
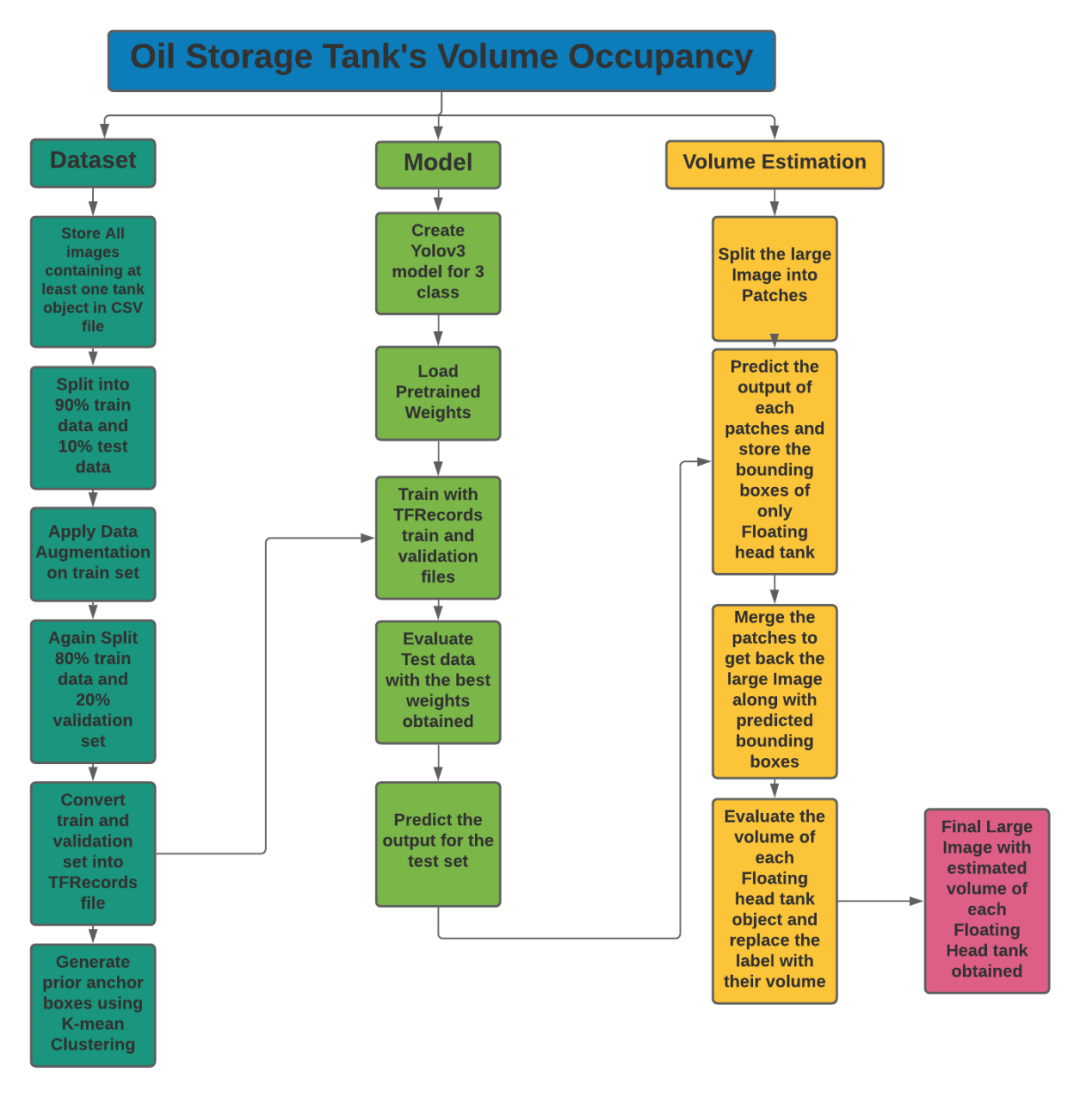
基于Yolo-V3对卫星图像进行储油罐容积占用率的研究
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源:深度学习与计算机视觉



本文的所有内容和整个代码都可以在这个github存储库中找到 https://github.com/mdmub0587/Oil-Storage-Tank-s-Volume-Occupancy
目录
问题陈述、数据集和评估指标
现有方法
相关研究工作
有用的博客和研究论文
我们的贡献
探索性数据分析(EDA)
数据扩充
数据预处理、扩充和TFRecords
基于YoloV3的目标检测
储量估算
结果
结论
参考引用
1.问题陈述、数据集和评估指标
问题陈述:
数据集:
large_images: 这是一个文件夹,包含100个卫星原始图像,每个大小为4800x4800,所有图像都以id_large.jpg格式命名。 Image_patches: Image_patches目录包含从大图像生成的512x512大小的子图,每个大的图像被分割成100个512x512大小的子图,两个轴上的子图之间有37个像素的重叠,生成图像子图的程序以id_row_column.jpg格式命名 **labels.json:**它包含所有图像的标签。标签存储为字典列表,每个图像对应一个字典,不包含任何浮顶罐的图像将被标记为“skip”,边界框标签的格式为边界框四个角的(x,y)坐标。 labels_coco.json: 它包含与前一个文件相同的标签的COCO标签格式。在这里,边界框的格式为[x_min, y_min, width, height]. **large_image_data.csv:**它包含大型图像文件的元数据,包括每个图像的中心坐标和海拔高度。
评估指标:
2.现有方法
3.相关研究工作
Estimating the Volume of Oil Tanks Based on High-Resolution Remote Sensing Images [2]:
4.有用的博客和研究论文
A Beginner’s Guide To Calculating Oil Storage Tank Occupancy With Help Of Satellite Imagery [3]:
A Gentle Introduction to Object Recognition With Deep Learning [4] :
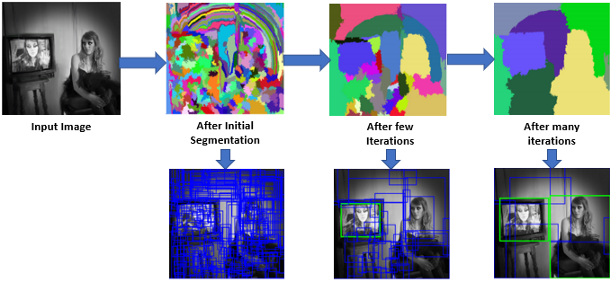
Selective Search for Object Recognition [5]:
Region Proposal Network — A detailed view[6]:
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[7]:

Real-time Object Detection with YOLO, YOLOv2, and now YOLOv3 [8]:
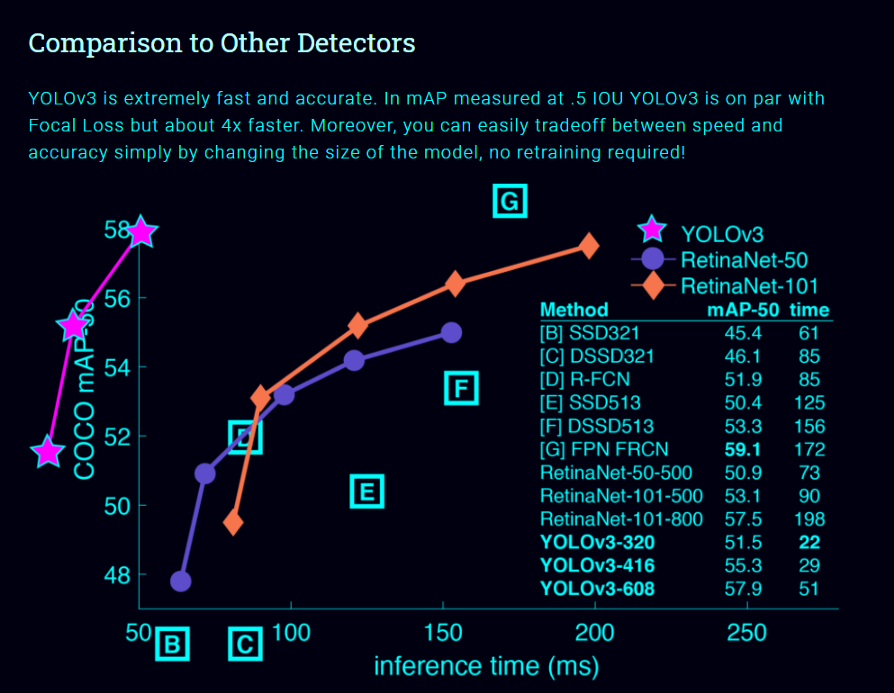
单神经网络模型(即分类和定位任务都将从同一个模型中执行):以一张照片作为输入,直接预测每个边界框的边界框和类标签,这意味着它只看一次图像。 由于它对整个图像而不是图像的一部分执行卷积,因此它产生的背景错误非常少。 YOLO学习对象的一般化表示。在对自然图像进行训练和艺术品测试时,YOLO的性能远远超过DPM和R-CNN等顶级检测方法。由于YOLO具有高度的通用性,所以当应用于新的域或意外的输入时,它不太可能崩溃。
如果你仔细看一下yolov2论文的标题,那就是“YOLO9000: Better, Faster, Stronger”。yolov3比yolov2更好吗?答案是肯定的,它更好,但不是更快更强,因为体系的复杂性增加了。 Yolov2使用了19层DarkNet架构,没有任何残差块、skip连接和上采样,因此它很难检测到小对象,然而在Yolov3中,这些特性被添加了,并且使用了在Imagenet上训练的53层DarkNet网络,除此之外,还堆积了53个卷积层,形成了106个卷积层结构。
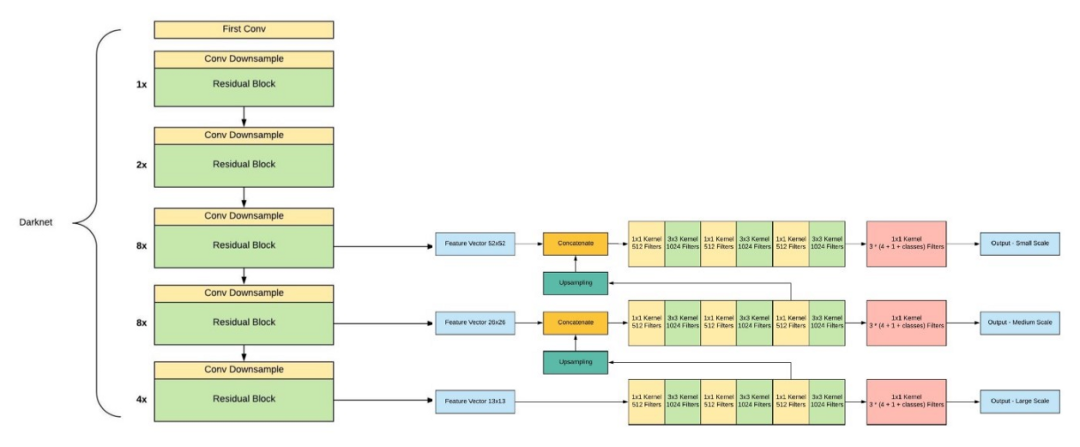
Yolov3在三种不同的尺度上进行预测,首先是大对象的13X13网格,其次是中等对象的26X26网格,最后是小对象的52X52网格。 YoloV3总共使用9个锚箱,每个标度3个,用K均值聚类法选出最佳锚盒。 Yolov3可以对图像中检测到的对象执行多标签分类,通过logistic回归预测对象置信度和类预测。
5.我们的贡献
储罐检测:
阴影提取和体积估计:
6.探索性数据分析(EDA)
探索Labels.json文件:
json_labels = json.load(open(os.path.join('data','labels.json')))
print('Number of Images: ',len(json_labels))
json_labels[25:30]
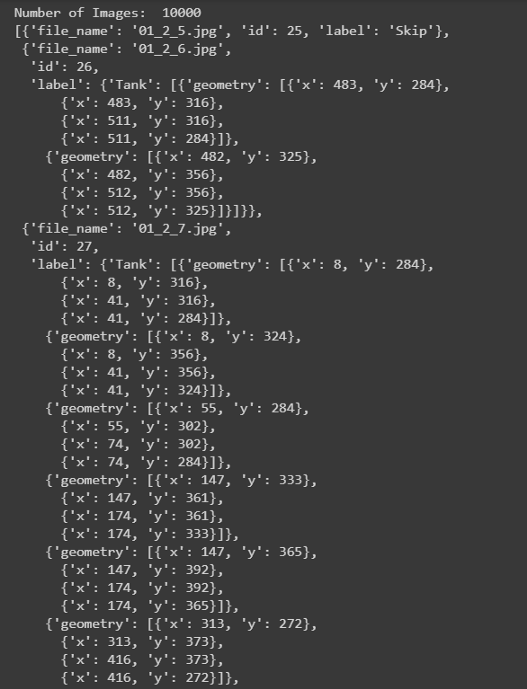
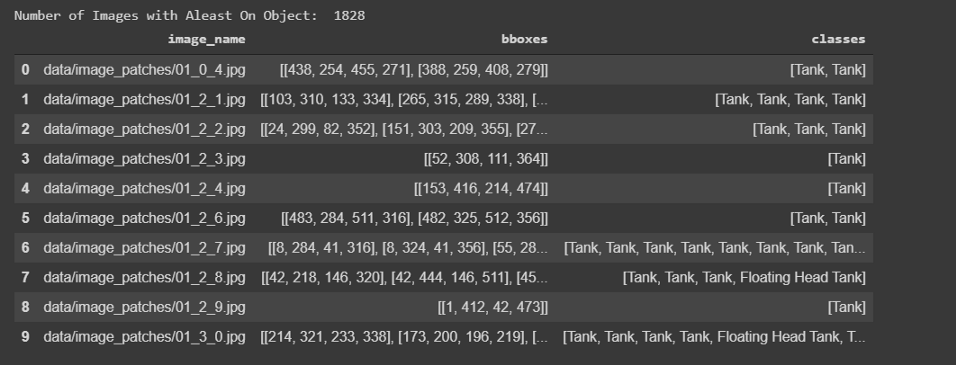
所有的标签都存储在字典列表中,总共有10万张图片。不包含任何储罐的图像将标记为Skip,而包含储罐的图像将标记为tank、tank Cluster或Floating Head tank,每个tank对象都有字典格式的四个角点的边界框坐标。
计数:
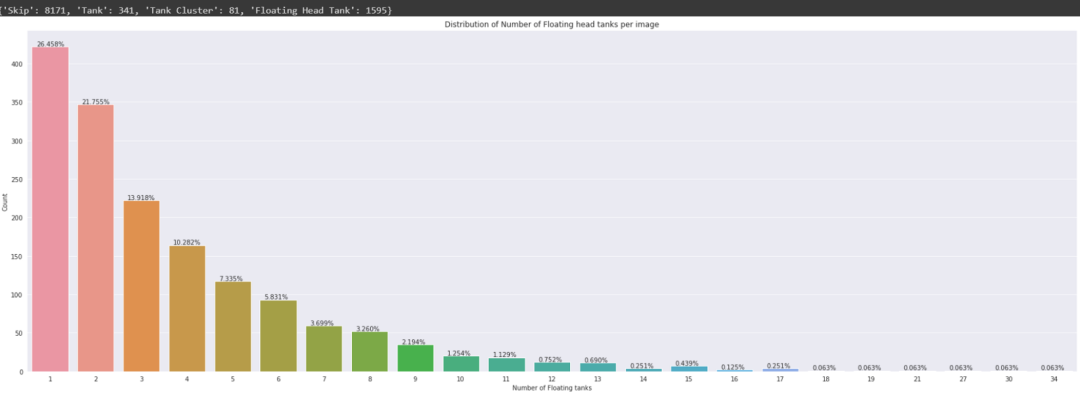
探索labels_coco.json文件:
json_labels_coco = json.load(open(os.path.join('data','labels_coco.json')))
print('Number of Floating tanks: ',len(json_labels_coco['annotations']))
no_unique_img_id = set()
for ann in json_labels_coco['annotations']:
no_unique_img_id.add(ann['image_id'])
print('Number of Images that contains Floating head tank: ', len(no_unique_img_id))
json_labels_coco['annotations'][:8]
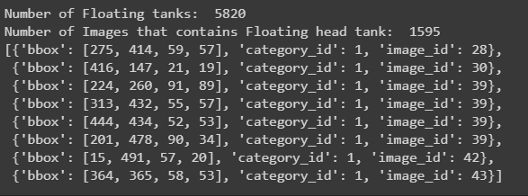
此文件仅包含浮顶罐的边界框及其在字典格式列表中的image_id
打印边界框:

储油罐有三种:
Tank(T 油罐) Tank Cluster(TC 油罐组), Floating Head Tank(FHT,浮顶罐)
7.数据扩充
8.数据预处理、扩充和TFRecords
数据预处理:
def conv_bbox(box_dict):
"""
input: box_dict-> 字典中有4个角点
Function: 获取左上方和右下方的点
output: tuple(ymin, xmin, ymax, xmax)
"""
xs = np.array(list(set([i['x'] for i in box_dict])))
ys = np.array(list(set([i['y'] for i in box_dict])))
x_min = xs.min()
x_max = xs.max()
y_min = ys.min()
y_max = ys.max()
return y_min, x_min, y_max, x_max
# 训练和测试划分
df_train, df_test= model_selection.train_test_split(
df, #CSV文件注释
test_size=0.1,
random_state=42,
shuffle=True,
)
df_train.shape, df_test.shape
数据扩充:
水平翻转 旋转90度 旋转180度 旋转270度 水平翻转和90度旋转 水平翻转和180度旋转 水平翻转和270度旋转

TFRecords:
9.基于YoloV3的目标检测
训练:
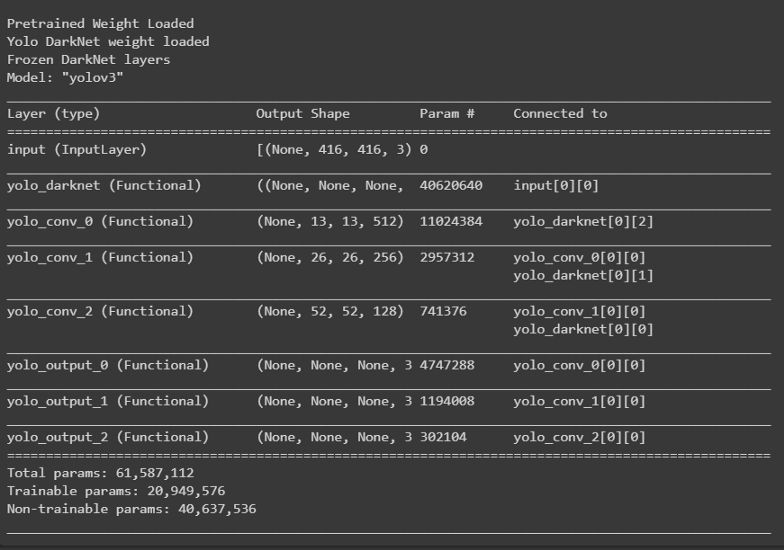
def create_model():
tf.keras.backend.clear_session()
pret_model = YoloV3(size, channels, classes=80)
load_darknet_weights(pret_model, 'Pretrained_Model/yolov3.weights')
print('\nPretrained Weight Loaded')
model = YoloV3(size, channels, classes=3)
model.get_layer('yolo_darknet').set_weights(
pret_model.get_layer('yolo_darknet').get_weights())
print('Yolo DarkNet weight loaded')
freeze_all(model.get_layer('yolo_darknet'))
print('Frozen DarkNet layers')
return model
model = create_model()
model.summary()
tf.keras.backend.clear_session()
epochs = 100
learning_rate=1e-3
optimizer = get_optimizer(
optim_type = 'adam',
learning_rate=1e-3,
decay_type='cosine',
decay_steps=10*600
)
loss = [YoloLoss(yolo_anchors[mask], classes=3) for mask in yolo_anchor_masks]
model = create_model()
model.compile(optimizer=optimizer, loss=loss)
# Tensorbaord
! rm -rf ./logs/
logdir = os.path.join("logs", datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
%tensorboard --logdir $logdir
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
callbacks = [
EarlyStopping(monitor='val_loss', min_delta=0, patience=15, verbose=1),
ModelCheckpoint('Weights/Best_weight.hdf5', verbose=1, save_best_only=True),
tensorboard_callback,
]
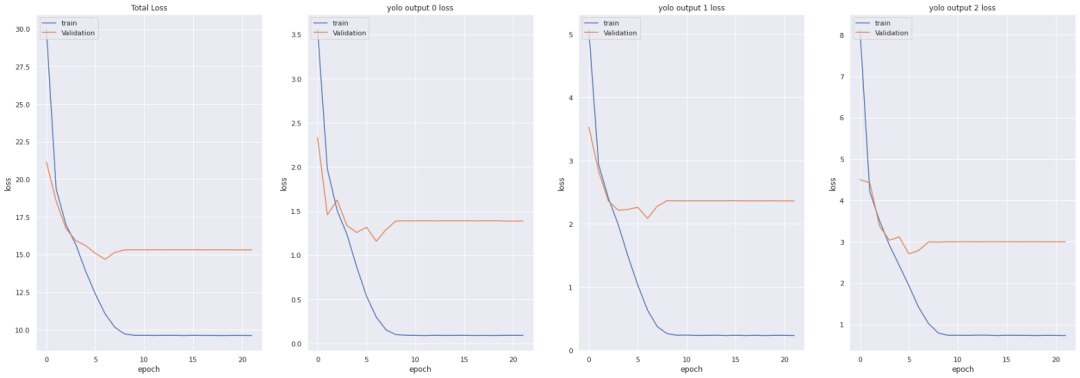
history = model.fit(train_dataset,
epochs=epochs,
callbacks=callbacks,
validation_data=valid_dataset)
model.save('Weights/Last_weight.hdf5')
YOLO损失函数:
中心(x,y) 的MSE损失. 边界框的宽度和高度的均方误差(MSE) 边界框的二元交叉熵得分与无目标得分 边界框多类预测的二元交叉熵或稀疏范畴交叉熵
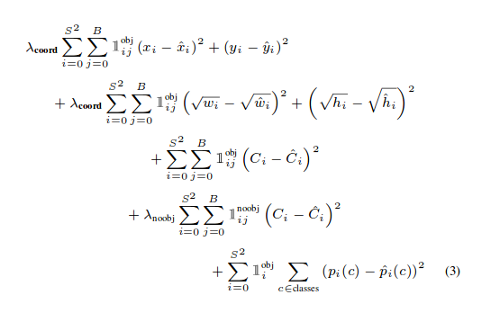
def YoloLoss(anchors, classes=3, ignore_thresh=0.5):
def yolo_loss(y_true, y_pred):
# 1. 转换所有预测输出
# y_pred: (batch_size, grid, grid, anchors, (x, y, w, h, obj, ...cls))
pred_box, pred_obj, pred_class, pred_xywh = yolo_boxes(
y_pred, anchors, classes)
# predicted (tx, ty, tw, th)
pred_xy = pred_xywh[..., 0:2] #x,y of last channel
pred_wh = pred_xywh[..., 2:4] #w,h of last channel
# 2. 转换所有真实输出
# y_true: (batch_size, grid, grid, anchors, (x1, y1, x2, y2, obj, cls))
true_box, true_obj, true_class_idx = tf.split(
y_true, (4, 1, 1), axis=-1)
#转换 x1, y1, x2, y2 to x, y, w, h
# x,y = (x2 - x1)/2, (y2-y1)/2
# w, h = (x2- x1), (y2 - y1)
true_xy = (true_box[..., 0:2] + true_box[..., 2:4]) / 2
true_wh = true_box[..., 2:4] - true_box[..., 0:2]
# 小的box要更高权重
#shape-> (batch_size, grid, grid, anchors)
box_loss_scale = 2 - true_wh[..., 0] * true_wh[..., 1]
# 3. 对pred box进行反向
# 把 (bx, by, bw, bh) 变为 (tx, ty, tw, th)
grid_size = tf.shape(y_true)[1]
grid = tf.meshgrid(tf.range(grid_size), tf.range(grid_size))
grid = tf.expand_dims(tf.stack(grid, axis=-1), axis=2)
true_xy = true_xy * tf.cast(grid_size, tf.float32) - tf.cast(grid, tf.float32)
true_wh = tf.math.log(true_wh / anchors)
true_wh = tf.where(tf.logical_or(tf.math.is_inf(true_wh),
tf.math.is_nan(true_wh)),
tf.zeros_like(true_wh), true_wh)
# 4. 计算所有掩码
#从张量的形状中去除尺寸为1的维度。
#obj_mask: (batch_size, grid, grid, anchors)
obj_mask = tf.squeeze(true_obj, -1)
#当iou超过临界值时,忽略假正例
#best_iou: (batch_size, grid, grid, anchors)
best_iou = tf.map_fn(
lambda x: tf.reduce_max(broadcast_iou(x[0], tf.boolean_mask(
x[1], tf.cast(x[2], tf.bool))), axis=-1),
(pred_box, true_box, obj_mask),
tf.float32)
ignore_mask = tf.cast(best_iou < ignore_thresh, tf.float32)
# 5.计算所有损失
xy_loss = obj_mask * box_loss_scale * \
tf.reduce_sum(tf.square(true_xy - pred_xy), axis=-1)
wh_loss = obj_mask * box_loss_scale * \
tf.reduce_sum(tf.square(true_wh - pred_wh), axis=-1)
obj_loss = binary_crossentropy(true_obj, pred_obj)
obj_loss = obj_mask * obj_loss + \
(1 - obj_mask) * ignore_mask * obj_loss
#TODO:使用binary_crossentropy代替
class_loss = obj_mask * sparse_categorical_crossentropy(
true_class_idx, pred_class)
# 6. 在(batch, gridx, gridy, anchors)求和得到 => (batch, 1)
xy_loss = tf.reduce_sum(xy_loss, axis=(1, 2, 3))
wh_loss = tf.reduce_sum(wh_loss, axis=(1, 2, 3))
obj_loss = tf.reduce_sum(obj_loss, axis=(1, 2, 3))
class_loss = tf.reduce_sum(class_loss, axis=(1, 2, 3))
return xy_loss + wh_loss + obj_loss + class_loss
return yolo_loss
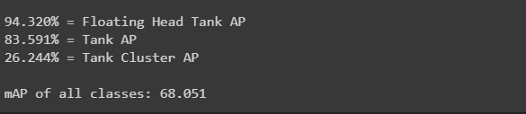
get_mAP(model, 'data/test.csv')

get_mAP(model, 'data/train.csv')
10.储量估算

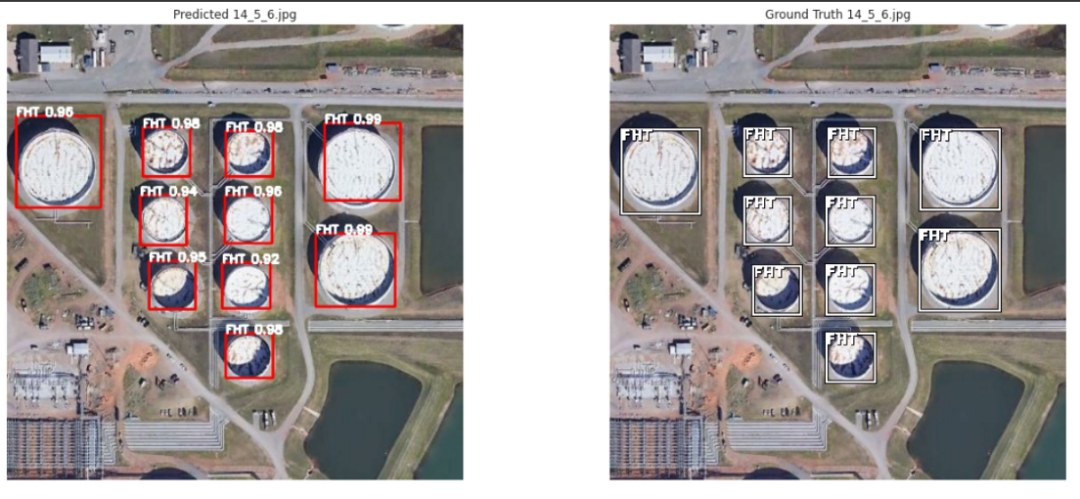
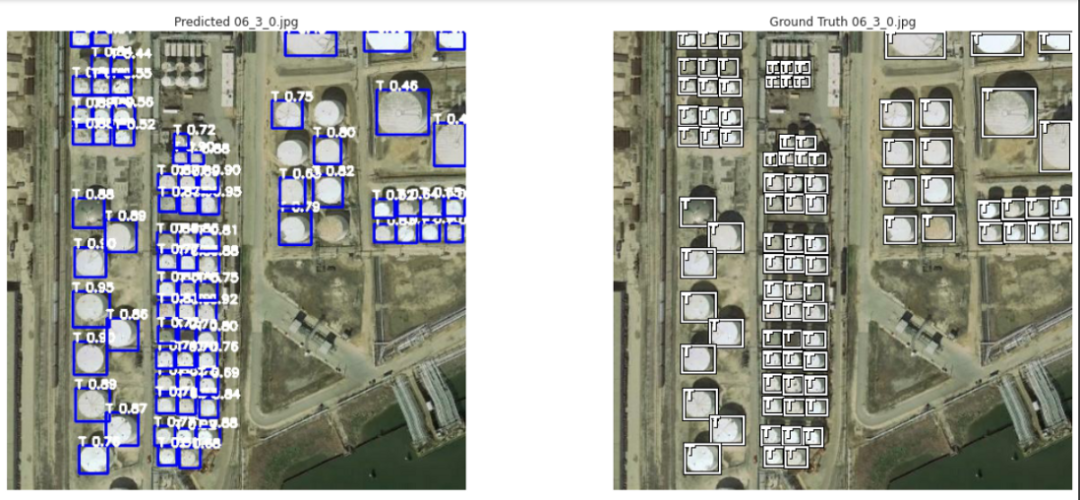
11.结果
12.结论
只需有限的图像就可以得到相当好的结果。 数据增强工作得很到位。 在本例中,与RetinaNet模型的现有方法相比,yolov3表现得很好。

下载1:OpenCV黑魔法
在「AI算法与图像处理」公众号后台回复:OpenCV黑魔法,即可下载小编精心编写整理的计算机视觉趣味实战教程
下载2 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

觉得有趣就点亮在看吧

评论