
实战 | 我是怎么定位问题的?

定位问题
前阵子群里有个同学@我,让我分享下平时是怎么定位问题的,以及排查问题的思路。
甚至我还看到有的面试题也会问这种问题(是不是在校验真的做过线上项目?)
最近组内来了个新人实习生,正好我前几天也给他讲了我的排查问题步骤,今天来分享下我的经验。
这篇文章主要给还未参加工作的小白看的哈。
什么是日志
在初学的时候出现了些问题,要在网上提问,大多数网友都会让你把错误日志发出来看下,一起定位下原因。
但可能你还不知道什么是「日志」,因为平时写代码压根就不打日志,而排查问题try catch{e.printStackTrace();} 又不是不能用,平时运行代码就在本地环境下,写个锤子日志哟。
使不上,使不上...
所谓的「打日志」,按我的理解就是把系统运行过程中,你认为在关键的位置,记录些关键的信息。这些信息会写在运行程序的机器本地文件上。
(如果你是本地环境,那文件就写在本地的文件系统上)
(如果你是远程环境(一般Linux),那文件就写在Linux服务器上)
程序运行时错误或异常相关的信息,自然就是打日志的重点。
但现在日志其实不止承载着排查问题的角色了,很多数据收集都来源于日志。基于这种「采集数据」的日志,又有人给它取了另一个高大上的名字「打点」。
这里就不细说了,水很深,这里对小白而言,是把握不住的。网络的东西都是虚拟的,你们要是感兴趣,我改天再细讲。
谨慎地记录日志。生产环境禁止输出 debug 日志;有选择地输出 info 日志;如果使用 warn 来记录刚上线时的业务行为信息,一定要注意日志输出量的问题,避免把服务器磁盘撑爆,并记得及时删除这些观察日志。
大量地输出无效日志,不利于系统性能提升,也不利于快速定位错误点。记录日志时请思考:这些日志真的有人看吗?看到这条日志你能做什么?能不能给问题排查带来好处?
回到问题本身
系统问题产生,很多时候都来源于改动
发现系统出现问题,大多数来自于告警或者业务方(客服)反馈
一般遇到线上问题,在排查的时候,我们就需要考虑:系统最近是否有过改动
如果发布过,那就很可能是近期的发布导致的。所以,出现问题时,首先回想下是不是自己最近的发布改动造成的。
较严重的问题,直接回滚,别想着要保留完整的现场,业务稳定优先。
如果不太严重,去看看监控有没有异常突刺。监控无外乎:数据库监控、业务指标监控、接口调用监控。
如果较为明显的错误,一般监控就能看出端倪。
如果没看出端倪又或者说参数信息不全,那就得上服务器看日志(可能接了日志收集系统,在某个分布式日志系统平台上看)。但这不重要,反正有地方看请求链路信息就好了。
如果是自己写的代码,那自己也大概能猜出是什么原因造成的了。
如果不是自己写的代码,找到监控的入口,往上游追踪并看入参,一般也能定位到问题。
也有的情况下,自身对某个系统并不熟悉,代码都是前人写的,自己只是来维护的,业务只懂一点点。
这种硬着头皮也看不懂的,只能debug一步一步看。一般公司都有几套环境(线下->预发->线上),一般情况下我们是使用线下环境debug,但往往线下环境可能数据没那么全,所以有的时候也会到预发环境debug。
所谓的线下环境或者预发环境debug指的就是远程debug。无论是什么环境,跑的都是同一份代码,只是这份代码在不同的机器上跑,机器与机器之间分了隔离环境,正常的业务请求都会转发至线上环境上。
所以,远程debug实际上就是在远程机器上开放端口,本地直连端口进行debug。
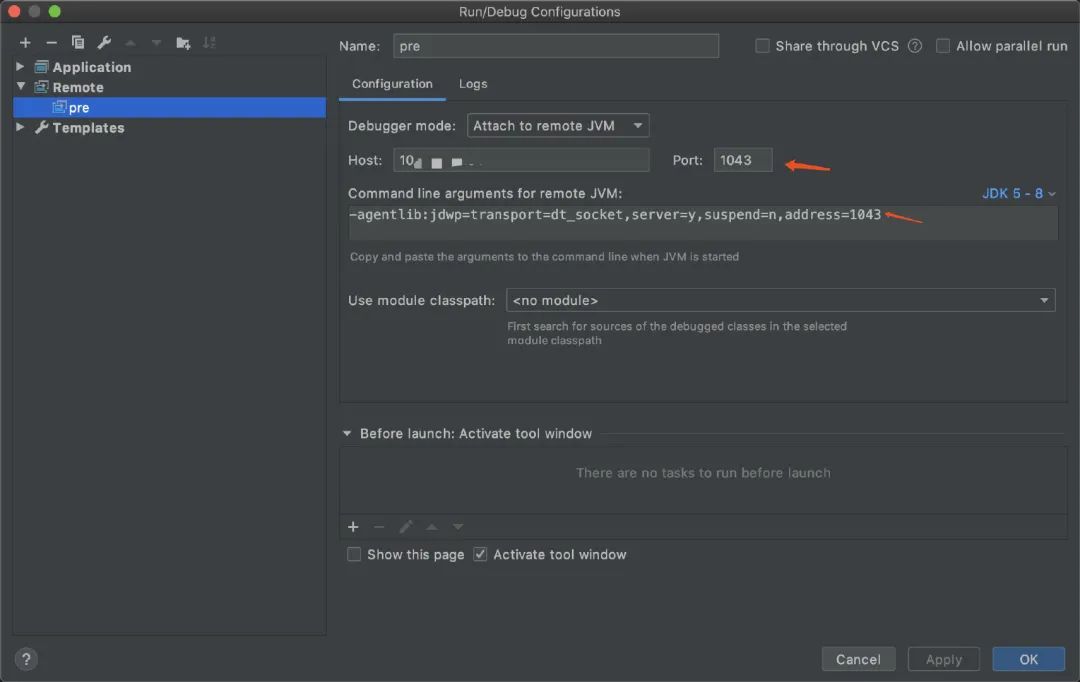
首先在线下or预发环境下增加端口配置
JAVA_OPTS="${JAVA_OPTS} -Xdebug -Xrunjdwp:transport=dt_socket,server=y,address=1043,suspend=n"
idea配置remote链接,指明ip和端口即可
基础设施
有的时候出现了问题,明明try catch之后就能定位到问题了,结果在catch后没打异常信息,还要重新发布定位问题...
有的时候出现了问题,明明加个告警就能提前发现,结果等到业务方反馈时,背了个故障...
有的时候出现了问题,明明加个监控就能快速定位问题,结果看了半天日志,甚至还得人肉计算QPS和量级...
有的时候出现了问题,明明可以通过开发些小工具来提高定位问题的效率,结果每次都要查半天,一天都查问题去了...
写代码除了实现功能之外,监控告警稳定性也是非常重要的一环,在开发时必须要把稳定性和维护性考虑进去!
事前预警,事中快速定位和处理,事后优化加强!
往期推荐
关注「开源Linux」加星标,提升IT技能
