
基础模型自监督预训练的数据之谜:大量数据究竟是福还是祸?
前言 在自监督预训练中,是否数据越多越好?数据增广是否始终有效?
作者:诺亚方舟实验室

论文链接:
此外,团队还提出了一种名为混合自编码器 (MixedAE) 的简单而有效的方法,将图像混合应用于 MAE 数据增强。MixedAE 在各种下游任务(包括图像分类、语义分割和目标检测)上实现了最先进的迁移性能,同时保持了显著的效率。这是第一个从任务设计的角度将图像混合作为有效数据增强策略应用于基于纯自编码器结构的 Masked Image Modeling (MIM) 的研究。该工作已被 CVPR 2023 会议接收。

论文链接:

研究背景

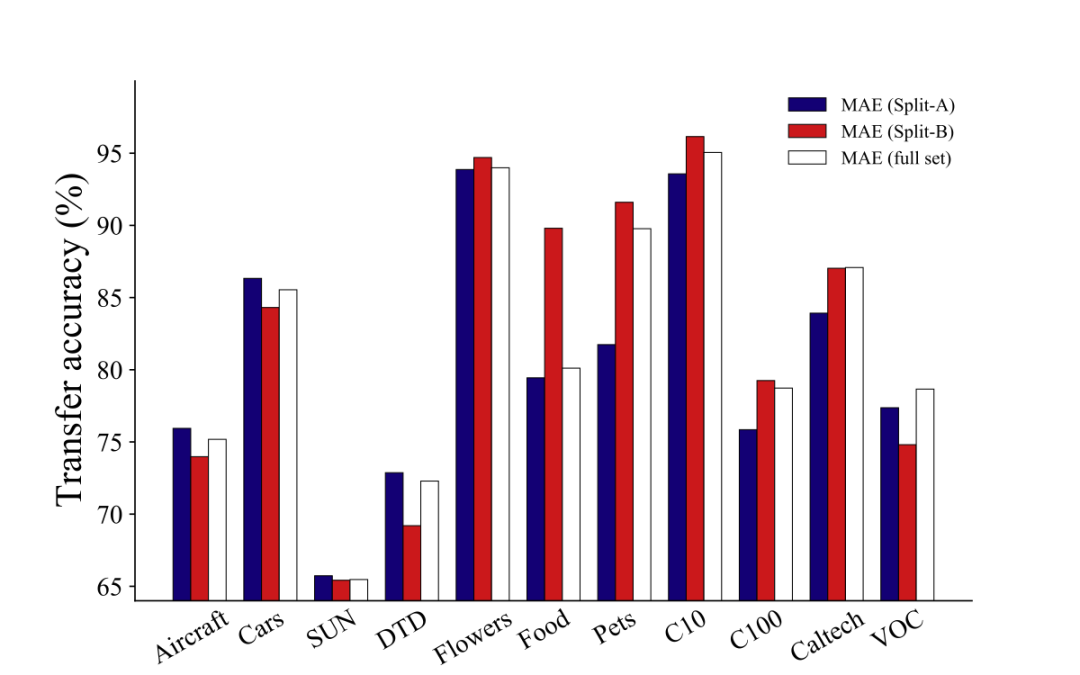
▲ 图一:我们用ImageNet的两个子集,Split-A和Split-B,训练两个MAE模型,和全量数据集训练的模型相比较,后者仅在2个数据集上达到了最优。这说明,增大数据量并不总是带来更强的迁移效果。
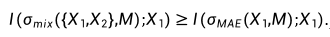

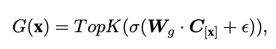


实验分析
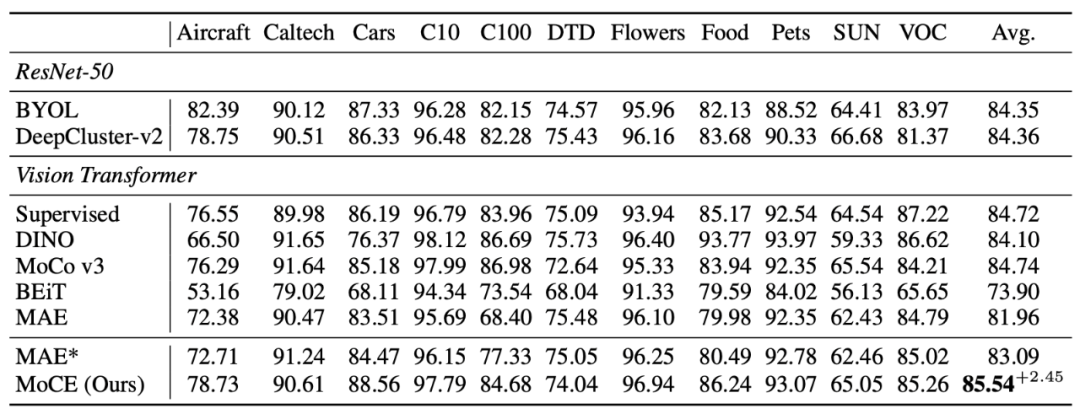
我们在之前提到的 11 个下游分类数据集和检测分割任务上做了实验。实验结果表明,MoCE 在多个下游任务中的性能超过了传统的 MAE 预训练方法。具体而言,在图像分类任务中,MoCE 相较于 MAE 实现了更高的准确率。在目标检测和分割任务中,MoCE 也取得了更好的表现,包括更高的 mIoU 和 AP 指标。这些实验结果表明,MoCE 通过利用相似语义图像进行聚类并为每个专家进行任务定制的自监督预训练,能够在各种下游任务中提高迁移性能。
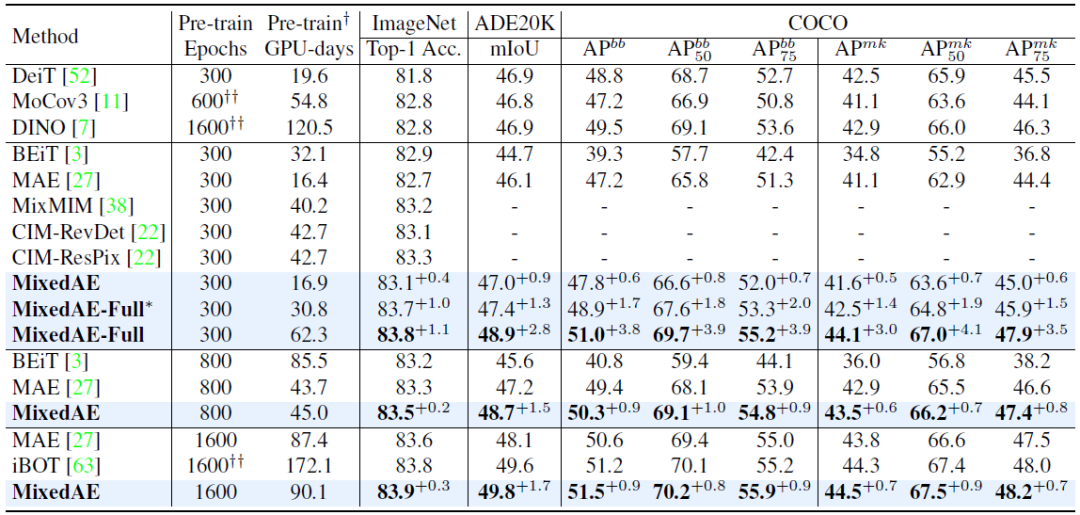
在 14 个下游视觉任务(包括图像分类、语义分割和物体检测)的评估中,MixedAE 展现了最优的迁移性能和卓越的计算效率。相较于 iBOT,MixedAE 实现了约 2 倍预训练加速。得益于图像混合所带来的物体感知预训练,MixedAE 在下游密集预测任务上取得更显著的性能提升。注意力图可视化结果表明,MixedAE 能比 MAE 更准确完整地识别图像前景物体,从而实现优异的密集预测迁移性能。
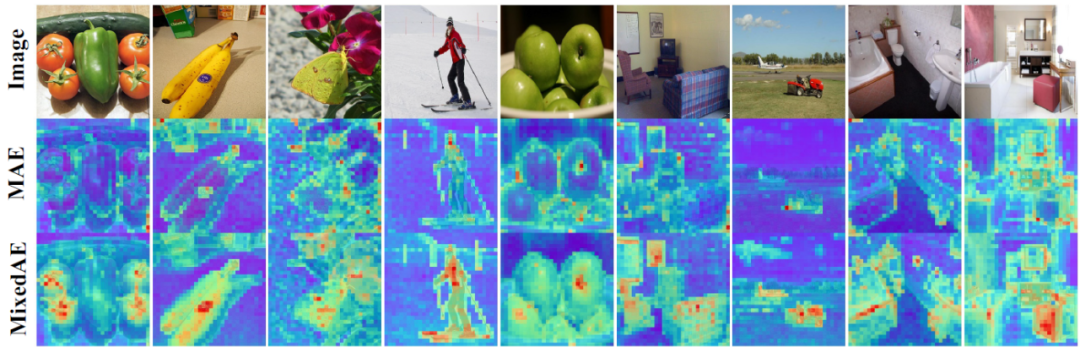
▲ 图二:注意力图可视化。得益于ImageNet的单实例假设[2]以及物体感知的自监督预训练,MixedAE可以更准确完整地发现图像前景物体,从而实现更好的密集预测迁移性能。


参考文献
[1] Task-customized Self-supervised Pre-training with Scalable Dynamic Routing, AAAI 2022.
[2] MultiSiam: Self-supervised Multi-instance Siamese Representation Learning for Autonomous Driving, ICCV 2021.