
基于U-Net检测卫星图像上的新增建筑

向AI转型的程序员都关注了这个号???
机器学习AI算法工程 公众号:datayx
在国土监察业务中,很重要的一项工作是监管地上建筑物的建、拆、改、扩。如果地块未经审批而存在建筑物,那么需要实地派人去调查是否出现了非法占地行为。如果地块卖给了开发商但是没有实际建设,那么需要调查是否捂地或者是开发商资金链出现问题。如果居民住房/商业用地异常扩大,那么需要调查是否存在违章建筑。对于大城市及其郊区来说,不可能靠国土局公务员来每天全城巡查,而可以靠高分辨率图像和智能算法来自动完成这项任务。具体来说,需要靠高分系列卫星图像(米级分辨率),和深度学习算法来革新现有的工作流程。
本次任务覆盖广东省部分地区数百平方公里的土地,其数据共3个大文件,存储在OSS上,供所有参赛选手下载挖掘。
卫星数据以Tiff图像文件格式储存。quickbird2015.tif是一张2015年的卫星图片,quickbird2017.tif是一张2017年的卫星图片。每个Tiff文件中有4个波段的数据:蓝、绿、红、近红外。本次比赛的卫星数据为多景数据拼接而成,这是国土资源工作中常见的实际场景。比赛数据在蓝、绿两个波段有明显的拼接痕迹,而红、近红外波段的拼接痕迹不明显。建议选手挑选波段使用数据,或者在算法中设计应对方案。每个像元以16-bit存储。Quickbird卫星数据的详细描述可以参见:
https://www.satimagingcorp.com/satellite-sensors/quickbird/
2015年度的国土审批纪录也以Tiff图像文件格式储存,命名为Cadastral2015.tif。其中包含了国土审批数据中大约5%的地块,这些地块的位置在图像中数值定为1,其余地区的位置在图像中数值定为0。值得注意的是:政府在2015年度审批的国土建设地块并不一定在2017年完成了建设,同时选手获取的审批地块图片也仅是所有审批纪录中的一小部分。因此,本次大赛国土审批纪录不是一份训练数据,而只是一个线索。
在初赛第一阶段,我们将提供一份人工精确标注的小型数据集,便于所有选手上手,命名为tinysample.tif。但是,我们推荐选手对国土审批地块图片进行人工甄别,筛选建造自己的训练集。决赛最终使用的训练集可以来自本次大赛所覆盖的全部地区。
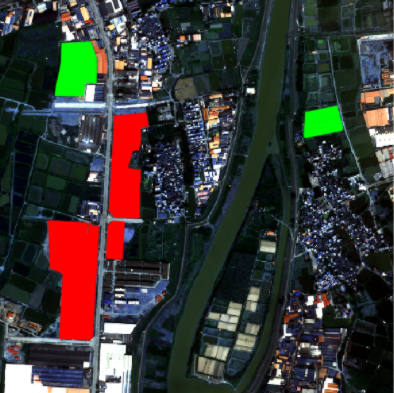
图1:卫星图片和国土审批记录叠加在一起
上图中红/绿色地块是2015年政府批复下来的不同土地开发项目。
Tiff数据可以用各种编程语言读写。比如在Python语言中可以使用PIL库(Pillow版本), 请参见https://python-pillow.org ;或者是GDAL库,请参见https://pcjericks.github.io/py-gdalogr-cookbook/ 。同时,推荐选手使用开源软件QGIS来观察/编辑卫星图片数据,请参见www.qgis.org 。
基于U-Net检测卫星图像上的新增建筑
代码及运行教程 获取:
关注微信公众号 datayx 然后回复 unet 即可获取。
AI项目体验地址 https://loveai.tech
数据准备
图像预处理
针对原始图像存在的两个问题:
原图像不同拼接区域颜色差异大
虽然原图像每个通道的数据都是16位的,但数据的实际范围是0~2774
给出如下图所示的解决方法:
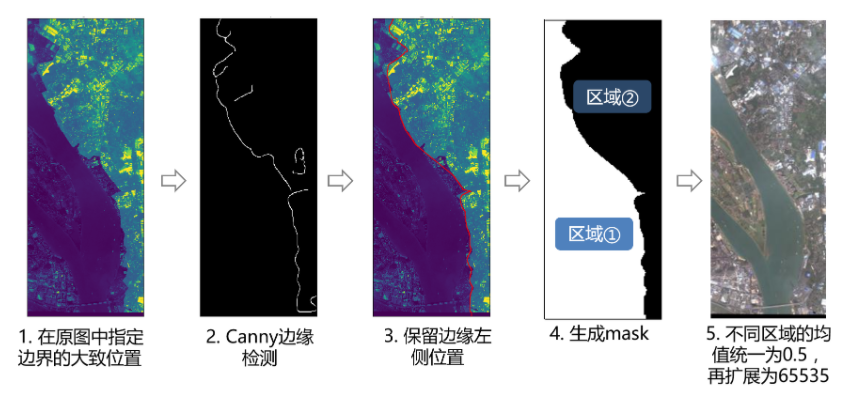
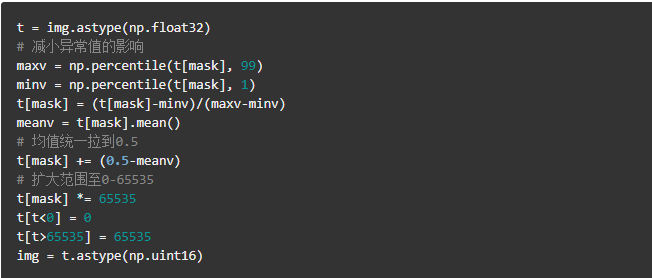
步骤1到步骤4的代码请参考genrate_mask.ipynb(需要人工交互操作),步骤5的代码请参考denoise.py,该操作的核心代码如下:
手工标注
如下图,标注训练数据时,我们只挑选一些有代表性的区域进行标注,保证在选择的区域内,标注的白色区域一定是房子变化,而黑色区域一定不是。得到所选区域的标签后,再分割成多个小图像组成我们数据集。

从手工标注的mask图像到训练用到的.npy文件,参考代码process_mark.py,该部分的核心代码如下:

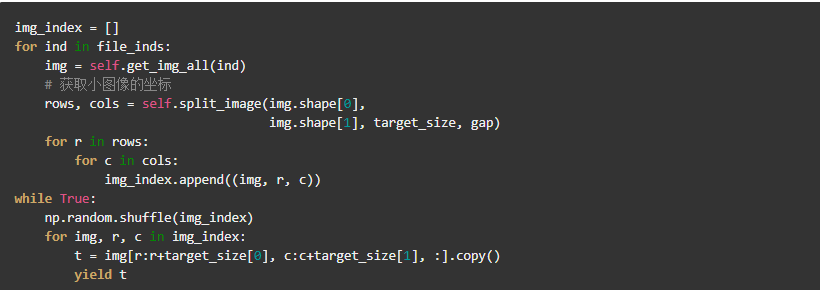
读取.npy文件以生成训练用到的小图,参考代码generators.py,该部分的核心代码如下:
数据增强
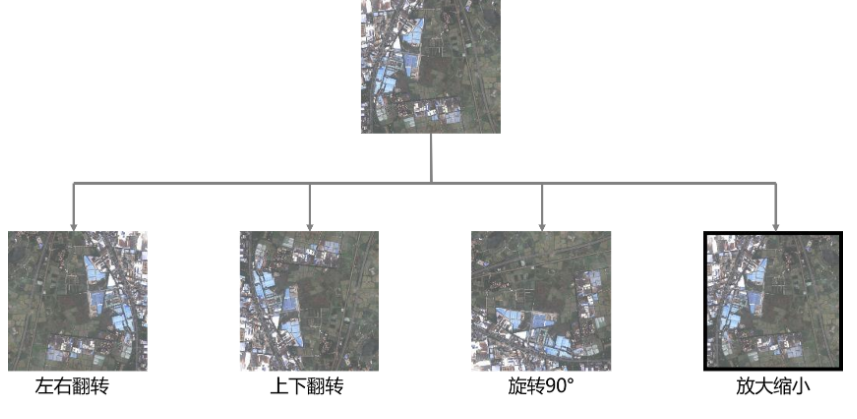
使用数据增强对提高模型的泛化能力很有帮助,目前我们只使用了上面四种增强方法,在imgaug.py里还有其他数据增强的实现代码。
数据集划分
训练集:70%
验证集:20%
测试集:10%
网络训练
改进U-Net
使用U-Net检测新增建筑的整体流程如下:
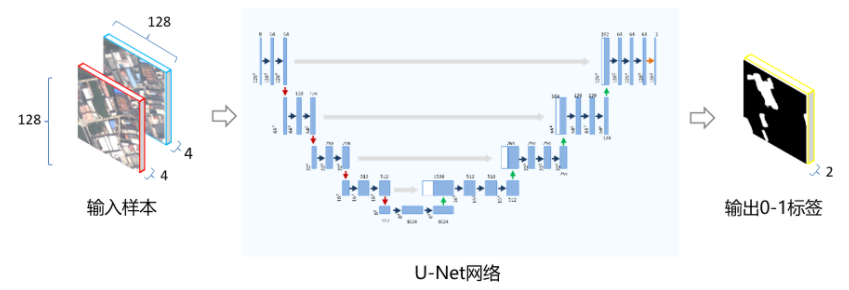
U-Net的整体架构如下:
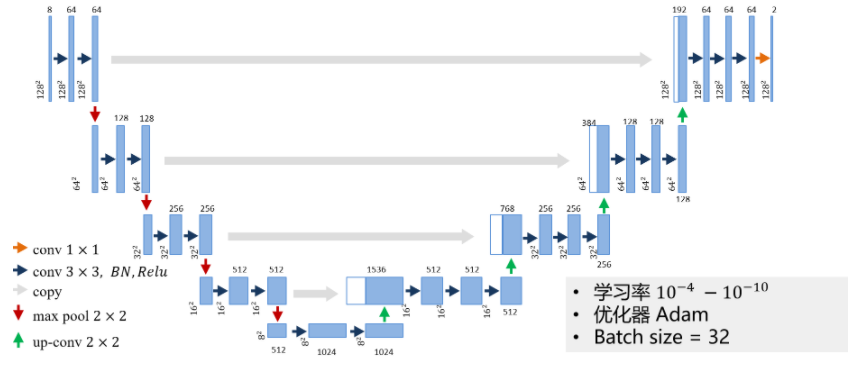
实现U-Net的代码请参考unet.py。
后处理
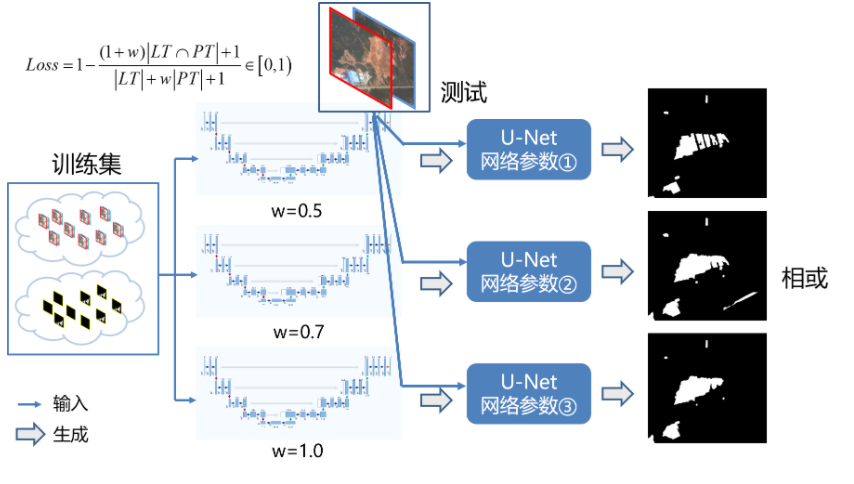
模型融合
将loss权重不同的模型得到的结果进行融合(像素级或操作),如下图所示:
Morphology处理
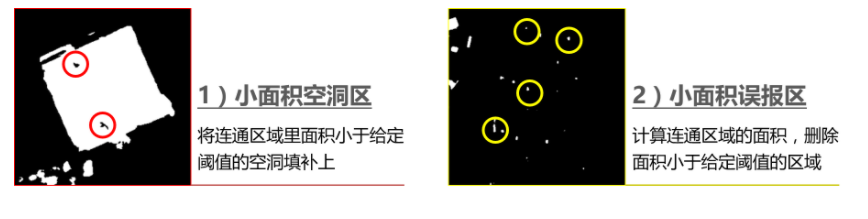
该部分的代码请参考post_process.py,其中核心代码如下:
总结
算法优势
预处理:解决图像拼接问题
八通道U-Net:直接输出房屋变化,可应对高层建筑倾斜问题
数据增强:增加模型泛化性,简单有效
加权损失函数:增强对新增建筑的检测能力
模型融合:取长补短,结果更全
后处理:直观、高效,可根据实际情况取舍
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码