
redo log(重做日志) 实现持久化和原子性
在innoDB的存储引擎中,事务日志通过重做(redo)日志和innoDB存储引擎的日志缓冲(InnoDB Log Buffer)实现。事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲中,在事务提交之前,这些缓冲的日志都需要提前刷新到磁盘上持久化,这就是DBA们口中常说的“日志先行”(Write-Ahead Logging)。当事务提交之后,在Buffer Pool中映射的数据文件才会慢慢刷新到磁盘。此时如果数据库崩溃或者宕机,那么当系统重启进行恢复时,就可以根据redo log中记录的日志,把数据库恢复到崩溃前的一个状态。未完成的事务,可以继续提交,也可以选择回滚,这基于恢复的策略而定。
在系统启动的时候,就已经为redo log分配了一块连续的存储空间,以顺序追加的方式记录Redo Log,通过顺序IO来改善性能。所有的事务共享redo log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起。
undo log(回滚日志) 实现一致性
undo log 主要为事务的回滚服务。在事务执行的过程中,除了记录redo log,还会记录一定量的undo log。undo log记录了数据在每个操作前的状态,如果事务执行过程中需要回滚,就可以根据undo log进行回滚操作。单个事务的回滚,只会回滚当前事务做的操作,并不会影响到其他的事务做的操作。
Undo记录的是已部分完成并且写入硬盘的未完成的事务,默认情况下回滚日志是记录下表空间中的(共享表空间或者独享表空间)
二种日志均可以视为一种恢复操作,redo_log是恢复提交事务修改的页操作,而undo_log是回滚行记录到特定版本。二者记录的内容也不同,redo_log是物理日志,记录页的物理修改操作,而undo_log是逻辑日志,根据每行记录进行记录。
❝又引出个问题:你知道MySQL 有多少种日志吗?
错误日志:记录出错信息,也记录一些警告信息或者正确的信息。
查询日志:记录所有对数据库请求的信息,不论这些请求是否得到了正确的执行。
慢查询日志:设置一个阈值,将运行时间超过该值的所有SQL语句都记录到慢查询的日志文件中。
二进制日志:记录对数据库执行更改的所有操作。
中继日志:中继日志也是二进制日志,用来给slave 库恢复
事务日志:重做日志redo和回滚日志undo
❝分布式事务相关问题,可能还会问到 2PC、3PC,,,
MySQL对分布式事务的支持
分布式事务的实现方式有很多,既可以采用 InnoDB 提供的原生的事务支持,也可以采用消息队列来实现分布式事务的最终一致性。这里我们主要聊一下 InnoDB 对分布式事务的支持。
MySQL 从 5.0.3 InnoDB 存储引擎开始支持XA协议的分布式事务。一个分布式事务会涉及多个行动,这些行动本身是事务性的。所有行动都必须一起成功完成,或者一起被回滚。
在MySQL中,使用分布式事务涉及一个或多个资源管理器和一个事务管理器。
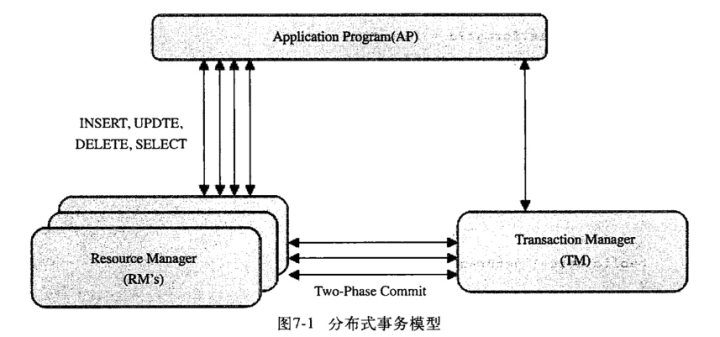
如图,MySQL 的分布式事务模型。模型中分三块:应用程序(AP)、资源管理器(RM)、事务管理器(TM):
应用程序:定义了事务的边界,指定需要做哪些事务; 资源管理器:提供了访问事务的方法,通常一个数据库就是一个资源管理器; 事务管理器:协调参与了全局事务中的各个事务。
分布式事务采用两段式提交(two-phase commit)的方式:
第一阶段所有的事务节点开始准备,告诉事务管理器ready。 第二阶段事务管理器告诉每个节点是commit还是rollback。如果有一个节点失败,就需要全局的节点全部rollback,以此保障事务的原子性。