
利用Python将Word试卷匹配转换为Excel表格
回复“书籍”即可获赠Python从入门到进阶共10本电子书
需求
有一个下面这种形式的word表格:

希望能转换为下面这种格式的excel表格:

测试word文档读取
先测试一个word文档前1页的数据读取:
from docx import Document
doc = Document("编号02 质检员高级技师(一级)理论试卷.docx")
for i, paragraph in enumerate(doc.paragraphs[:55]):
print(i, paragraph.text)
0 职业能力评价理论试卷
1 (一级. 质检员)
2 注意事项:1.答卷前将密封线内的项目填写清楚。
3 2.填写答案必须用蓝色(或黑色)钢笔、圆珠笔,不许用铅笔或红笔。
4 3.本份试卷共四道大题,满分100分,考试时间120分钟。
5 一、单项选择题(第1~40题。选择正确的答案,将相应的字母填入题内的括号中。每题1分,满分40分。)
6 1. 关于道德的叙述,正确的是( )。
7 (A)道德中的“应该”与“不应该”因人而异,没有共同道德标准
8 (B)道德是处理人与人之间、人与社会之间关系的特殊行为规范
9 (C)道德是现代文明的产物
10 (D)道德从来没有阶级性
11 2.以下哪个选项不属于遵守职业纪律( )。
12 (A)右侧行驶 (B)客人先行 (C)先抑后扬 (D)下班锁门
13 3. 国际标准化组织ISO9000:2000标准中,把质量定义为一组( )特性满足要求的程度。
14 (A)常量 (B)变量 (C) 流动 (D)固有
15 4. 软件是有通过载体表达的信息所组成的( )产品。
16 (A)知识 (B)信息 (C)数据 (D)标准
17 5. ( )是指由最高管理者正式发布的与质量有关的组织总的意图和方向。
18 (A)质量目标 (B)质量方针 (C)质量管理 (D)质量控制
19 6. ISO9000族当中,( )和八项管理原则一直是最核心的内容。
20 (A)PCDA模式 (B)PCDA循环 (C)PDCA模式 (D)PDCA循环
21 7.( )是第一家实施六西格玛管理的公司。
22 (A)通用电气 (B)摩托罗拉
23 (C)丰田 (D)微软
24 8. 产生、形成、实现、使用和衰亡的过程,质量专家朱兰称质量形成的这种过程为( )。
25 (A)质量螺旋 (B)质量周期 (C)产品螺旋 (D)产品周期
26 9. 计量值数据是指可以连续取值的数据,又称( )数据。
27 (A)计量型 (B)连续型 (C)稳定型 (D)常规型
28 10. 国家标准当中强制性标准用( )指代含义。
29 (A)CCC (B)GB (C)GB/T (D)CCIB
30 11. 异常波动能引起系统性的( )。
31 (A)失误或停滞 (B) 错误或中断 (C) 失效或缺陷 (D) 失败或终止
32 12.( )是判断和预报生产过程中质量状况是否发生波动的一种有效方法。
33 (A)分布图 (B) 质量图 (C) 控制图 (D) 控制界限
34 13. 过程能力一般采用标准差的6倍即6σ来量度,其计算公式为( )。
35 (A)B=6σ≈6S=24(R/dn) (B)B=6σ≈6S=12(R/d₂)
36 (C)B=6σ≈6S=6(R/dn) (D)B=6σ≈6S=6(R/d₂)
37 14. 提高过程能力的重要途径之一就是尽量减少σ,使质量特征值的离散程度( )。
38 (A)变大 (B)变小 (C)平稳 (D)不变
39 15.( )亦称频数分布图,它适用于对大量计量值数数据进行整理加工,找出其统计规律。
40 (A)直方图 (B)散布图
41 (C)排列图 (D)控制图
42 16. 因素在实验中所处的状态和条件变化可能引起指标变动,把因素变化各种状态和条件成为因素的( )。
43 (A)因子 (B)位级 (C)强度 (D)状态
44 17. 1988年提出的一种确定客户需求和相应产品或服务性能之间联系的图示方法叫做( )。
45 (A)质量屋 (B)顾客需求 (C)技术要求 (D)关系矩阵
46 18. ( )是指产品在存放和使用过程中,随着时间的推移而直接影响产品质量特性稳定性的因素。
47 (A)外噪声 (B)内噪声 (C)随机噪声 (D)以上都不对·
48 19. ( )是产品设计的核心,在系统设计确定了产品或系统的目的功能及结构之后进行。
49 (A)参数设计 (B)常量设计 (C)变量设计 (D)系统设计
50 20. 以下不属于“双五归零”基本术语的是( )。
51 (A)质量问题 (B)质量缺陷
52 (C)重复性质量问题 (D)产品交付前的质量问题
53 21. 质量检验当中,( )可以保证工艺过程的质量符合性。
54 (A)进货检验 (B)过程检验 (C)工艺检验 (D)最终检验从读取效果上看,各行文本数据都能很顺利的获取到。
匹配题型、题目和具体的选项
现在我们需要做的是就是匹配题型、题目和具体的选项,观察可以发现规律:
题型以大写数字开头 题目以普通数字+.开头 选项以括号+字母开头
❝额外需要注意的:
❞
开头几行文本也存在普通数字+.开头的,需要直接排除。 第7题的题目,和第19题的选项存在一些特殊的空白字符需要排除, 括号和小数点都同时存在半角和全角两种情况。
对于需要注意的第二点:
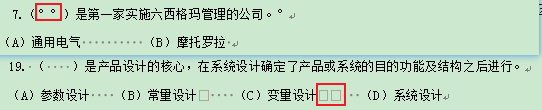
查看一下这2处的空白字符:
doc.paragraphs[21].text
'7.(\xa0\xa0)是第一家实施六西格玛管理的公司。\xa0'doc.paragraphs[49].text
'(A)参数设计 (B)常量设计\u3000 (C)变量设计\u3000\u3000 (D)系统设计'发现分别是\xa0和\u3000。
整理好大致思路,我组织一下处理代码:
import re
from docx import Document
doc = Document("编号02 质检员高级技师(一级)理论试卷.docx")
black_char = re.compile("[\s\u3000\xa0]+")
chinese_nums_rule = re.compile("[一二三四]、(.+?)\(")
title_rule = re.compile("\d+.")
option_rule = re.compile("\([ABCDEF]\)")
option_rule_search = re.compile("\([ABCDEF]\)[^(]+")
# 从word文档的“一、单项选择题”开始遍历数据
for paragraph in doc.paragraphs[5:25]:
# 去除空白字符,将全角字符转半角字符,并给括号之间调整为中间二个空格
line = black_char.sub("", paragraph.text).replace(
"(", "(").replace(")", ")").replace(".", ".").replace("()", "( )")
# 对于空白行就直接跳过
if not line:
continue
if title_rule.match(line):
print("题目", line)
elif option_rule.match(line):
print("选项", option_rule_search.findall(line))
else:
chinese_nums_match = chinese_nums_rule.match(line)
if chinese_nums_match:
print("题型", chinese_nums_match.group(1))
题型 单项选择题
题目 1.关于道德的叙述,正确的是( )。
选项 ['(A)道德中的“应该”与“不应该”因人而异,没有共同道德标准']
选项 ['(B)道德是处理人与人之间、人与社会之间关系的特殊行为规范']
选项 ['(C)道德是现代文明的产物']
选项 ['(D)道德从来没有阶级性']
题目 2.以下哪个选项不属于遵守职业纪律( )。
选项 ['(A)右侧行驶', '(B)客人先行', '(C)先抑后扬', '(D)下班锁门']
题目 3.国际标准化组织ISO9000:2000标准中,把质量定义为一组( )特性满足要求的程度。
选项 ['(A)常量', '(B)变量', '(C)流动', '(D)固有']
题目 4.软件是有通过载体表达的信息所组成的( )产品。
选项 ['(A)知识', '(B)信息', '(C)数据', '(D)标准']
题目 5.( )是指由最高管理者正式发布的与质量有关的组织总的意图和方向。
选项 ['(A)质量目标', '(B)质量方针', '(C)质量管理', '(D)质量控制']
题目 6.ISO9000族当中,( )和八项管理原则一直是最核心的内容。
选项 ['(A)PCDA模式', '(B)PCDA循环', '(C)PDCA模式', '(D)PDCA循环']
题目 7.( )是第一家实施六西格玛管理的公司。
选项 ['(A)通用电气', '(B)摩托罗拉']
选项 ['(C)丰田', '(D)微软']
题目 8.产生、形成、实现、使用和衰亡的过程,质量专家朱兰称质量形成的这种过程为( )。从目前测试结果来看没有问题。
保存匹配到的数据到结构化字典
现在我打算将当前匹配出来的文本数据存储成字典形式的结构化数据,字典结构的设计如下: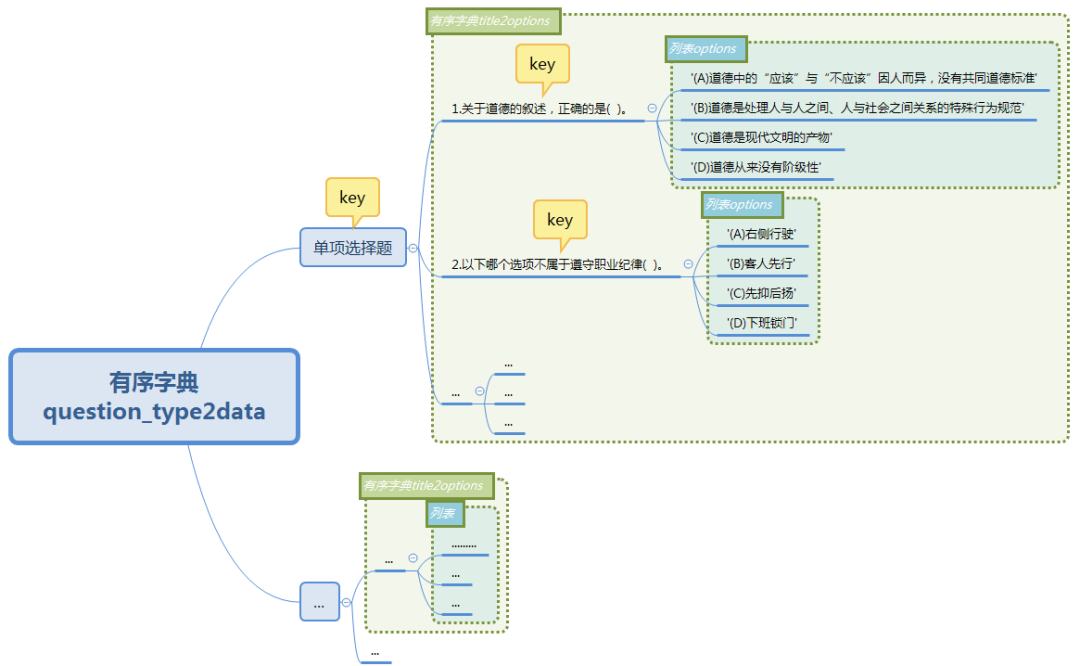
根据上述设计完善代码:
import re
from docx import Document
from collections import OrderedDict
doc = Document("编号02 质检员高级技师(一级)理论试卷.docx")
black_char = re.compile("[\s\u3000\xa0]+")
chinese_nums_rule = re.compile("[一二三四]、(.+?)\(")
title_rule = re.compile("\d+.")
option_rule = re.compile("\([ABCDEF]\)")
option_rule_search = re.compile("\([ABCDEF]\)[^(]+")
# 保存最终的结构化数据
question_type2data = OrderedDict()
# 从word文档的“一、单项选择题”开始遍历数据
for paragraph in doc.paragraphs[5:]:
# 去除空白字符,将全角字符转半角字符,并给括号之间调整为中间一个空格
line = black_char.sub("", paragraph.text).replace(
"(", "(").replace(")", ")").replace(".", ".").replace("()", "( )")
# 对于空白行就直接跳过
if not line:
continue
if title_rule.match(line):
options = title2options.setdefault(line, [])
elif option_rule.match(line):
options.extend(option_rule_search.findall(line))
else:
chinese_nums_match = chinese_nums_rule.match(line)
if chinese_nums_match:
question_type = chinese_nums_match.group(1)
title2options = question_type2data.setdefault(question_type, OrderedDict())
遍历结构化字典并存储
然后我们遍历结构化字典,将数据保存到pandas对象中:
import pandas as pd
result = []
max_options_len = 0
for question_type, title2options in question_type2data.items():
for title, options in title2options.items():
result.append([question_type, title, *options])
options_len = len(options)
if options_len > max_options_len:
max_options_len = options_len
df = pd.DataFrame(result, columns=[
"题型", "题目"]+[f"选项{i}" for i in range(1, max_options_len+1)])
# 题型可以简化下,去掉选择两个字
df['题型'] = df['题型'].str.replace("选择", "")
df.head()
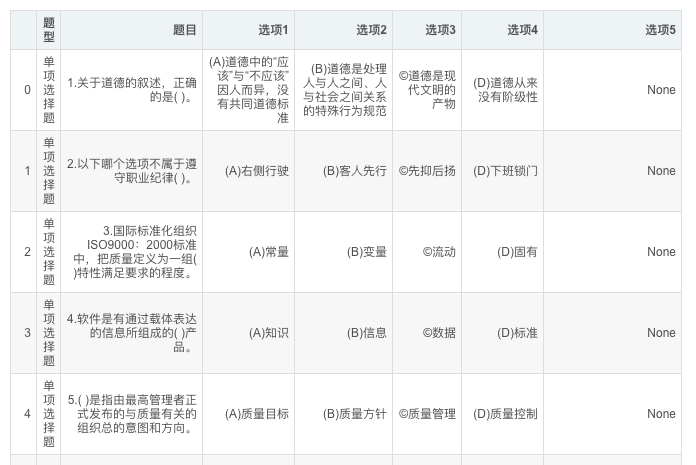
结果:
最终保存结果:
df.to_excel("result.xlsx", index=False)
完整代码
最终完整代码:
import pandas as pd
import re
from docx import Document
from collections import OrderedDict
doc = Document("编号02 质检员高级技师(一级)理论试卷.docx")
black_char = re.compile("[\s\u3000\xa0]+")
chinese_nums_rule = re.compile("[一二三四]、(.+?)\(")
title_rule = re.compile("\d+.")
option_rule = re.compile("\([ABCDEF]\)")
option_rule_search = re.compile("\([ABCDEF]\)[^(]+")
# 保存最终的结构化数据
question_type2data = OrderedDict()
# 从word文档的“一、单项选择题”开始遍历数据
for paragraph in doc.paragraphs[5:]:
# 去除空白字符,将全角字符转半角字符,并给括号之间调整为中间一个空格
line = black_char.sub("", paragraph.text).replace(
"(", "(").replace(")", ")").replace(".", ".").replace("()", "( )")
# 对于空白行就直接跳过
if not line:
continue
if title_rule.match(line):
options = title2options.setdefault(line, [])
elif option_rule.match(line):
options.extend(option_rule_search.findall(line))
else:
chinese_nums_match = chinese_nums_rule.match(line)
if chinese_nums_match:
question_type = chinese_nums_match.group(1)
title2options = question_type2data.setdefault(
question_type, OrderedDict())
result = []
max_options_len = 0
for question_type, title2options in question_type2data.items():
for title, options in title2options.items():
result.append([question_type, title, *options])
options_len = len(options)
if options_len > max_options_len:
max_options_len = options_len
df = pd.DataFrame(result, columns=[
"题型", "题目"]+[f"选项{i}" for i in range(1, max_options_len+1)])
# 题型可以简化下,去掉选择两个字
df['题型'] = df['题型'].str.replace("选择", "")
df.to_excel("result.xlsx", index=False)
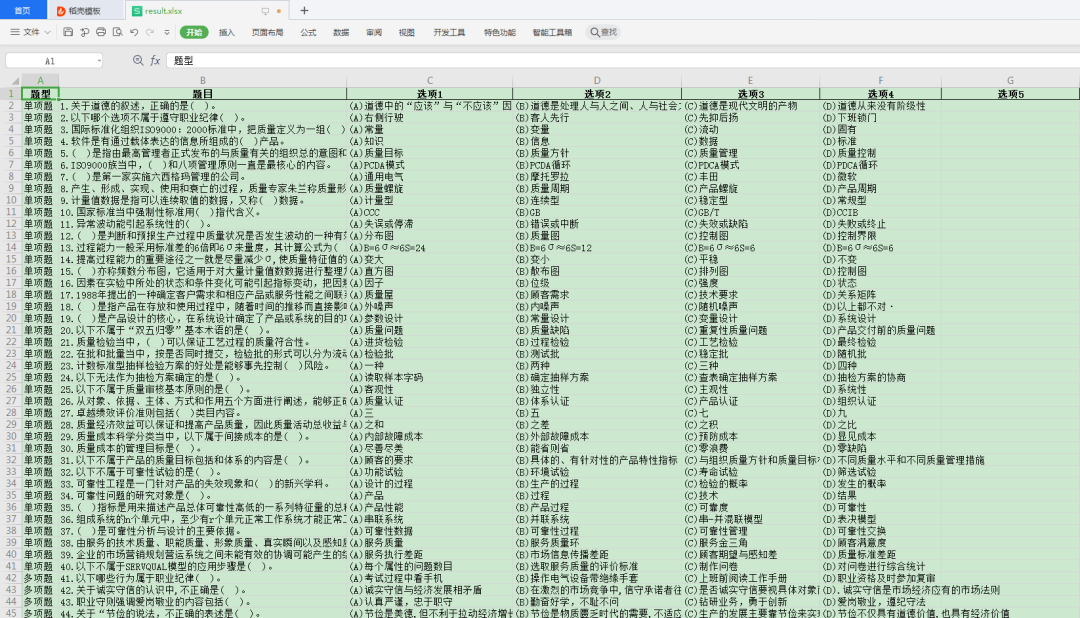
最终得到的文件:
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~
评论