
来自Facebook AI的多任务多模态的统一Transformer:向更通用的智能迈出了一步
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作者:Synced
编译:ronghuaiyang 来源 AI公园
一个模型完成了CV,NLP方向的7个任务,每个任务上表现都非常好。
论文链接:https://arxiv.org/pdf/2102.10772.pdf
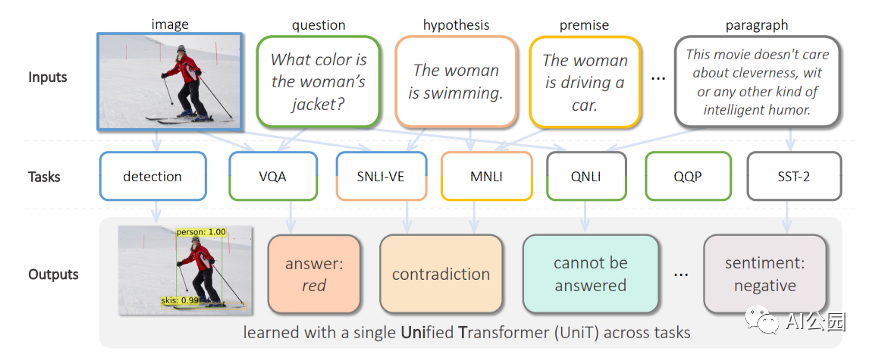
Transformer架构在自然语言处理和其他领域的机器学习(ML)任务中表现出了巨大的成功,但大多仅限于单个领域或特定的多模态领域的任务。例如,ViT专门用于视觉相关的任务,BERT专注于语言任务,而VILBERT-MT只用于相关的视觉和语言任务。
一个自然产生的问题是:我们能否建立一个单一的Transformer,能够在多种模态下处理不同领域的广泛应用?最近,Facebook的一个人工智能研究团队进行了一个新的统一Transformer(UniT) encoder-decoder模型的挑战,该模型在不同的模态下联合训练多个任务,并通过一组统一的模型参数在这些不同的任务上都实现了强大的性能。

Transformer首先应用于sequence-to-sequence模型的语言领域。它们已经扩展到视觉领域,甚至被应用于视觉和语言的联合推理任务。尽管可以针对各种下游任务中的应用对预先训练好的Transformer进行微调,并获得良好的结果,但这种模型微调方法会导致为每个下游任务创建不同的参数集。
Facebook的人工智能研究人员提出,一个Transformer可能就是我们真正需要的。他们的UniT是建立在传统的Transformer编码器-解码器架构上,包括每个输入模态类型的独立编码器,后面跟一个具有简单的每个任务特定的头的解码器。输入有两种形式:图像和文本。首先,卷积神经网络骨干网提取视觉特征,然后BERT将语言输入编码成隐藏状态序列。然后,Transformer解码器应用于编码的单个模态或两个编码模态的连接序列(取决于任务是单模态还是多模态)。最后,Transformer解码器的表示将被传递到特定任务的头,该头将输出最终的预测。
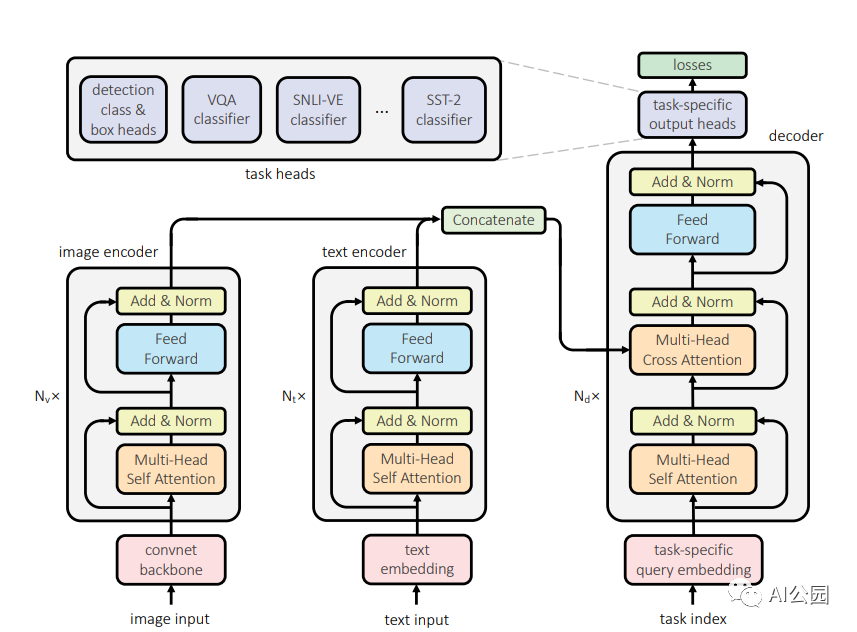
评估UniT的性能,研究人员进行了实验,需要共同学习来自不同领域的许多流行的任务:COCO目标检测和 Visual Genome数据集,语言理解任务的GLUE基准(QNLI, QQP、MNLI-mismatched SST-2),以及视觉推理任务VQAv2 SNLI-VE数据集。
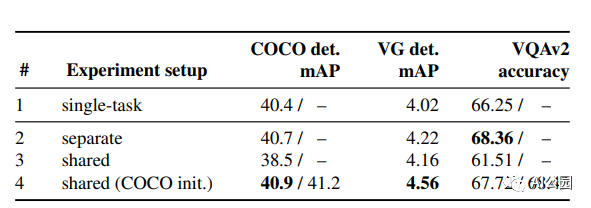
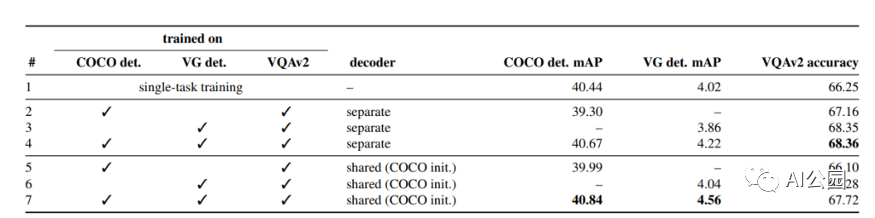
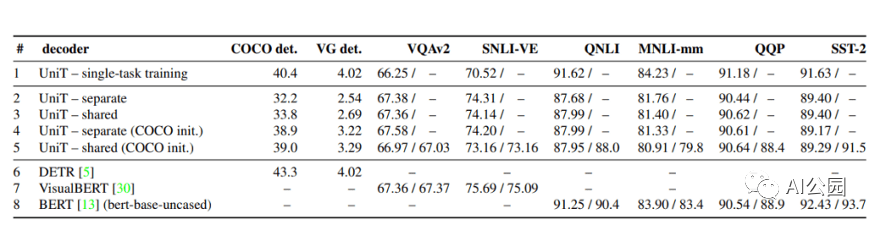

结果表明,所提出的UniT 模型同时处理8个数据集上的7个任务,在统一的模型参数集下,每个任务都有较强的性能。强大的性能表明UniT有潜力成为一种领域未知的transformer 架构,向更通用的智能的目标迈进了一步。

英文原文:https://medium.com/syncedreview/facebook-ais-multitask-multimodal-unified-transformer-a-step-toward-general-purpose-98db2c858603
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文
觉得不错就点亮在看吧
