
深入理解为什么MySQL全表扫描很慢?
先简单回顾下InnoDB数据页长什么样
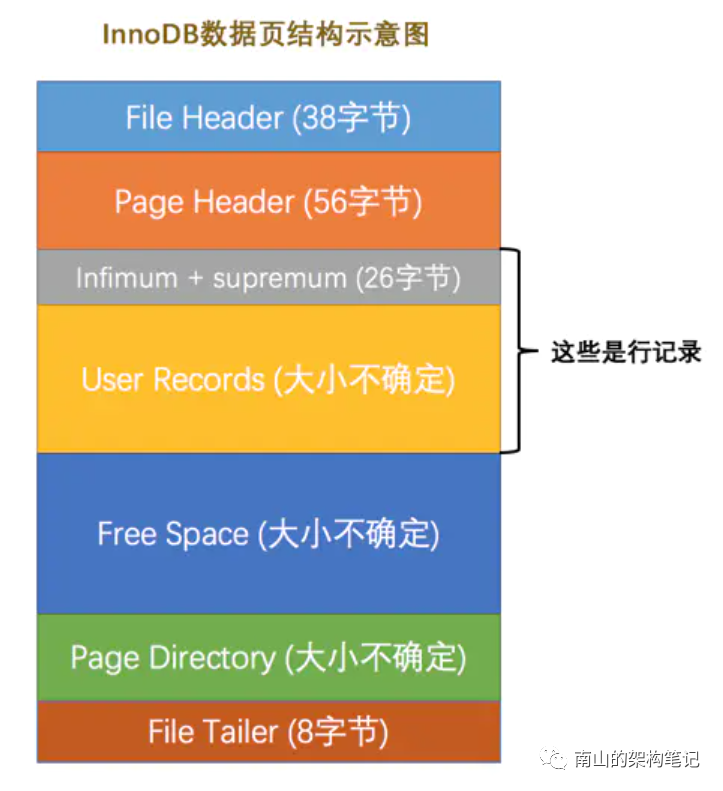
图1 InnoDB数据页结构示意图(图片来自网络)
其中有的部分没有详细讲解,因为暂时还用不到。比如Page Directory页目录。
上面讲了数据页的内部结构,数据库最终所有的数据都是要放到磁盘上去的,那么大量的数据页在磁盘上是怎么存储的呢?其实数据页之间会通过双向链表连接起来。
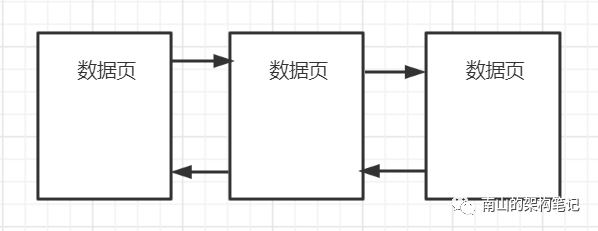
图2 数据页双向链表连接起来
内存中的双向链表大家都能理解,那么磁盘上的双向链表是怎么搞的呢?
其实,数据页在磁盘上就是一段数据,里面包含的两个指针,一个指向自己上一个数据页的物理地址,一个指向下一个数据页的物理地址。
每个数据页内部的User Records行记录部分会存储一行一行的数据,这些行数据会按照逐渐的大小进行排序存储,每一行数据都有一个指针指向下一行数据的位置,组成单向链表。
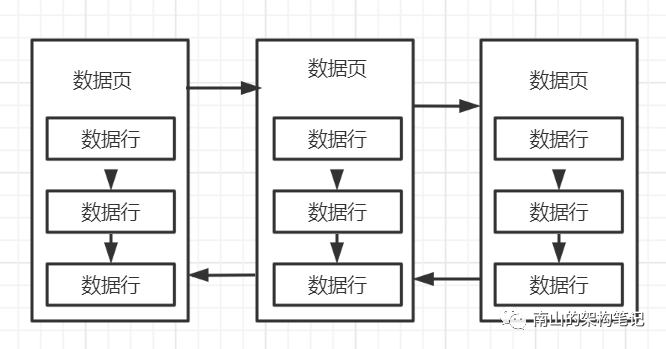
图3 数据页在磁盘文件里的物理存储结构
数据页的页目录是个重要的东西,目录的作用就是方便检索。这里的目录,同样有这样的作用。
页目录里有很多个槽位(slots),这个槽位对应一组数据,可以理解为真实数据与页面中第0个字节之间的偏移量。每个槽中,存放着每个组里最大的那条记录所在页面中的地址偏移量。
页目录就存放的是主键与槽位的映射关系,如图:
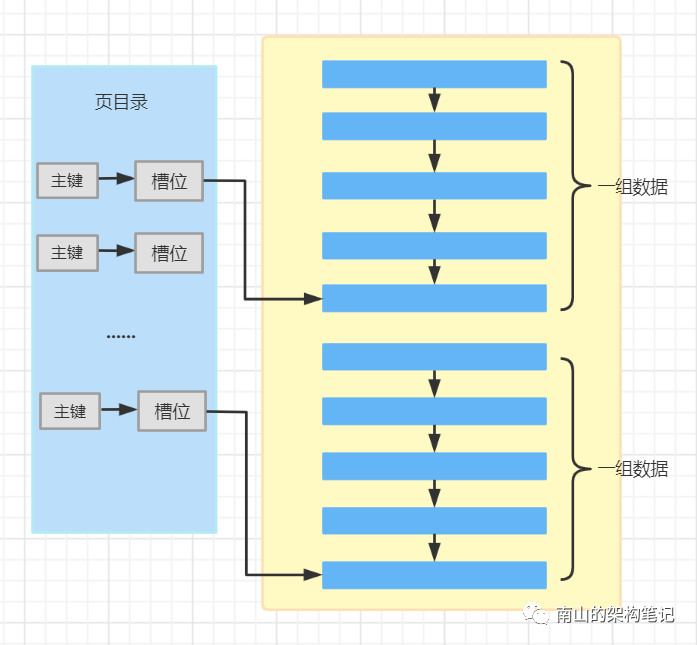
图4 页目录
所以说,如果你要根据主键查找一条数据,假设你表里没几条数据,那个表就一个数据页,那就直接在数据页里根据主键二分查找。
通过二分查找在目录里迅速定位到逐渐对应的数据在哪个槽位里,然后到那个槽位里去,遍历槽位里的每一行数据,就能找到那个主键对应的数据了。
如果你没办法使用主键查询,只能进到数据页里,逐条数据遍历查找了。
如果数据页里有很多的数据页,该如何查找呢?
假设你没有建立任何索引,只能从第一个数据页开始遍历所有的数据页,从第一个数据页开始,把每个数据也从磁盘加载到buffer pool的缓存页里去。
如果你是根据主键查找,你可以在数据页的页目录里二分查找,如果是根据其他字段查找,就需要在数据页里顺着单链表遍历了。
这个过程,其实就是全表扫描!
你在没有任何所以的时候,查找数据就是一个全表扫描的过程,就是根据双向链表把磁盘上的数据页加载到磁盘的缓存页里去,然后在缓存页内部查找那条数据。
这个过程是非常满的,所以说当数据量大的时候,全表扫描性能非常低,应该尽量避免全表扫描。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️