
Fast-SCNN的解释以及使用Tensorflow 2.0的实现
击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作者:Kshitiz Rimal
编译:ronghuaiyang
对图像分割方法Fast-SCNN的解释以及实现的代码分析。
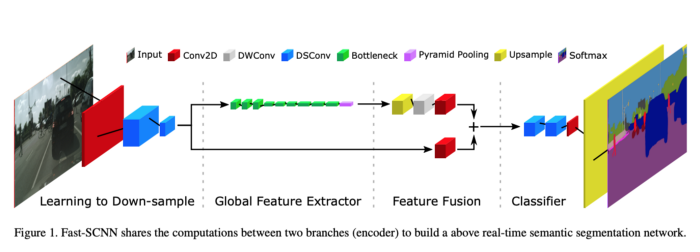
Fast Segmentation Convolutional Neural Network (Fast- scnn)是一种针对高分辨率图像数据的实时语义分割模型,适用于低内存嵌入式设备上的高效计算。原论文的作者是:Rudra PK Poudel, Stephan Liwicki and Roberto Cipolla。本文中使用的代码并不是作者的正式实现,而是我对论文中描述的模型的重构的尝试。
随着自动驾驶汽车的兴起,迫切需要一种能够实时处理输入的模型。目前已有一些最先进的离线语义分割模型,但这些模型体积大,内存大,计算量大,Fast-SCNN可以解决这些问题。
Fast-SCNN的一些关键方面是:
在高分辨率图像(1024 x 2048px)上的实时分割 得到准确率为68%的平均IOU 在Cityscapes数据集上每秒处理123.5帧 不需要大量的预训练 结合高分辨率的空间细节和低分辨率提取的深度特征
此外,Fast-SCNN使用流行的技术中最先进的模型来保证上述性能,像用在PSPNet中的金字塔池模块PPM,使用反向残余瓶颈层是用于MobileNet V2中用的反向残差Bottleneck层,以及ContextNet中的特征融合模块等。同时利用从低分辨率数据中提取的深度特征和从高分辨率数据中提取的空间细节,确保更好、更快的分割。
现在让我们开始 Fast-SCNN的探索和实现。Fast-SCNN由4个主要构件组成。它们是:
学习下采样 全局特征提取器 特征融合 分类器
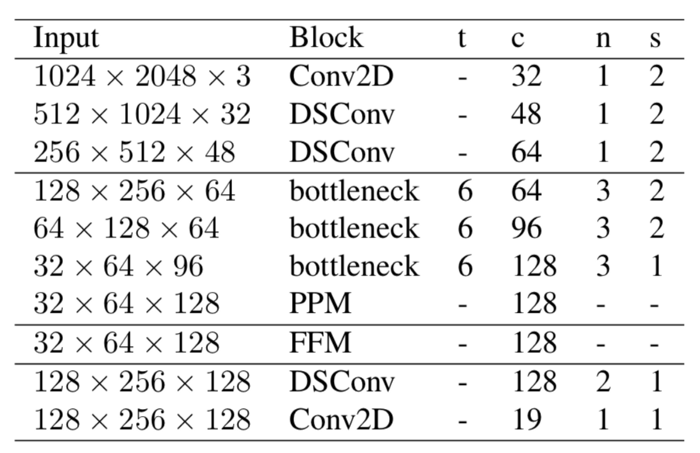
1. 学习下采样
到目前为止,我们知道深度卷积神经网络的前几层提取图像的边缘和角点等底层特征。因此,为了充分利用这一特征并使其可用于进一步的层次,需要学习向下采样。它是一种粗糙的全局特征提取器,可以被网络中的其他模块重用和共享。
学习下采样模块使用3层来提取这些全局特征。分别是:Conv2D层,然后是2个深度可分离的卷积层。在实现过程中,在每个Conv2D和深度可分离的Conv层之后,使用一个Batchnorm层和Relu激活,因为通常在这些层之后引入Batchnorm和激活是一种标准实践。这里,所有3个层都使用2的stride和3x3的内核大小。
现在,让我们首先实现这个模块。首先,我们安装Tensorflow 2.0。我们可以简单地使用谷歌Colab并开始我们的实现。你可以简单地使用以下命令安装:
!pip install tensorflow-gpu==2.0.0
这里,' -gpu '说明我的谷歌Colab笔记本使用GPU,而在你的情况下,如果你不喜欢使用它,你可以简单地删除' -gpu ',然后Tensorflow安装将利用系统的cpu。
然后导入Tensorflow:
import tensorflow as tf
现在,让我们首先为我们的模型创建输入层。在Tensorflow 2.0使用TF.Keras的高级api,我们可以这样:
input_layer = tf.keras.layers.Input(shape=(2048, 1024, 3), name = 'input_layer')
这个输入层是我们要构建的模型的入口点。这里我们使用Tf.Keras函数的api。使用函数api而不是序列api的原因是,它提供了构建这个特定模型所需的灵活性。
接下来,让我们定义学习下采样模块的层。为此,为了使过程简单和可重用,我创建了一个自定义函数,它将检查我想要添加的层是一个Conv2D层还是深度可分离层,然后检查我是否想在层的末尾添加relu。使用这个代码块使得卷积的实现在整个实现过程中易于理解和重用。
def conv_block(inputs, conv_type, kernel, kernel_size, strides, padding='same', relu=True):
if(conv_type == 'ds'):
x = tf.keras.layers.SeparableConv2D(kernel, kernel_size, padding=padding, strides = strides)(inputs)
else:
x = tf.keras.layers.Conv2D(kernel, kernel_size, padding=padding, strides = strides)(inputs)
x = tf.keras.layers.BatchNormalization()(x)
if (relu):
x = tf.keras.activations.relu(x)
return x
在TF.Keras中,Convolutional layer定义为tf.keras.layers,深度可分离层为tf.keras.layers.SeparableConv2D。
现在,让我们通过使用适当的参数来调用自定义函数来为模块添加层:
lds_layer = conv_block(input_layer, 'conv', 32, (3, 3), strides = (2, 2))
lds_layer = conv_block(lds_layer, 'ds', 48, (3, 3), strides = (2, 2))
lds_layer = conv_block(lds_layer, 'ds', 64, (3, 3), strides = (2, 2))
2. 全局特征提取器
这个模块的目的是为分割捕获全局上下文。它直接获取从学习下采样模块的输出。在这一节中,我们引入了不同的bottleneck 残差块,并引入了一个特殊的模块,即金字塔池化模块(PPM)来聚合不同的基于区域的上下文信息。
让我们从bottleneck 残差块开始。

以上是本文对bottleneck残差块的描述。与上面类似,现在让我们使用tf.keras高级api来实现。
我们首先根据上表的描述自定义一些函数。我们从残差块开始,它将调用我们的自定义conv_block函数来添加Conv2D,然后添加DepthWise Conv2D层,然后point-wise卷积层,如上表所述。然后将point-wise卷积的最终输出与原始输入相加,使其成为残差。
def _res_bottleneck(inputs, filters, kernel, t, s, r=False):
tchannel = tf.keras.backend.int_shape(inputs)[-1] * t
x = conv_block(inputs, 'conv', tchannel, (1, 1), strides=(1, 1))
x = tf.keras.layers.DepthwiseConv2D(kernel, strides=(s, s), depth_multiplier=1, padding='same')(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.activations.relu(x)
x = conv_block(x, 'conv', filters, (1, 1), strides=(1, 1), padding='same', relu=False)
if r:
x = tf.keras.layers.add([x, inputs])
return x
这个bottleneck残差块在架构中被多次添加,添加的次数由表中的' n '参数表示。因此,根据本文描述的架构,为了添加n次,我们引入了另一个自定义函数来完成这个任务。
def bottleneck_block(inputs, filters, kernel, t, strides, n):
x = _res_bottleneck(inputs, filters, kernel, t, strides)
for i in range(1, n):
x = _res_bottleneck(x, filters, kernel, t, 1, True)
return x
gfe_layer = bottleneck_block(lds_layer, 64, (3, 3), t=6, strides=2, n=3)
gfe_layer = bottleneck_block(gfe_layer, 96, (3, 3), t=6, strides=2, n=3)
gfe_layer = bottleneck_block(gfe_layer, 128, (3, 3), t=6, strides=1, n=3)
在这里,你会注意到这些bottleneck块的第一个输入来自学习下采样模块的输出。这个全局特征提取器部分的最后一块是金字塔池化模块,简称PPM。
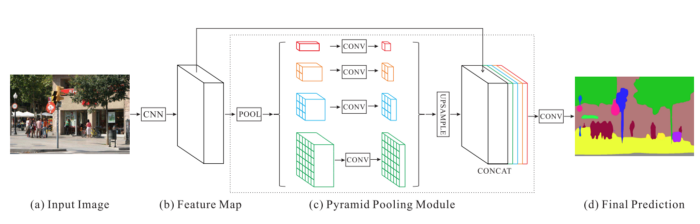
PPM使用上个卷积层出来的特征图,然后应用多个子区域平均池化和以及上采样函数来得到不同的子区域的特征表示,然后连接在一起,这样就带有了本地和全局上下文的信息,可以让图像的分割过程更准确。
使用TF.Keras来实现,我们使用了另外一个自定义函数:
def pyramid_pooling_block(input_tensor, bin_sizes):
concat_list = [input_tensor]
w = 64
h = 32
for bin_size in bin_sizes:
x = tf.keras.layers.AveragePooling2D(pool_size=(w//bin_size, h//bin_size), strides=(w//bin_size, h//bin_size))(input_tensor)
x = tf.keras.layers.Conv2D(128, 3, 2, padding='same')(x)
x = tf.keras.layers.Lambda(lambda x: tf.image.resize(x, (w,h)))(x)
concat_list.append(x)
return tf.keras.layers.concatenate(concat_list)
我们添加这个PPM模块,它将从最后一个bottleneck块获取输入。
gfe_layer = pyramid_pooling_block(gfe_layer, [2,4,6,8])
这里的第二个参数是要提供给PPM模块的bin的数量,这里使用的bin的数量是按照论文中描述的一样。这些bin用于在不同的子区域进行AveragePooling ,如上面的自定义函数所述。
3. 特征融合
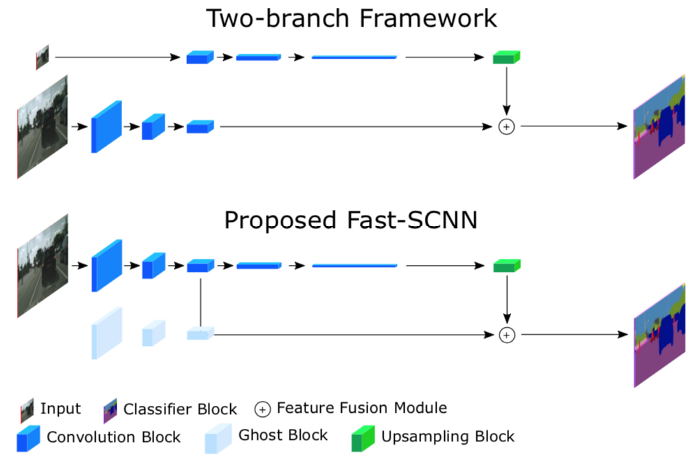
在这个模块中,两个输入相加以更好地表示分割。第一个是从学习下采样模块中提取的高级特征,这个学习下采样模块先进行point-wise卷积,再加入到第二个输入中。这里在point-wise卷积的最后没有进行激活。
ff_layer1 = conv_block(lds_layer, 'conv', 128, (1,1), padding='same', strides= (1,1), relu=False)
第二个输入是全局特征提取器的输出。但在加入第二个输入之前,它们首先进行上采样(4,4),然后进行DepthWise卷积,最后是另一个point-wise卷积。在point-wise卷积输出中不添加激活,激活是在这两个输入相加后引入的。
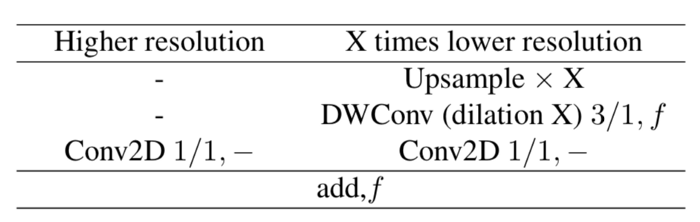
这是使用TF.Keras实现的低分辨率操作:
ff_layer2 = tf.keras.layers.UpSampling2D((4, 4))(gfe_layer)
ff_layer2 = tf.keras.layers.DepthwiseConv2D(128, strides=(1, 1), depth_multiplier=1, padding='same')(ff_layer2)
ff_layer2 = tf.keras.layers.BatchNormalization()(ff_layer2)
ff_layer2 = tf.keras.activations.relu(ff_layer2)
ff_layer2 = tf.keras.layers.Conv2D(128, 1, 1, padding='same', activation=None)(ff_layer2)
现在,让我们将这两个输入添加到特征融合模块中。
ff_final = tf.keras.layers.add([ff_layer1, ff_layer2])
ff_final = tf.keras.layers.BatchNormalization()(ff_final)
ff_final = tf.keras.activations.relu(ff_final)
4. 分类器
在分类器部分,引入了2个深度可分离的卷积层和1个Point-wise的卷积层。在每个层之后,还进行了BatchNorm层和ReLU激活。
这里需要注意的是,在原论文中,没有提到在point-wise卷积层之后添加上采样和Dropout层,但在本文的后面部分描述了这些层是在 point-wise卷积层之后添加的。因此,在实现过程中,我也按照论文的要求引入了这两层。
在根据最终输出的需要进行上采样之后,SoftMax将作为最后一层的激活。
classifier = tf.keras.layers.SeparableConv2D(128, (3, 3), padding='same', strides = (1, 1), name = 'DSConv1_classifier')(ff_final)
classifier = tf.keras.layers.BatchNormalization()(classifier)
classifier = tf.keras.activations.relu(classifier)
classifier = tf.keras.layers.SeparableConv2D(128, (3, 3), padding='same', strides = (1, 1), name = 'DSConv2_classifier')(classifier)
classifier = tf.keras.layers.BatchNormalization()(classifier)
classifier = tf.keras.activations.relu(classifier)
classifier = conv_block(classifier, 'conv', 19, (1, 1), strides=(1, 1), padding='same', relu=True)
classifier = tf.keras.layers.Dropout(0.3)(classifier)
classifier = tf.keras.layers.UpSampling2D((8, 8))(classifier)
classifier = tf.keras.activations.softmax(classifier)
编译模型
现在我们已经添加了所有的层,让我们创建最终的模型并编译它。为了创建模型,如上所述,我们使用了来自TF.Keras的函数api。这里,模型的输入是学习下采样模块中描述的初始输入层,输出是最终分类器的输出。
fast_scnn = tf.keras.Model(inputs = input_layer , outputs = classifier, name = 'Fast_SCNN')
现在,让我们用优化器和损失函数来编译它。在原论文中,作者在训练过程中使用了动量值为0.9,批大小为12的SGD优化器。他们还在学习率策略中使用了多项式学习率,base值为0.045,power为0.9。为了简单起见,我在这里没有使用任何学习率策略,但如果需要,你可以自己添加。此外,在编译模型时从ADAM optimizer开始总是一个好主意,但是在这个CityScapes dataset的特殊情况下,作者只使用了SGD。但在一般情况下,最好从ADAM optimizer开始,然后根据需要转向其他不同的优化器。对于损失函数,作者使用了交叉熵损失,在实现过程中也使用了交叉熵损失。
optimizer = tf.keras.optimizers.SGD(momentum=0.9, lr=0.045)
fast_scnn.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
在本文中,作者使用CityScapes数据集中的19个类别进行训练和评价。通过这个实现,你可以根据特定项目所需的任意数量的输出进行调整。
下面是一些Fast-SCNN的验证结果,与输入图像和ground truth进行了比较。


英文原文:https://medium.com/deep-learning-journals/fast-scnn-explained-and-implemented-using-tensorflow-2-0-6bd17c17a49e
最后的最后求一波分享!
YOLOv4 trick相关论文已经下载并放在公众号后台
关注“AI算法与图像处理”,回复 “200714”获取
个人微信 请注明:地区+学校/企业+研究方向+昵称 如果没有备注不拉群!
