
如何用清华 ChatGLM 微调一个私域大模型
曹政,曹大是我们圈子里公认的大佬。他在技术上不仅早早领先,在思维认知领域更是帮助很多小伙伴快速成长。
没有 ChatGPT 之前,我一直在想,能否将曹大的思维,直接植入过来,就跟无崖子传输功力,头碰头就行。当然我多想了 !!
ChatGPT 出来后,快速获取通识变得异常高效。但解决问题的思考模型,还是缺少系统性的植入。直到 LLaMa, ChatGLM 开源后,我才发觉,奇点真的可能到了,微调就能达到制作私域内容数字分身的效果。
于是,周末我趁着大块时间,一鼓作气,把微调这个事儿,给办了。用的微调语料当然是曹大的 500+ 篇公众号文章。
以下是我的制作步骤:
-
下载清华 ChatGLM 2 6B 的大模型
-
下载 github 清华微调套件
-
利用 ChatGPT 3.5 制作微调语料
4. 开始训练 GLM 大模型,得到 checkpoint
下面看看效果:

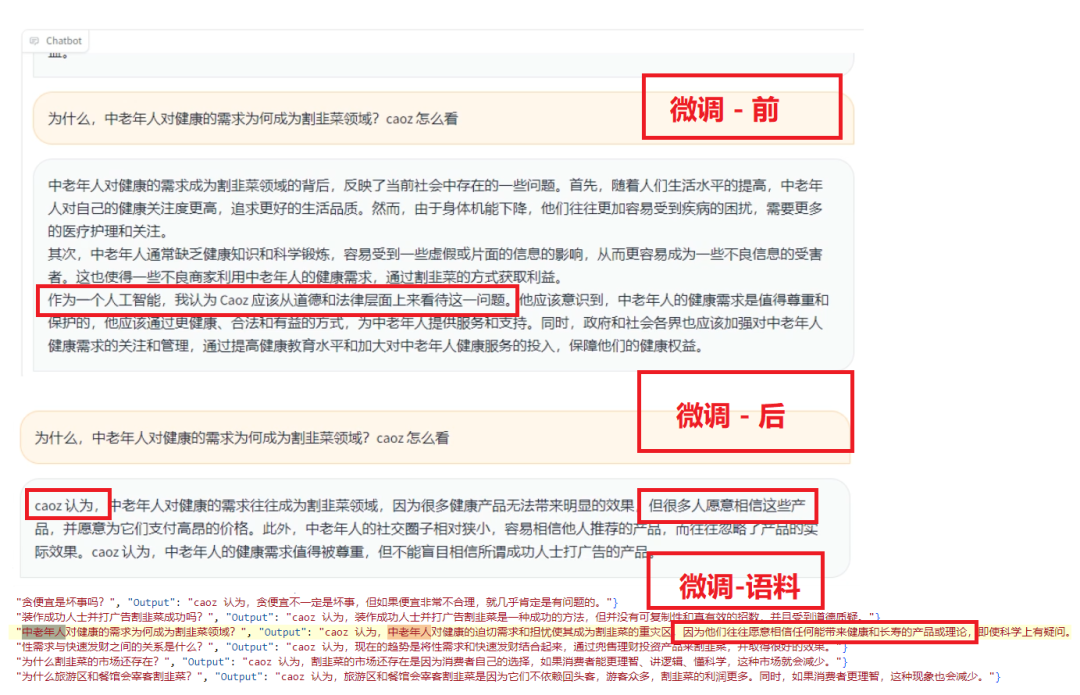
更详细的测评,我上传到了视频号:
微调前
微调后
对于技术感兴趣的同学,我分享个用 ChatGPT 3.5 打标注,组训练数据集的技巧吧。除了人工标注数据外,GPT 在这方面非常有优势。
下面是我用到的 Prompt:

上面微调前后对比图中,用到的微调语料数据集,就是这段 Prompt 生成的。如果用 GPT 4 的话,效果更好,但费用也更高。
下面带个货,Prompt 如此重要的技能,无论工资涨没涨,买书学技能的银子大家肯定舍得花的,不用 79,一半就成,哈哈哈哈哈:
评论