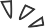国庆到了,再聊聊神舟十二号上的数字航天员

大数据文摘授权转载自游戏研究社
神舟十二号已经上天80多天,还有10天左右就要返回地球了。
相比起航时的万众瞩目,神舟十二号在太空的两个月里相当低调。一方面是航天员们忙于执行科研探索和空间站维护任务,没有太大精力出境;另一方面,8月以来国内诸多圈层的波澜起伏也分散了所有人的关注点。
昨天早上,聂海胜成为了首位在轨100天的中国航天员,社交媒体和新闻网站纷纷发文祝贺,让大家又一下子想起来:“在距离地球几百公里的高空,还有3个我们的人”。

执行三次任务,在轨100天的聂海胜
不过,“3个我们的人”也许并不准确——神舟十二号升空那天,还有0.5个人,也跟着飞船上了天,在地球上的人们暂时移开目光时,一直默默关注、记录着这次航天任务中的一切。

一位名叫“小诤”的新华社数字记者,与航天员们一起升空,进入了中国空间站,并从外太空向地球发回了报道。她是新华社的第一位数字记者,也是全球首位数字航天员。
在亮相的报道影像中,小诤向观众介绍了中国和国际空间站各个舱段的功能、布置陈设,还拍摄了航天员出舱的全过程。

从报道影像中看,小诤相当接近真人。这种“接近”倒不是说她的画风和建模多么复杂精细,而是她作为一个虚拟数据构成的存在,居然有丰富的面部微表情,以及不少微妙的肢体语言。
比如她拍摄国际空间站航天员出舱时,站在舱门一侧,有无意识的摆手,有微微探身查看舱门的小动作,还有幅度很小的转头——我第一遍看这段视频时,甚至没能发现图像最左边这位是小诤,还以为也是一位国际空间站航天员,就是因为这些动作细节,骗过了我大脑中的辨识器,让我下意识认为“有这些动作的,应该是个真人”。

左一为小诤
众所周知,类人形象的大敌是“恐怖谷效应”:当一个类人形象十分“像人”却又有明显非人特征的时候,我们人类就会产生恐惧的情绪。小诤当然很像真人,但却完全没有触发恐怖谷效应,在B站、微博等小诤亮相的地方,大家的感觉都是“好美”“是不是戴了美瞳”“新老婆来了”,没人觉得恐惧。
要说这是因为小诤过于完美,能骗到所有人,那也不是。我来来回回看了十几遍小诤的视频,发现原因可能在于,她几乎没有那种经常能在各种虚拟形象上看到的“无机质表情”——也就是我们俗称的皮笑肉不笑。
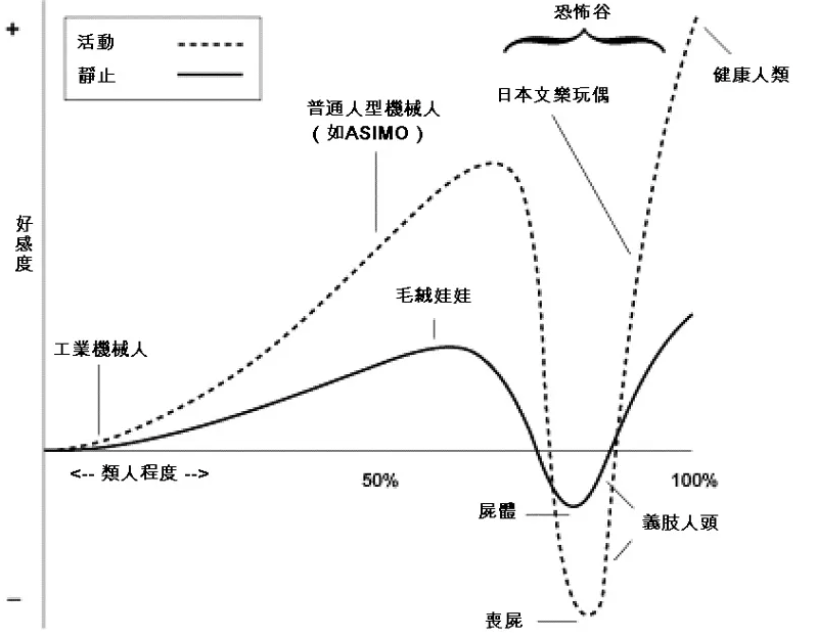
这个猜测直到前几天才得到验证。新华社卫星新闻实验室在上周五发布了一个技术展示视频,呈现了很多驱动小诤的技术细节,比如她说话时,整个脸颊的肌肉都在随之而动。

再比如她的脸上其实是有毛孔的,并不是一整块建模而来。放大之后,皮肤上的凹凸不平,甚至是鼻子里的绒毛(咦?)都能看清。在不同强度的光线下,皮肤也有不同的质感。
和很多数字人一样,小诤的面部动作是由微表情(BlendShapes)驱动的,每个微表情都是根据真人模特的表情进行局部微调的结果——只不过,小诤的建模师模拟出了5000多个微表情,以至于她能做出很多没受过演艺训练的正常人都做不出的微妙神态。

喜怒哀乐
我知道你们现在肯定很想说(或者已经在评论里说了)“游研社除了游戏什么都研究”,但是等等,小诤其实和游戏大有关系——她是新华社和NExT Studios合作的产物,由后者担任实际的动捕和建模等技术工作。

很少有游戏玩家知道,实际上从2017年开始,NExT内部就有一个十几人的小团队,一直在进行虚拟数字人方面的尝试。他们花了半年时间做出了可以交互的Siren(塞壬),在2018年GDC上吸引了不少眼球。

2019年NExT又做了一个男性数字人Matt,为数字人加入了带情绪的面部动作,以及更工业化的制作流程。

而最后出现在我们面前的就是小诤,一个画风和Siren略有不同,但表情精细度犹有过之的数字人。
然而相比这些技术上的进步,作为一个玩家,小诤最大的意义其实在于其制作时间——小诤从接到新华社的合作邀请开始,一共只做了3个月左右,比Siren快了一倍多。
3个月,看起来还是挺久。但对于制作时长动辄三四年的3A游戏来说,一个完整游戏角色的制作时间也差不多是3个月——而根据NExT的说法,他们的数字人技术,在真正的游戏开发多线环境下,可以把时间压到一个月甚至半个月左右。也就是说,NExT的数字人技术管线,理论上来讲已经可以用于实际3A游戏开发了。

关于数字人的硬件和软件近年来都基本成熟了,很多海外游戏大厂发现,他们为自己的游戏制作角色的过程,其实和电影工业用数字技术创造虚拟人物,本质上没什么区别。一直坚持探索数字人领域的,也确实都是和游戏有密切关联的公司。

小诤的前期动捕
Epic今年二月推出了专门创建数字人的工具MetaHuman Creator,创建好的角色,可直接导入到虚幻引擎中。

而前不久关于英伟达四月发布会上“数字黄仁勋骗过了所有人”的讨论,也展示了英伟达在数字人技术上的探索(实际上发布会上只出现了14秒的数字黄仁勋)。

游戏开发史告诉我们,一旦大厂们把一个技术的工业管线跑通,很快就会有个人开发者也能用的套件工具出现——虚幻引擎就是明证,曾经复杂无比的3D场景建模,现在小团队甚至只有一个人的独立开发者也能轻松上手开发。
今天,基于面部捕捉的精细3D人物建模还是大型游戏独有。但也许不久之后,我们就能期待,独立游戏和小团队们开发的游戏也能低成本地做出有表情、有肢体动作的3D人物来。
不过,数字人技术不仅仅可以用于游戏开发、航天探索,完全可以更加贴近普通人的生活。
有一本挺老的科幻小说,叫《雪崩》,在万维网诞生2年后的1992年,就预言了现在我们已经每天沉浸其中的网络空间。这本书中提出了很多极富预见性、影响深远的概念,其中就有avatar这个概念——我们在网络中的虚拟化身,从图片形式的头像到会动的QQ秀,再到任天堂的Mii,乃至苹果的拟我表情,都是人类在不断追求虚拟化身的真实性。《雪崩》把这条线推到了极致,在那个近未来世界里,人们可以直接把3D形象投影到网络中。
Mii——任天堂推出的卡通化身
为什么我们会试图在一个本就虚拟的环境中追求avatar的真实性?《雪崩》用一位女主角的亲身经历做了解答:这位女性高中时意外怀孕,回到家不敢告诉任何人,装作冷静地和家人们吃了饭,没任何人发现,直到她的祖母来串门,看到她脸的一瞬间就明白了整件事——“后来我才恍然大悟,大脑能吸收处理数量惊人的信息,只要它们以适当的形式出现就行,比如真人的面孔”。
今年Metaverse的概念突然火的不行(顺便一说,这个概念就是首次出现于《雪崩》中),各大公司都给出了自己的理解。离玩家最近的一种解读,可能是腾讯的“超级数字场景”,即游戏会在未来打通线上和线下的间隔,与现实产生越来越多的交互。
如果我们哪天真的能进入一个现在还很难想象其面貌的超级数字场景,现有的所有数字化身肯定都过于苍白无力,也许只有充满微表情、肢体动作的3D数字人才能承担起容纳我们形象的任务。从这个角度来说,NExT和小诤都在为超级数字场景添砖加瓦。
也许在未来的某一天,我们每个人都可以像拥有一个QQ头像一样,拥有一个像小诤这样的数字化身,在另一个世界,以另一个身体,再次相见。