
ChatGLM 金融大模型决赛方案总结
作者:王小虎
原文转载:https://zhuanlan.zhihu.com/p/658373406

Q: 广新控股集团子公司名称是什么?
ChatGLM: 那要不住哥哥家里吧~
1. 比赛简介
比赛链接:
SMP 2023 ChatGLM金融大模型挑战赛_算法大赛_赛题与数据_天池大赛 https://tianchi.aliyun.com/competition/entrance/532126/information
要求以ChatGLM2-6B模型为中心制作一个问答系统,从约4000家上市公司三年的年报pdf内抽取关键信息回答一些问题。问题举例:
Q: 2019年中国工商银行财务费用是多少元?
A: 2019年中国工商银行财务费用是12345678.9元。
具体来说,问题的类型有
初级:数据基本查询(40分)
参赛者需要利用提供的ChatGLM2-6B开源模型和上市公司年报原始数据,并以此为基础创建信息问答系统。系统需能够解决基本查询,
某公司2021年的研发费用是多少?
这类问题可以直接从pdf抽取得到
中级:数据统计分析查询(30分)
在初级阶段的基础上,参赛者需要进行金融数据的统计分析和关联指标查询。系统需基于各类指标,提供问题和答案,
某公司2021年研发费用增长率为多少?
这类问题的解决是多步骤的,例如抽取两年的研发费用,再做一个除法
高级:开放性问题(30分)
某公司2021年主要研发项目是否涉及国家创新领域,如新能源技术、人工智能等?
这类问题比较依赖大模型的泛化能力
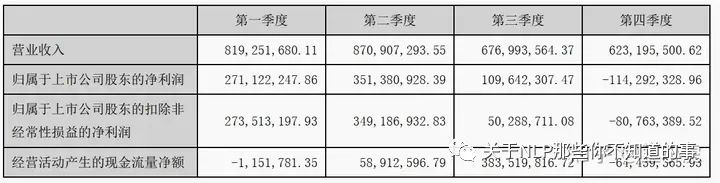
年报原文主要分为正文和表格两部分,举例:

2. 决赛方案概览
所有选手的技术方案都可以分为三个阶段:

一个具体的流程图:

2.1 问题分类
不同的问题的解决方式是不同的,因此需要先进行问题分类。需要根据答案抽取步骤的种类来确定类别


2.2 答案抽取
对于不同的问题有不同的答案抽取方法。
数据查询问题,大部分选手都使用了SQL查表的方式。
针对某公司的开放性问题,采用文档查询结合Prompt工程的方式来解决。
开放性问题大多数财务专有名词的解释,通常使用LLM直接回答
具体方法在下一节介绍
2.3 答案生成
这一步是将步骤2得到的结构化数据用模板输出。模板数量较多,有手工编写,规则生成,ChatGPT编写等方式。
还有一些后处理操作,例如如果大模型的回答是"我不知道",可以直接retry生成另一个答案,因为LLM的生成具有随机性,这样做可以解决很多问题。
一个具体的数值问题回答过程的例子:

3. 方案详解
3.1 问题分类(意图识别)
这一部分的解决方案也是Model-based和Rule-based相结合的,在分类的同时,也会提取一些关键词供后续处理
3.1.1 文本分类模型
Model-base方面,大部分选手利用了ChatGLM-6B作为一个文本分类器使用。模型使用Lora或P-tuning方式微调成为一个文本分类模型,分类数据集的来源于少量的手动label以及大量的rule做label(和rule-based方法相似)

3.1.2 关键词提取与匹配
rule-base方法,主要是关键词提取和匹配。这一步非常重要,也是决定比赛成绩的关键。
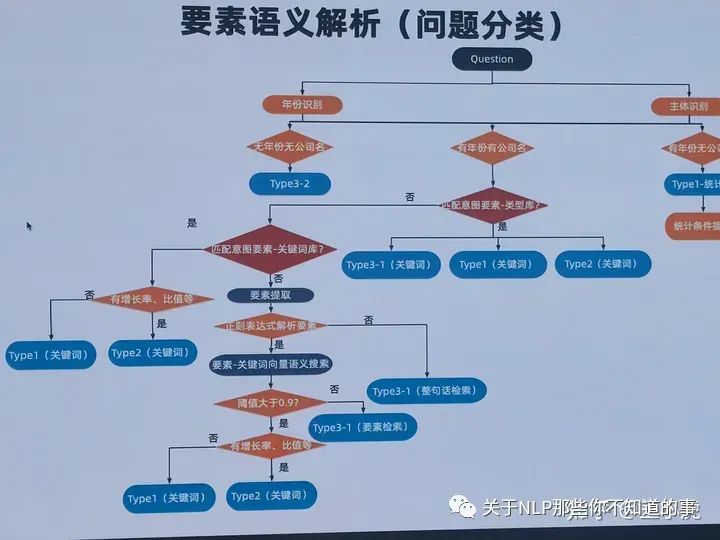
首先需要维护一个关键词库,主要包含问题类型关键词(保留2位小数),年份,公司名称,专有名词(总资产、资产增长率,硕士员工人数)等。

3.1.2.1 关键词词库提取
关键词词库的提取有BM25和ChatGLM模型抽取两种方法,模型抽取需要写一个Prompt
BM25
BM25是一种统计方法,是TF-IDF算法的变体。
在文本分词后,统计一个词在一篇文章(段落也可)的出现次数和全部文章的出现次数,如果一个词在单文章中出现比较多而在全部文章中出现比较少(如公司名字), 则它很有可能是关键词。
算法详见
BM25 相对 TF-IDF 有哪些优势? https://www.zhihu.com/question/349357370
3.1.2.2 关键词匹配
关键词匹配的难点在于年报中同一名词说法的多样性,如硕士员工人数在年报中可能会以下列形式出现
硕士人数XX人
硕士研究生人数XX人
硕士学历以上XX人
XX人获得硕士以上学历
解决此类问题,有关键词拓展和向量化匹配两种方法
关键词拓展
可以直接使用关键词在语料中搜索,发现一些词组经常成对出现,如"硕士"和"学历"经常伴随出现,因此"硕士"可拓展一个关键词是"硕士学历",可以用规则实现,也可以使用基于概率的算法,具体的计算方法可以参见
新词发现的信息熵方法与实现 - 科学空间|Scientific Spaces https://spaces.ac.cn/archives/3491
关键词向量化匹配
除了直接使用正则匹配外,许多选手使用了词向量计算词的语义相似度,例如"北京大学"和"北大"语义相似度很高,可以视为同一个关键词。
3.2 答案要素提取
答案的数据来源分为年报表格和年报正文两部分。年报表格都是数值类问题
3.2.1 数值类
数据库构建
年报表格,先将表格解析后存入关系型数据库,是纯纯的dirty work
数据库query
很多选手用了NL2SQL(Natural Language To SQL)任务来生成SQL语句查询。
NL2SQL模型也是一个基于ChatGLM-6B微调得到的模型。选手们使用了开源的DuSQL/NL2SQL/Cspider,以及ChatGPT生成一些NL2SQL数据集,还可以写一些rule生成。然后对ChatGLM做P-Tuning。

关于NL2SQL的prompt优化,要尽量提高prompt的信噪比,去掉信息熵较低的词语,如stopword(的地得、请)、“保留小数”
容易查询错误的关键词,如公司名词,可以在prompt中着重强调
一些复杂的查询,如两年的增长率,可以分为两个问题,分别查询两年的数值,然后使用python函数计算增长率,使得NL2SQL的prompt尽量简单明确。

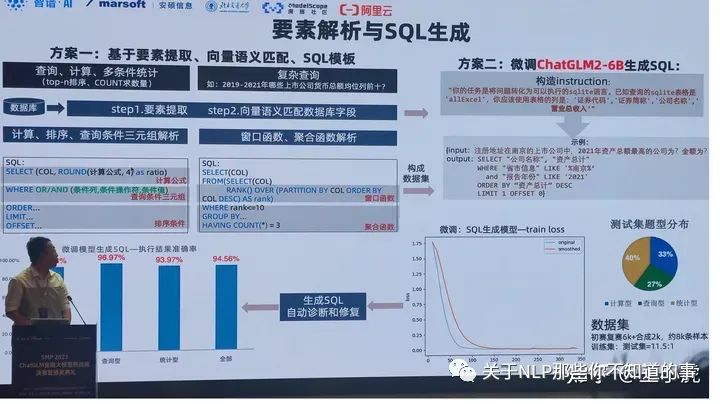
这一步本质是使用Tool,可以使用Tools learning方法让模型学会SQL查询,选手没有详细介绍。
NL2SQL也可以使用Rule-based方法,这里不赘述。
3.2.2 文本类
大模型可以读完一段文本后回答各种问题。对于年报正文相关的问题,为了降低大模型抽取信息的难度,首先要search得到问题最相关的年报具体句子或段落,提高信噪比。可以直接用向量查询,也可以在文档树上做树的查询。
句子匹配
关键词匹配:由于问题和答案关键词重合度很高,可以使用BM25直接计算句子的相似性,而流行的SentenceBert方法未微调情况下不如BM25
句子向量化匹配:可以使用m3e-base预训练模型或SentenceBert等Text2vec模型
使用向量数据库存储句子以及句子向量,可以加速句向量匹配。关于向量数据库的选取,选手们用faiss比较多
文档树查询
标题和问题的相关性很高。使用各级标题信息,将PDF解析为一颗DocTree,用章节标题和问题做向量化匹配,自顶向下做树的搜索,找到对应的正文。

文本类信息抽取
这一步用模型直接生成即可,需要设计一个Prompt,也需要做些微调

3.3 答案生成
为了获得较高的分数,需要将查询结果按照指定格式输出,例如SQL的格式化查询结果转换为一个自然语言句子,通常使用模板填充实现。模板由手工制作。

也可以使用In-context learning方法利用ChatGLM来生成答案,具体的是给财务分析类问题,每一种问题标注1~2个答案以及提供对应的Json(格式化数据),让模型学会答案生成。
4. 感想
6B模型无法做到端到端的任务能力。6B模型能力有限,无法实现pdf输入->prompt->答案这一简单架构。因此选手们微调了各种sub-model来做各种sub-task,在前大模型时代,NLP系统也是使用各种Bert变种来完成各种任务的。如果能使用更大的模型,也许解决方案也会有变化。
大模型时代数据质量依然尤其重要。从选手介绍技术方案的篇幅可以感觉到,比赛最重要的部分是提高数据质量,主要体现在模型训练时,对关键词的提取/拓展/纠错等部分。Prompt也需要精心构造,提高信噪比。
ChatGLM: 那要不住哥哥家里吧~