一文读懂3D人脸识别十年发展及未来趋势
选自arXiv
人脸识别是机器学习社区研究最多的课题之一,以 3D 人脸识别为代表的相关 ML 技术十年来都有哪些进展?这篇文章给出了答案。


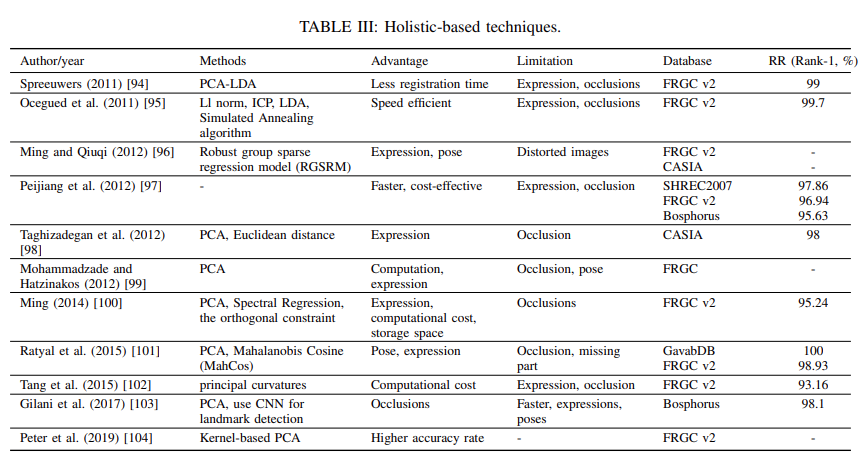
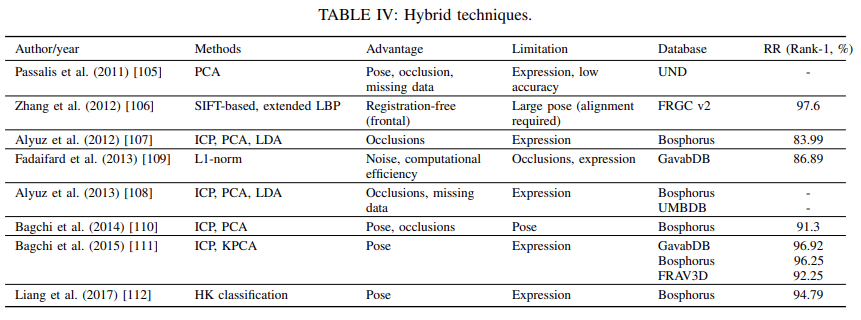
这是第一篇全面涵盖传统方法和基于深度学习的 3D 人脸识别方法的调查论文;
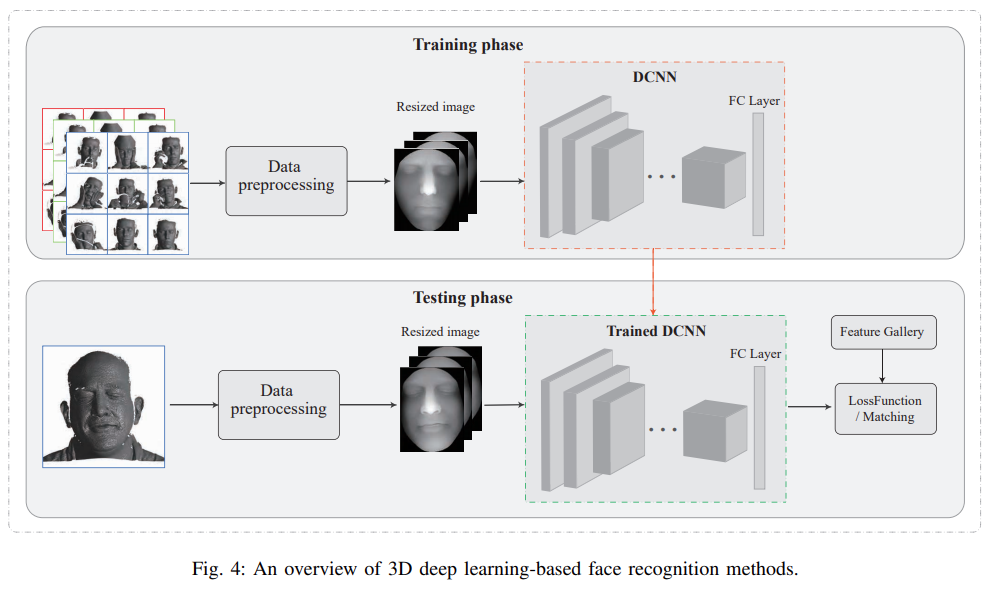
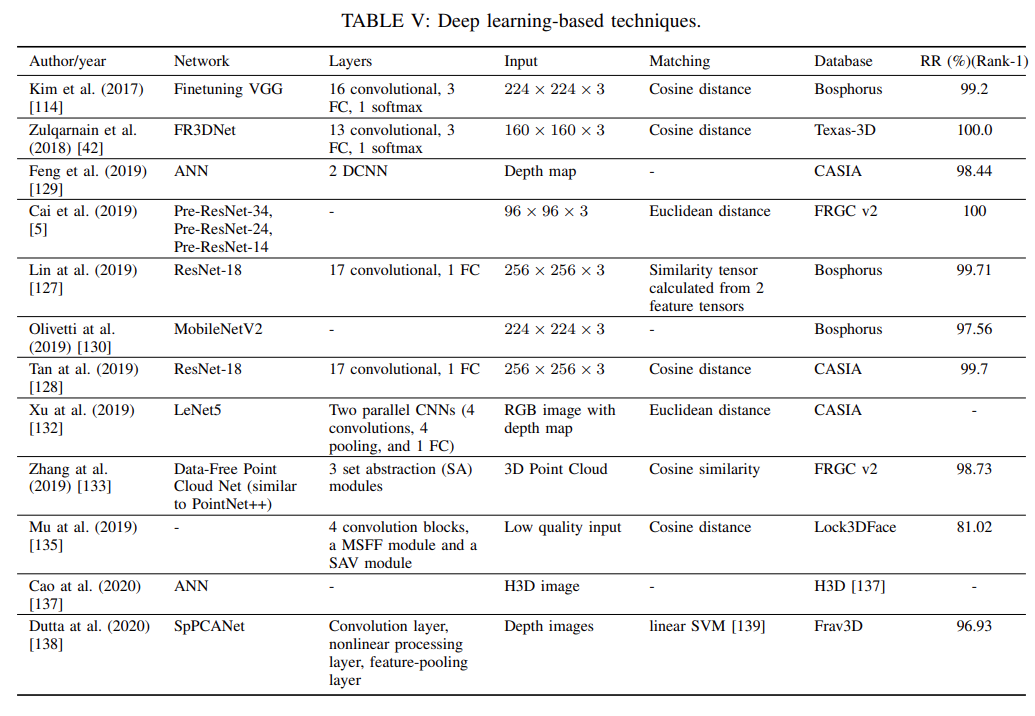
与现有调查不同,它特别关注基于深度学习的 3D 人脸识别方法;
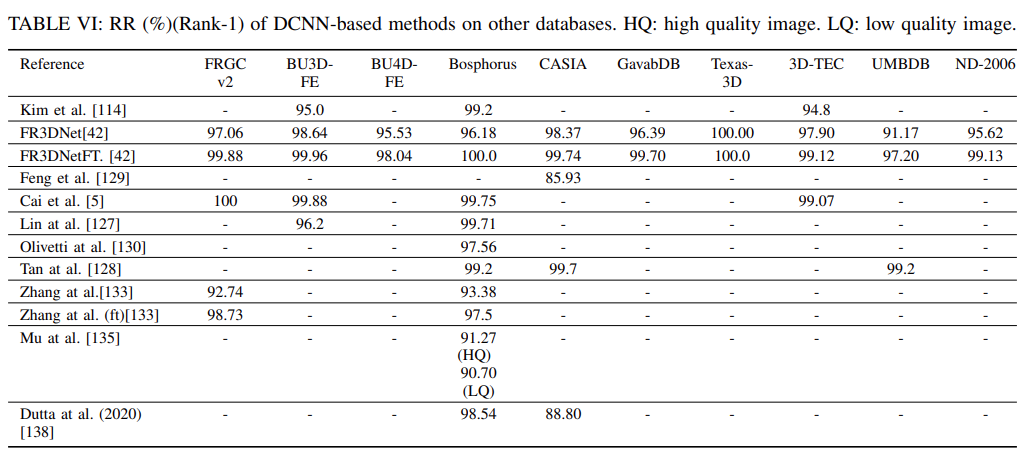
涵盖 3D 人脸识别最新、最前沿的发展,为 3D 人脸识别提供清晰的进度图;
它对可用数据集上的现有方法进行了全面比较,并提出了未来的研究挑战和方向。
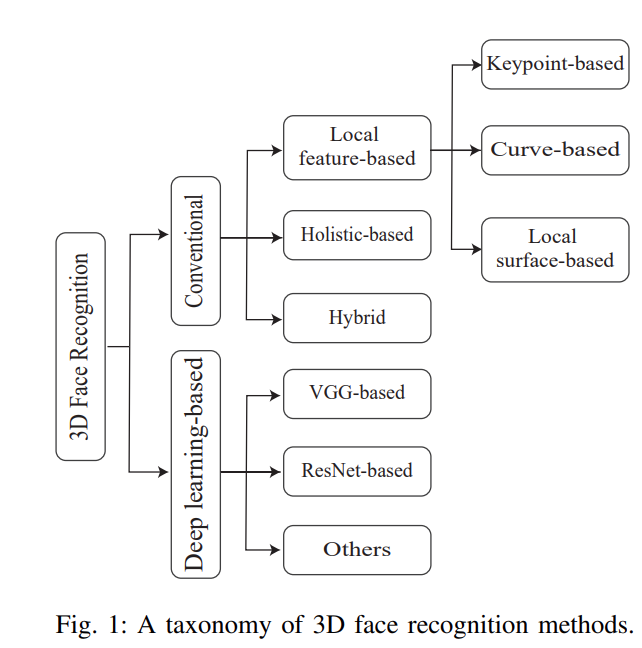
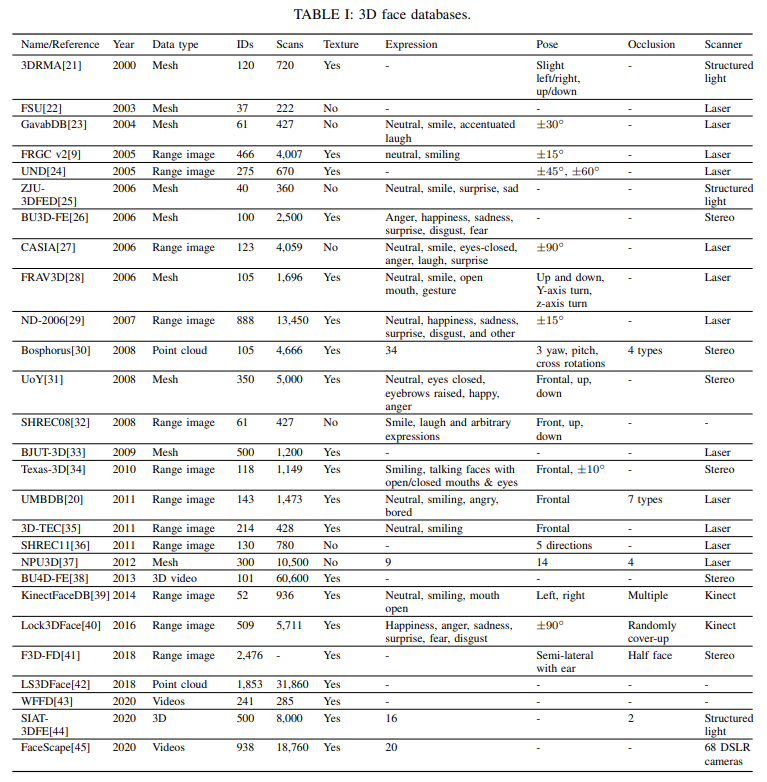

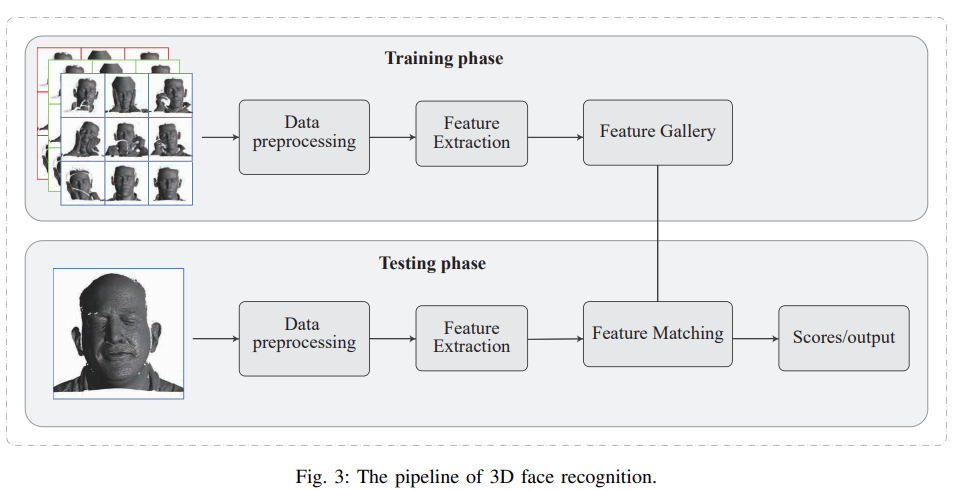
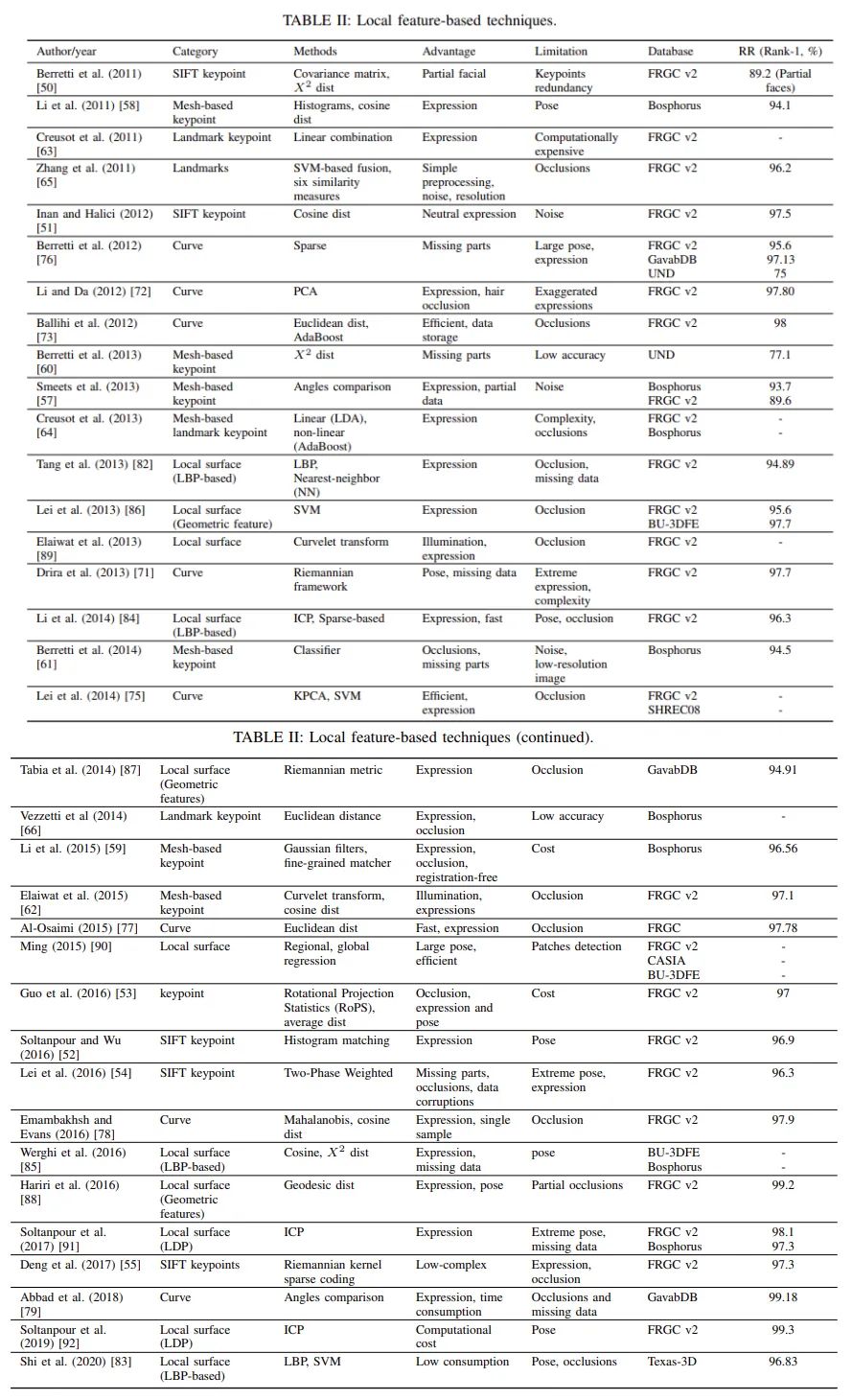


评论

选自arXiv
人脸识别是机器学习社区研究最多的课题之一,以 3D 人脸识别为代表的相关 ML 技术十年来都有哪些进展?这篇文章给出了答案。
这是第一篇全面涵盖传统方法和基于深度学习的 3D 人脸识别方法的调查论文;
与现有调查不同,它特别关注基于深度学习的 3D 人脸识别方法;
涵盖 3D 人脸识别最新、最前沿的发展,为 3D 人脸识别提供清晰的进度图;
它对可用数据集上的现有方法进行了全面比较,并提出了未来的研究挑战和方向。