
[Machine Learning] 梯度下降法的三种形式BGD、SGD以及MBGD

来源:信息网络工程研究中心 本文约1100字,建议阅读5分钟
本文为你介绍常用的梯度下降法还具体包含有三种不同的形式。
1. 批量梯度下降法BGD 2. 随机梯度下降法SGD 3. 小批量梯度下降法MBGD 4. 总结
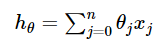
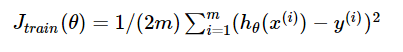
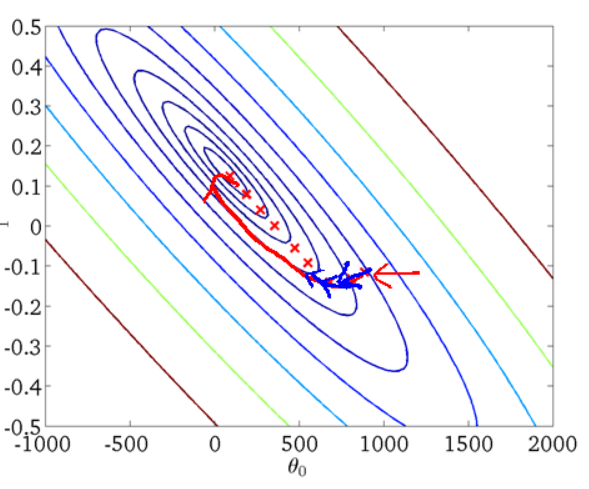
 )组对应能量函数的可视化图:
)组对应能量函数的可视化图: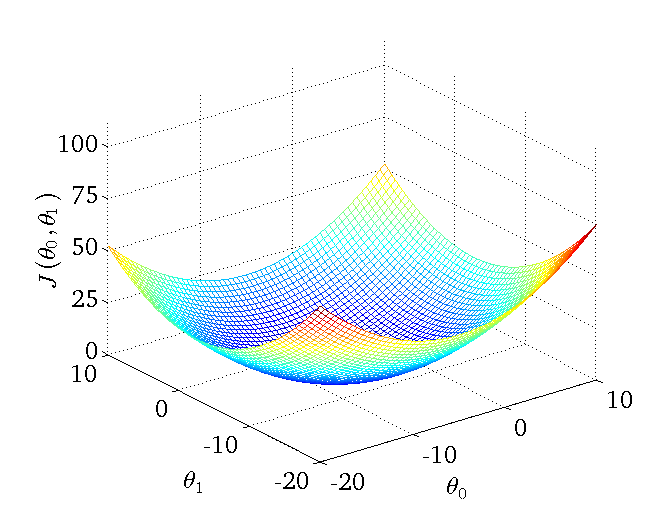
1. 批量梯度下降法BGD
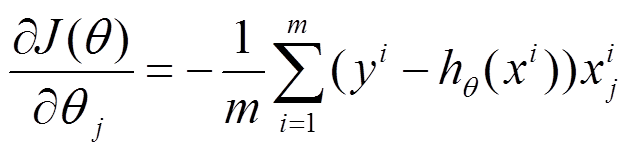
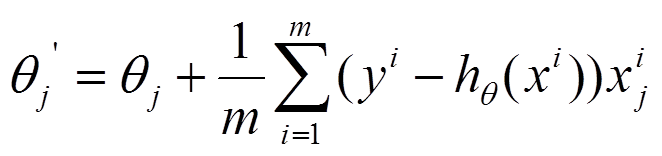
2. 随机梯度下降法SGD
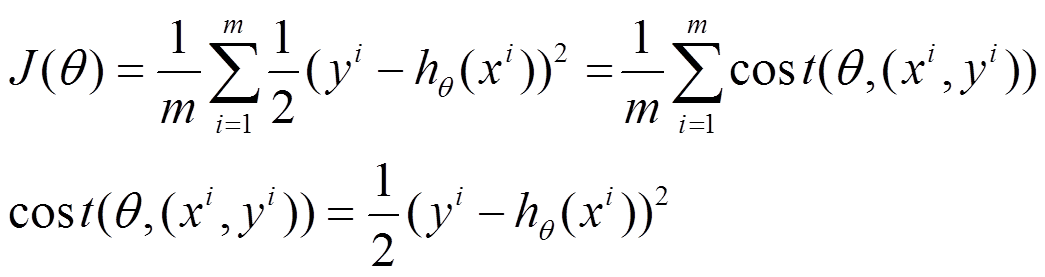
![]()
1. Randomly shuffle dataset;
2. repeat{
for i=1, ... ,m{
![]()
(for j=0, ... ,n)
}
}
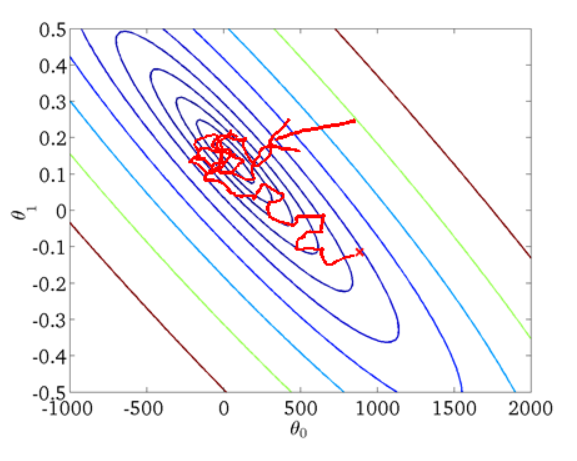
3. 小批量梯度下降法MBGD
Say b=10, m=1000.
Repeat{
for i=1, 11, 21, 31, ... , 991{
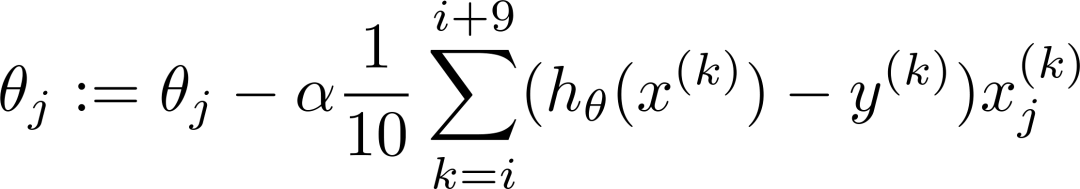
(for every j=0, ... ,n)
}
}
4. 总结
评论