本文为论文,建议阅读5分钟
我们提出了统一自监督视觉预训练(UniVIP)
论文标题:UniVIP: A Unified Framework for Self-Supervised Visual Pre-training
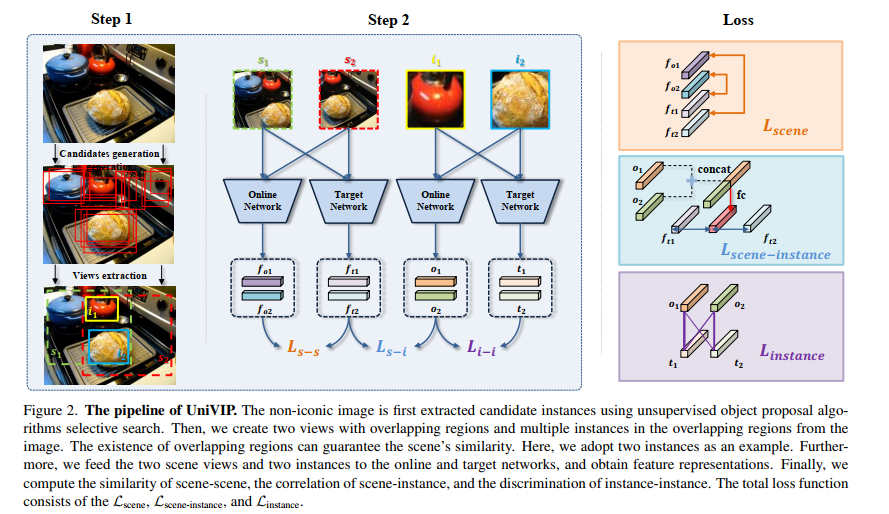
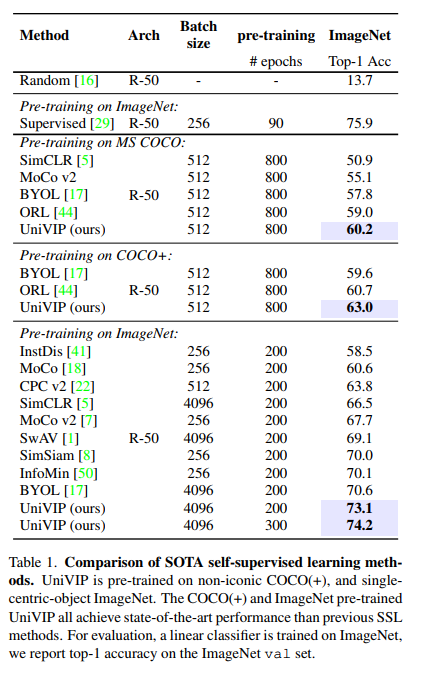
论文链接:https://arxiv.org/abs/2203.06965作者单位:中国科学院自动化研究所 & 商汤科技 & 南洋理工大学自监督学习 (SSL) 有望利用大量未标记的数据。然而,流行的 SSL 方法的成功仅限于像 ImageNet 中的单中心对象图像,并且忽略了场景和实例之间的相关性,以及场景中实例的语义差异。为了解决上述问题,我们提出了统一自监督视觉预训练(UniVIP),这是一种新颖的自监督框架,用于在单中心对象或非标志性数据集上学习通用视觉表示。该框架考虑了三个层次的表示学习:1)场景-场景的相似性,2)场景-实例的相关性,3)实例的判别。在学习过程中,我们采用最优传输算法来自动测量实例的区分度。大量实验表明,在非标志性 COCO 上预训练的 UniVIP 在图像分类、半监督学习、对象检测和分割等各种下游任务上实现了最先进的传输性能。此外,我们的方法还可以利用 ImageNet 等单中心对象数据集,并且在线性探测中使用相同的预训练 epoch 时比 BYOL 高 2.5%,并且在 COCO 数据集上超越了当前的自监督对象检测方法,证明了它的普遍性和潜在性能。