
机器学习模型迭代方法(Python)
一、模型迭代方法
机器学习模型在实际应用的场景,通常要根据新增的数据下进行模型的迭代,常见的模型迭代方法有以下几种:
1、全量数据重新训练一个模型,直接合并历史训练数据与新增的数据,模型直接离线学习全量数据,学习得到一个全新的模型。优缺点:这也是实际最为常见的模型迭代方式,通常模型效果也是最好的,但这样模型迭代比较耗时,资源耗费比较多,实时性较差,特别是在大数据场景更为困难;
2、模型融合的方法,将旧模型的预测结果作为一个新增特征,在新的数据上面训练一个新的模型;优缺点:训练耗时较短了,增加决策的复杂度,新增数据量要足够多才能保证融合效果;
3、增量(在线)学习的方法,如sklearn中算法可调用partial_fit直接增量学习,可以直接利用新增的数据在原来的模型的基础上做进一步更新。增量学习对于模型迭代是很有效率的(特别适用于神经网络的学习,如 arxiv.org/abs/1711.03705)。实际使用中,在线学习和离线的全量学习经常是结合使用,比如离线以全量数据训练一个复杂的模型,在线利用新增样本进行微调。优缺点:对内存友好,模型迭代快且效率较高;
二、增量学习
主流的几种机器学习框架,已经实现了增量学习的功能,像sklearn可以直接调用partial_fit做增量学习,神经网络增量学习也很方便,如下tensorflow.keras框架实现增量学习:
# tensorflow.keras增量学习model_path = 'init.model' #加载线上的原模型loaded_model = tf.keras.models.load_model(model_path)# 新数据上接着训练原模型history = loaded_model.fit(train_data_gen,epochs=epochs)
本文主要对树模型的增量(在线)学习展开介绍,如下以树模型lightgbm及xgboost增量学习金融违约的分类模型为例,验证实际的效果。示例沿用之前文章的数据集:一文梳理金融风控建模全流程(Python))
开始之前,我们先把数据划分为训练集及测试集,测试集数据仅做评估。接着训练数据再划分为两部分:旧训练数据,新训练数据集。以此验证用增量学习方法进行学习新数据集的效果
# 划分数据集:训练集和测试集train_x, test_x, train_y, test_y = train_test_split(train_bank[num_feas + cate_feas], train_bank.isDefault,test_size=0.3, random_state=0)# 训练集再划分新旧的训练集,新的训练集用增量学习方法进行学习trainold_x, trainnew_x, trainold_y, trainnew_y = train_test_split(train_x, train_y,test_size=0.5, random_state=0)lgb_train = lgb.Dataset(trainold_x, trainold_y)lgb_newtrain = lgb.Dataset(trainnew_x, trainnew_y)lgb_eval = lgb.Dataset(test_x,test_y, reference=lgb_train)
训练原始的lightgbm模型,评估模型效果还算不错:train {'AUC': 0.8696629477540933, 'KS': 0.6470059543871476} test {'AUC': 0.8458304576799567, 'KS': 0.6284431987999525}
# 参数params = {'task': 'train','boosting_type': 'gbdt', # 设置提升类型'objective': 'binary', # 目标函数'metric': {'l2', 'auc'}, # 评估函数'num_leaves': 12, # 叶子节点数'learning_rate': 0.05, # 学习速率'feature_fraction': 0.9, # 建树的特征选择比例'bagging_fraction': 0.8, # 建树的样本采样比例'verbose': 1}# 模型训练gbm = lgb.train(params, lgb_train, num_boost_round=1)print('train ',model_metrics(gbm,trainold_x, trainold_y))print('test ',model_metrics(gbm,test_x,test_y))# 树模型决策的可视化# 需要先安装https://graphviz.org/download/import osos.environ["PATH"] += os.pathsep + 'D:/Program Files/Graphviz/bin/'for k in range(1):ax = lgb.plot_tree(gbm, tree_index=k, figsize=(30,20), show_info=['split_gain','internal_value','internal_count','internal_weight','leaf_count','leaf_weight','data_percentage'])plt.show()
打印出原始树模型的结构如下: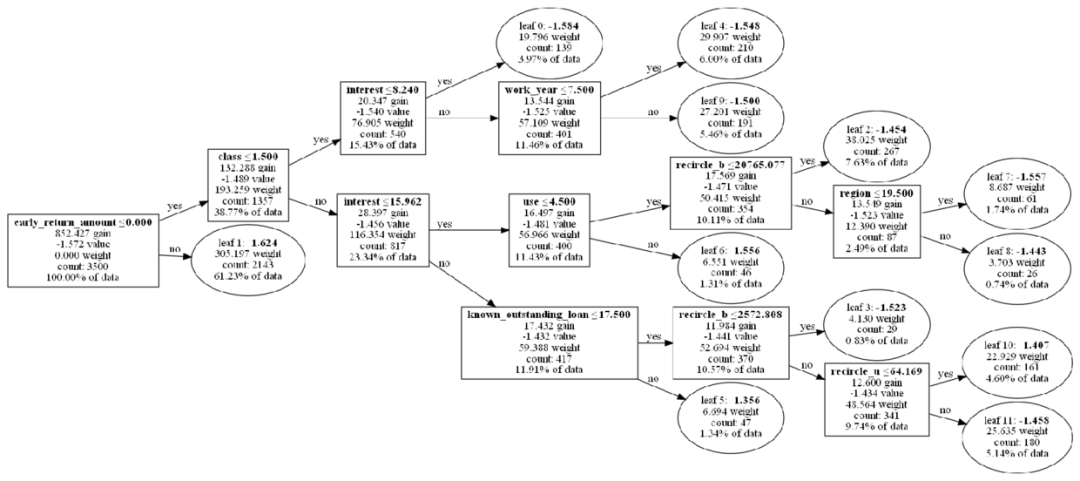
接下来就是本文的重点了,增量学习新的lightgbm树模型,我们在原有gbm模型的基础上继续更新模型为gbm2。
其实,lightgbm增量学习的更新方式其实就是原有模型的树结构都不变的基础上,继续添加学习一些树,比如如下代码我们会继续训练出2棵新的树,
num_boost_round = 2 # 继续训练2颗树gbm2 = lgb.train(params,lgb_newtrain, #新的数据num_boost_round=num_boost_round ,init_model=gbm, #在原模型gbm的基础上接着训练verbose_eval=False,keep_training_booster=True) # 支持模型增量训练
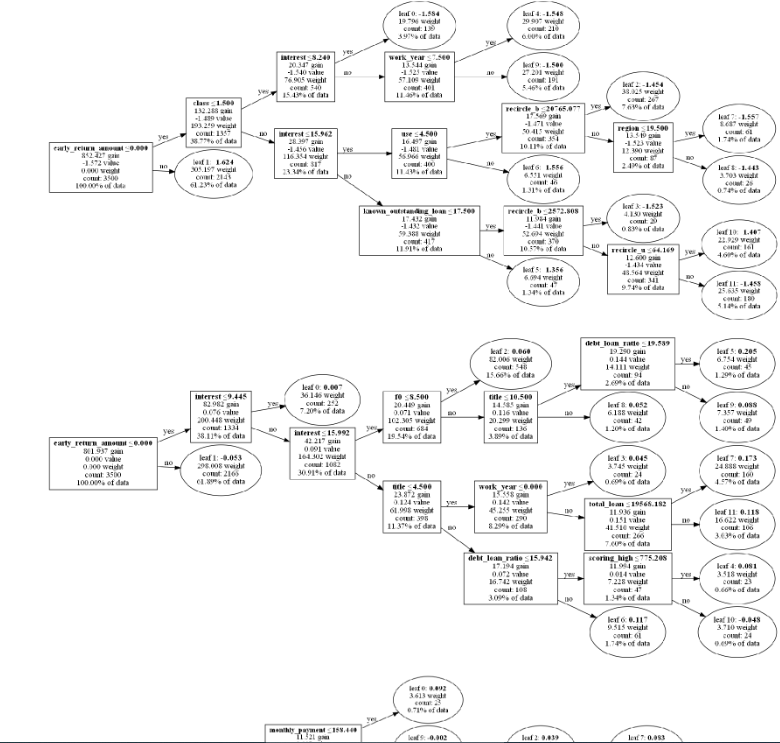
从增量学习后的树模型的结构,可以看出原有树模型gbm结构一点都没有变,只是再后面更新了2棵新的树。验证增量学习更新后的模型效果,测试集的auc是有提升1%左右的(注:本例无考虑调参下的效果差异,仅从效果来看是还不错的~)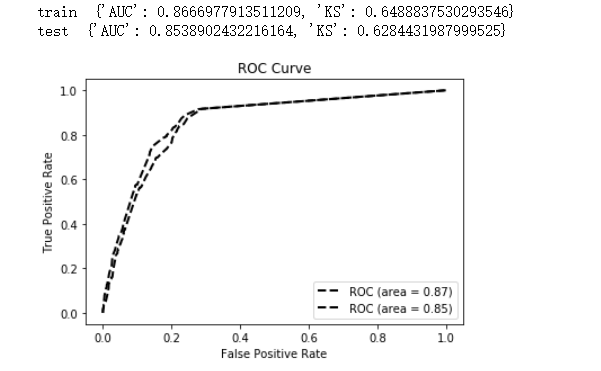
这时就有个疑问了,树模型的增量学习只有像类似“打补丁”的更新方式吗,不能通过更新下旧模型的叶子节点的权重?
其实,这两种增量学习方法,树模型可以有的,但是对于lightgbm我没有找到支持的方法,有兴趣的同学可以再了解下。。如下为XGBOOST实现两种增量学习的方法
### xgbooost 增量学习 https://xgboost.readthedocs.io/en/latest/parameter.htmlimport xgboost as xgbimport pprintxgb_params_01 = {}# 增量学习的方法一xgb_params_02 = {'process_type': 'default', # default, update'refresh_leaf': True} # 当前迭代树的结构不变,并在此增加新树# 增量学习的方法二xgb_params_02 = {'process_type': 'update', # default, update'updater': 'refresh', # 也可以选择再当前模型做剪枝'refresh_leaf': True} # 仅重新更新模型的叶节点权重,dtrain_2class = xgb.DMatrix(train_x[num_feas], label=train_y,enable_categorical=True)gbdt = xgb.train(xgb_params_01, dtrain_2class, num_boost_round=1) # 旧模型pprint.pprint(gbdt.get_dump())gbdt = xgb.train(xgb_params_02, dtrain_2class, num_boost_round=2, xgb_model=gbdt) # 更新模型pprint.pprint(gbdt.get_dump())
阅读原文访问文章代码,欢迎点赞在看转发三连!