
业界的多机房和单元化架构一般是怎么做的
共 2766字,需浏览 6分钟
·
2022-07-30 22:29

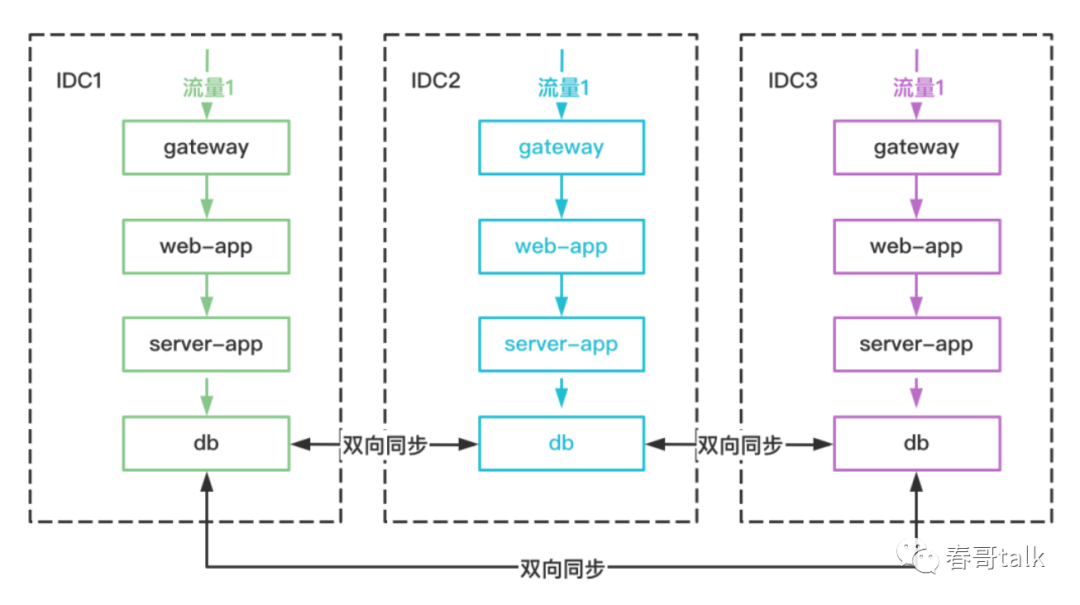
中心机房
除了双活业务外,长尾业务以及没法做多活的业务,都在中心机房。
单元机房
为服务双机房而新增的机房,用于承接主链路双活流量的机房。
路由
sharding_id作为路由code,双活系统根据路由规则,将请求参数转换为相应的路由code,每个路由code会对应中心机房或者单元机房。
网关层、中间件(如redis、db等分布式存储)都会根据路由code将流量路由到目标机房。
路由有三种方式:
- 随机路由:将流量按照一定比例路由到各自IDC,只需要按照比例路由即可,无需复杂规则。故障情况下,可以将故障机房的流量切到其他IDC。
- 用户ID路由:根据用户id将流量按照一定的比例路由到各自IDC,每个用户的操作都会被路由到同一个IDC。故障时,可以将故障机房的流量按照用户id规则变化,切换到其他机房即可。
- 地域路由:按照用户所在地区的流量按照一定比例路由到同一个机房,每个地区的用户操作的流量都会闭环在指定的IDC下。故障发生时,可以将故障机房流量按照用户切换到其他机房即可。
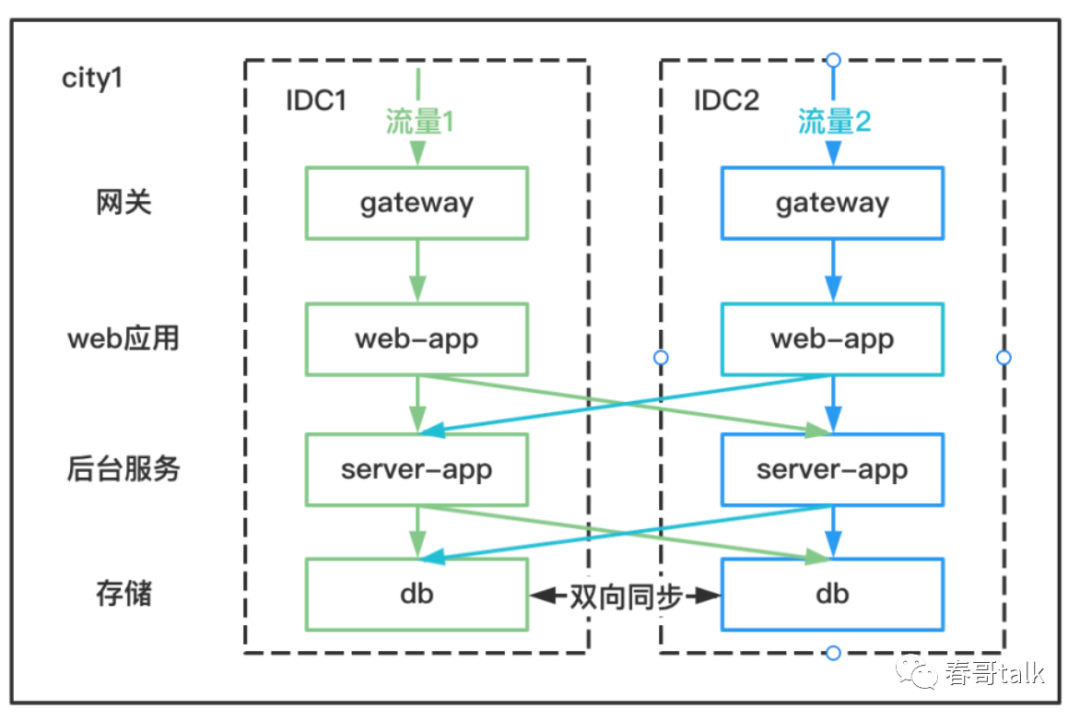
同城双活
就是在一个城市中双活部署,部署两个IDC。
异地双活
在两个城市进行双活部署,每个城市部署一个IDC。
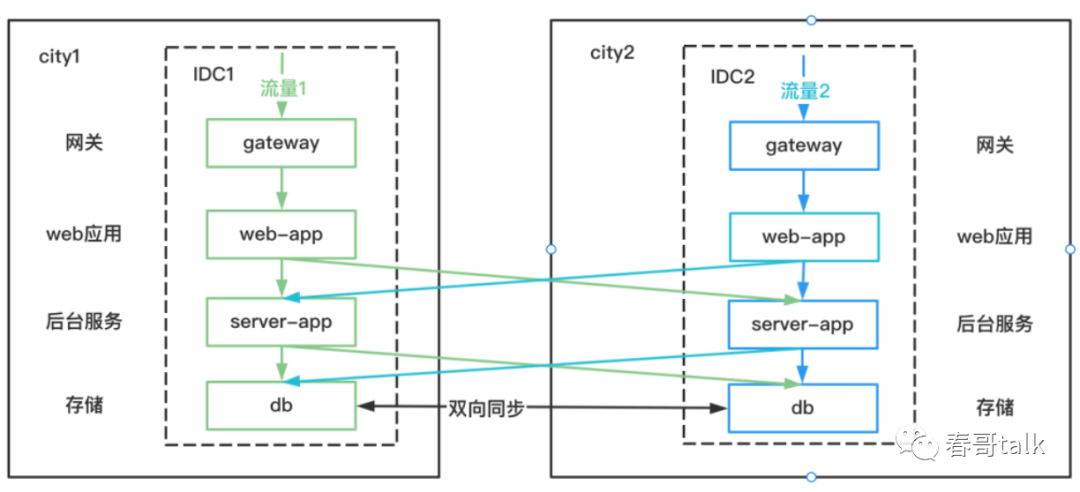
长尾业务或对延迟不敏感的业务可以发起远程调用,数据层做异步复制,采用最终一致性。
异地多活
在多个城市做多活部署,每个城市有一个或多个IDC。
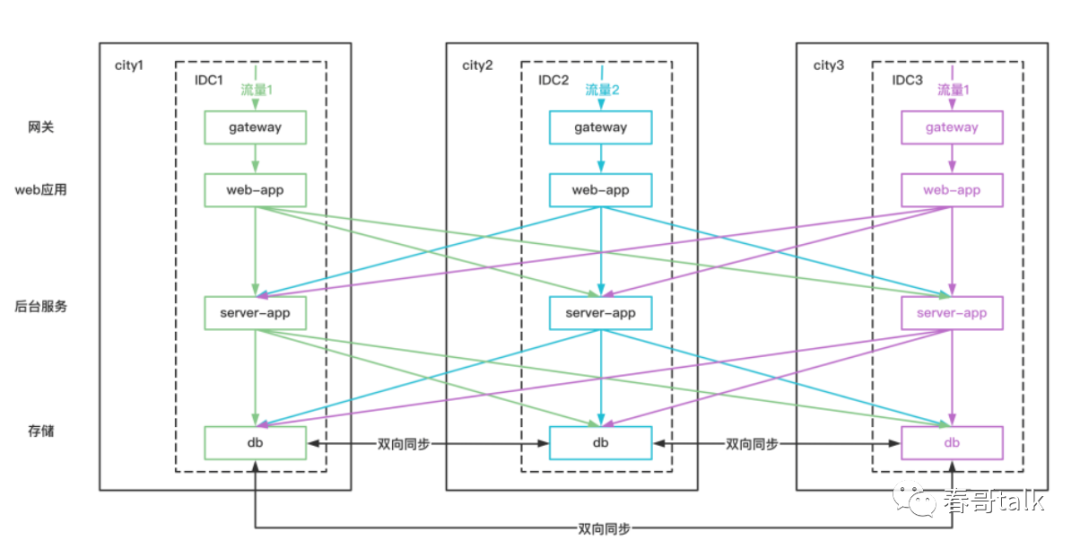
正常来说,同机房优先,同地区优先,最后才是异地机房访问。
同城双活:
- 优点:物理距离短,底层数据同步延迟低,rpc接口跨机房调用延迟低。
- 缺点:双活灾备能力不够,同城断电或自然灾害,无法双活。
异地双活:
- 优点:灾备相比于同城双活效果更好,可以做到城市级别容灾。
- 缺点:相对于同城物理距离长,底层数据同步存在一定的延迟,rpc的跨机房调用延迟相对较高。
异地多活:
- 优点:灾备较双活有一定提升。
- 缺点:多活之间涉及到多个IDC的数据同步,数据同步的延迟、一致性需要在架构层面做冗余考量,导致架构设计及服务部署相对复杂一些,服务调用链路变长,存在更高的rpc调用延迟。

单元化
一个业务请求tps达到几十万或者几百万的业务,在架构上,机房部署会出现瓶颈。
比如公司内某个业务发展很快,达到了几亿的tps,导致架构上无法快速扩缩容,而且机房内的电力、物理面积、机架都已经达到极限无法扩容,那么架构就很难支撑这种并发,而单元化理论上可以无限水平扩容架构能力。
单元化可以理解为异地多活的终极形态。
单元化在流量入口将流量按照规则分到不同的IDC,每个IDC分别承接自己的流量,且IDC之间流量不会相互调用。
单元化和区域无关,理论上做到单元化之后,新增的流量可以匹配新增的IDC解决,而新增的IDC不再受到区域限制,因为IDC不会有之前的流量进行调用。
判断架构是否已经做到单元化的标准是,流量是否可以自闭环。
比如A机房部署在上海,B机房部署在海外,如果A机房服务调用B机房服务,由于地理位置远,如果无法做到自闭环,那么RT势必会变长,影响业务。如果做到了单元化,则业务毫无影响,也就代表单元化成功了。
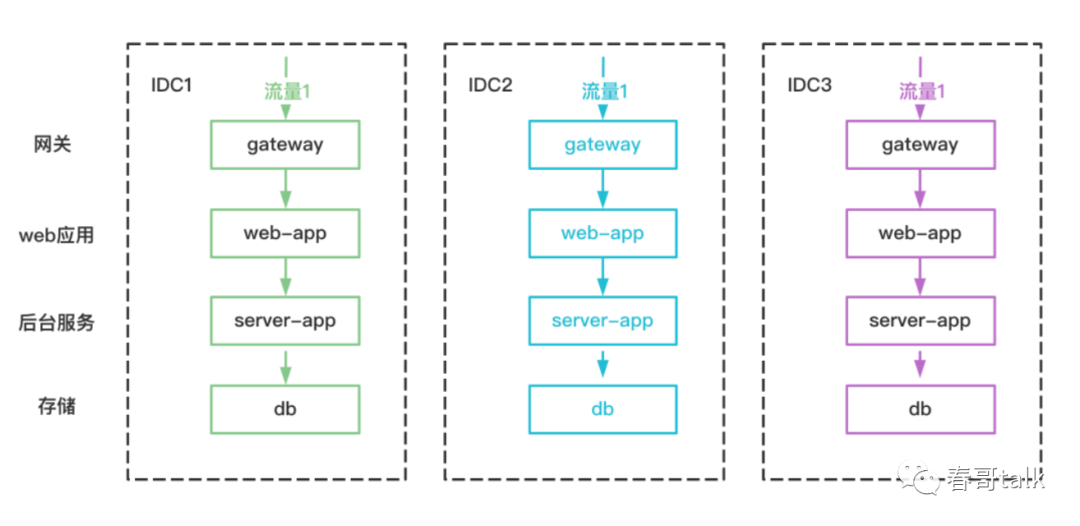
单元化机房之间做多活,只需要在底层的数据层做好数据同步即可。
随着O2O及移动化的发展,很多具有LBS属性的业务,采用的都是按照地区路由的方式实现了异地多活或者单元化架构。
主要理由是,随机路由在各种多活架构下,都不是一个好的方案,原因是随机路由无法确保规律性,多活架构本身就是复杂的技术架构,确定性越强越好。
选择地域路由的原因是,LBS类的业务区别于电商这种纯线上业务有自己的业务特点。
比如电商或者SNS基本上是围绕于C端用户,用户只关注于自己的订单即可,因此按照用户id路由其实是可以实现数据隔离的,单元化和多活都很好做。
但这种方案在LBS类的业务场景下,会牺牲B端商家的体验,商家的很多订单访问操作势必会跨机房,从而影响商家操作体验。
比如外卖业务C端用户和B端商家,比如网约车业务C端用户和B端司机,这种都属于双订单模型,就是需要从C、B两端共同考虑订单问题。
如果用户id路由,则b端用户在查询用户订单时,势必会跨机房路由。
而采用地域来分的话,由于订单很少跨城或者跨省的(哪怕有,概率也比较低),所以跨机房访问概率就很低,可以提升B、C两端用户体验。
针对于跨城市或地区访问的情况,其实通过大数据是可以很好的识别的,这样可以做一些中间方案解决这部分用户的体验问题。

为提供双活或单元化能力,需要对中间件进行一定的改造。
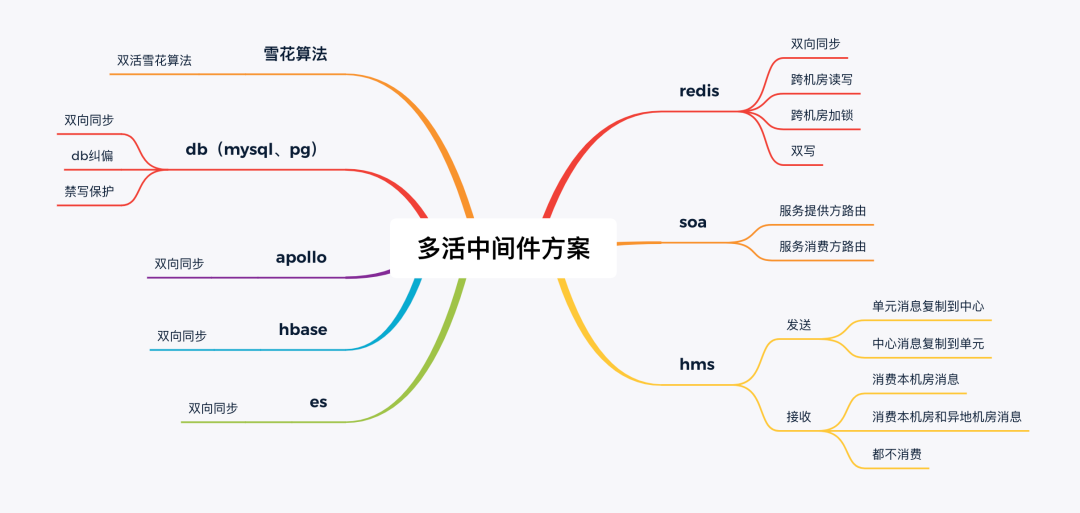
在存储层面,需要实现底层数据的双向同步。
redis的跨机房读写和跨机房加锁均是因为双订单模型无法做到单元化,提供的双活能力。
redis双写则为无双向同步能力时的临时能力。
db纠偏则是db层面指定路由,也是为了兜底,当soa路由出异常,在db层做最后的兜底(可访问跨机房数据)。
db禁写保护则是当业务开启禁写保护,非本机房的订单无法在本订单操作,也是db兜底保护的一种。
在MQ层面,可以将消息的发送和消费分开来看。
对于发送来说,单元到中心的复制和中心到单元的复制,则都是一个机房消息复制到另外机房,也是无法单元化的一种解决方案。当然该方案也可以兼容双活应用发送消息和非双活应用消费者的问题。
消费本机房:只能消费本机房产生的消息,异地机房的复制消息无法消费。
都不消费:代表本机房和异地机房都不消费。
消费本机房和异地机房消息,则代表消息消费本机房和异地机房消息(消费双份消息)。
在微服务架构层面,需要根据特定的条件,将rpc流量路由到正确的机房。
服务提供方路由则表示该路由规则由服务提供方指定。
服务消费方路由则表示该路由规则由服务消费方指定。
在发号器层面,比如在双活部署下,zk集群是双机房的,需要通过雪花算法打上机房标识,保证全局唯一。
对应的,在业务架构上也需要做一系列的改造。
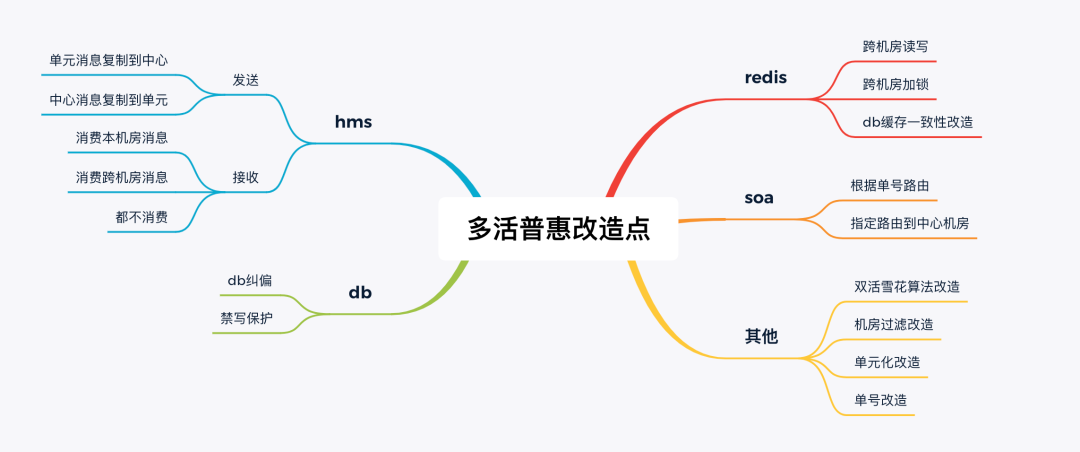
首先要对业务做单元化改造,涉及到一系列的存储,主从复制,rpc调用,逻辑梳理等工作。
在订单可靠性层面,需要考虑db和缓存的一致性问题,可以采用binlog消息双机房同步消费,保证数据一致性。
需要基于机房信息,做服务调用层面的请求过滤,过滤掉非本机房处理的数据逻辑。
订单单号生成,采用发号器,对订单的查询和修改时,根据订单的单号进行路由,将流量打到目标机房。
异地多活和多机房容灾,在过去是比较神秘高深的技术架构。这几年头部大厂的业务基本上都已经做了多机房或者异地容灾,实现了单元化,所以这部分技术已经不怎么神秘了。
也与头部的几家公司的架构师交流过,结论上差不多,就是方法论都很类似,差别的是技术债不同。
在跨机房延迟和数据一致性上,大家喜欢举的例子也是库存业务,看起来库存业务的一致性与稳定性确实是一个非常通用的技术难题。