
OpenAI:基于对比学习的无监督预训练

如何无监督地训练一个神经检索模型是当前IR社区的研究热点之一,在今天我们分享的论文中,OpenAI团队尝试在大规模无监督数据上对GPT系列模型做对比预训练(Contrastive Pre-Training),得到的 CPT-text模型 在文本匹配、语义搜索等任务上取得了优异的zero-shot性能。
OpenAI: Text and Code Embeddings by Contrastive Pre-Training http://arxiv.org/abs/2201.10005 Blog:Introducing Text and Code Embeddings in the OpenAI API[1]
在语义搜索、文本相似度计算等应用场景中,如何得到优质的文本嵌入(Text Embedding)一直是一个核心研究问题,以往的研究工作通常会从训练数据、训练目标和模型结构三个角度来优化文本嵌入,而OpenAI的这篇工作表明在无监督数据上做大规模的对比学习预训练就可以得到高质量的文本嵌入。
Approach
无监督对比学习的关键问题就是如何构造要对比的样本,而本文提出可以对文本中相邻的片段做对比,即将相邻片段作正样本,而负样本则通过批内负采样得到,这一思路与BERT中的NSP任务有些类似。
在模型训练过程中,给定一个训练样本 ,编码器首先独立地编码 和 ,并将 对应的低维稠密向量作为文本的表示,将 和 的余弦相似度作为相关性打分:
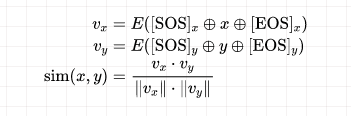
得到相关性打分后,使用批内负样本策略构建对比损失,即针对大小为 的batch中的每个样本,将其他的 个样本当作当前样本的负样本,而每个batch的logits是一个 的矩阵:
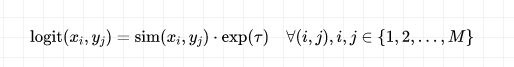
其中 是一个可训练的温度参数。在该 的矩阵中,只有对角线上的项被当作正样本,最终的loss为行方向和列方向的交叉熵损失之和,用伪代码可表示为:
labels = np.arange(M)
l_r = cross_entropy(logits, labels, axis=0)
l_c = cross_entropy(logits, labels, axis=1)
loss = (l_r + l_c) / 2
最终就得到了完全无监督的文本嵌入模型,作者将其称之为cpt-text。
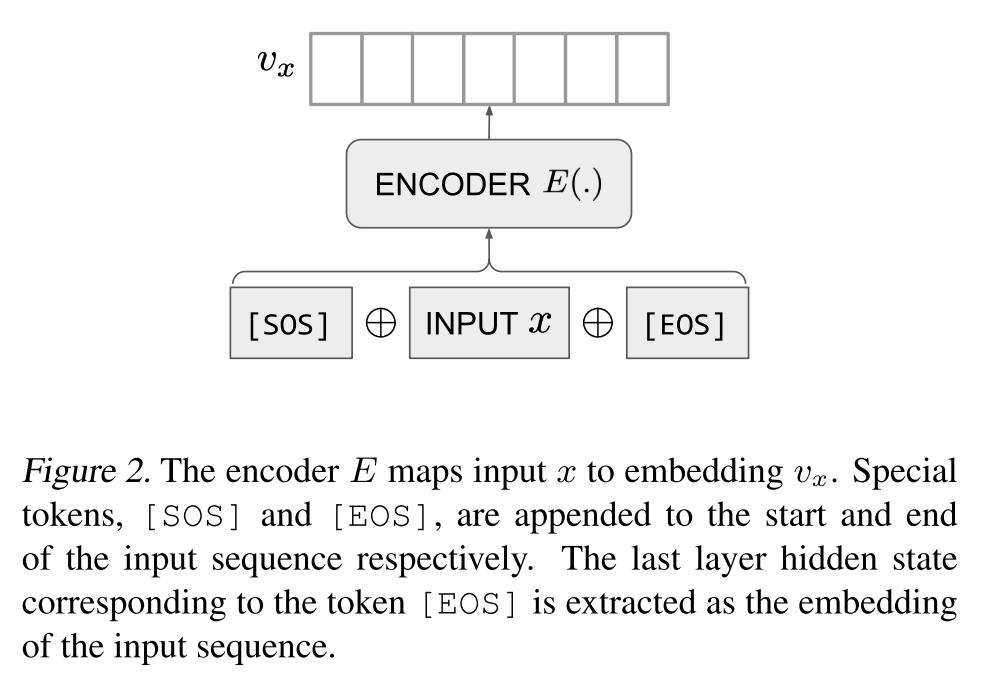
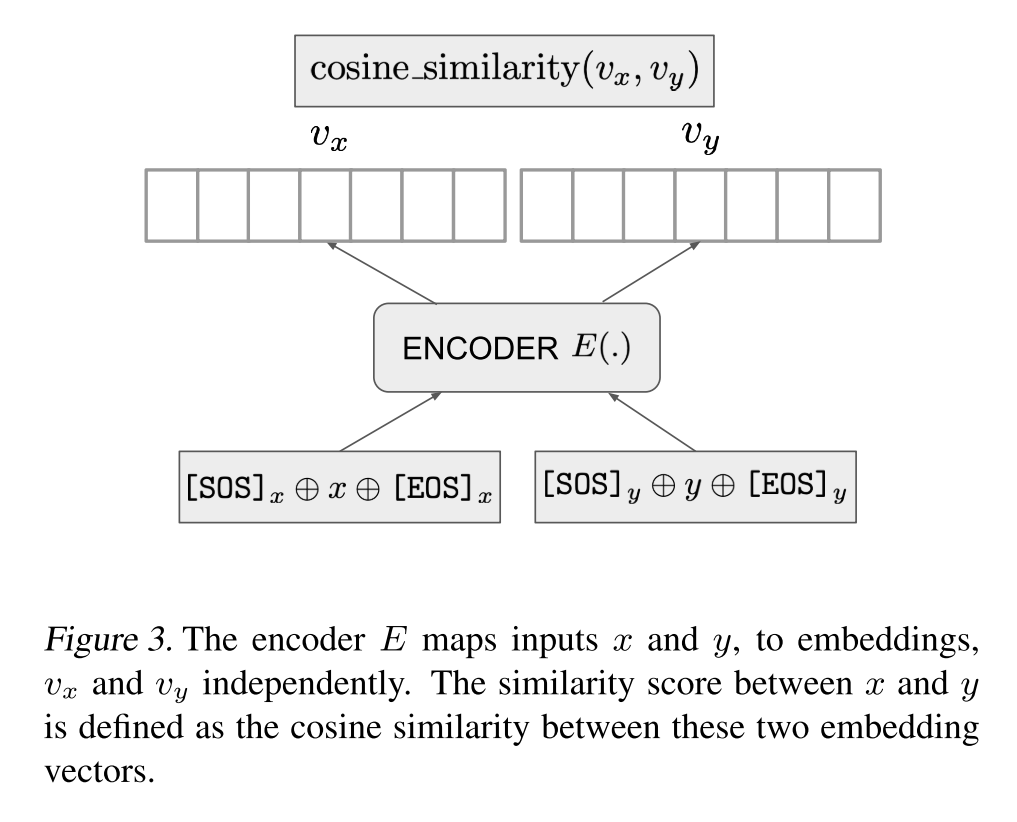
Setup
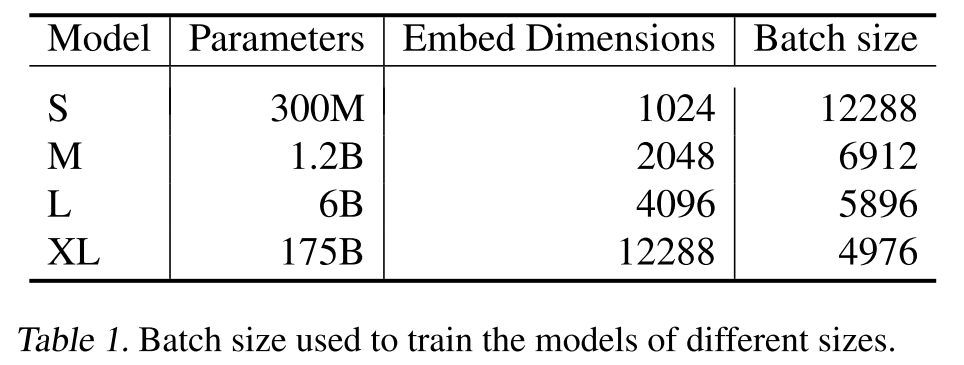
作者用不同大小的GPT系列模型做模型初始化,如下表所示,针对不同大小的模型,作者分别设置了不同的隐层维数和批量大小。
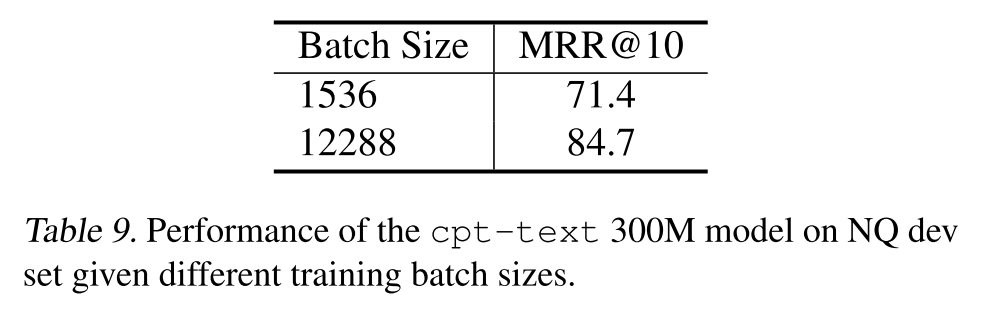
另外,本文也再次验证了做对比学习显卡越多越好:
Results
虽然文本相似度(Sentence Similarity)任务和语义搜索(Semantic Search)任务的目标都是获取高质量的文本表示,但面向这两个任务的相关研究长期以来都是割裂的,也就是说,做文本相似度任务的论文不会评估模型在语义搜索任务上的效果,反之亦然。而下述实验结果表明本文作者的cpt-text可以在两个任务上都取得不错的表现。
线性探测分类任务
线性探测分类(linear-probe classification)是指将embedding作为下游任务的特征训练一个线性分类器,用于评估embedding在某个任务上的区分能力,实验结果如下表所示:
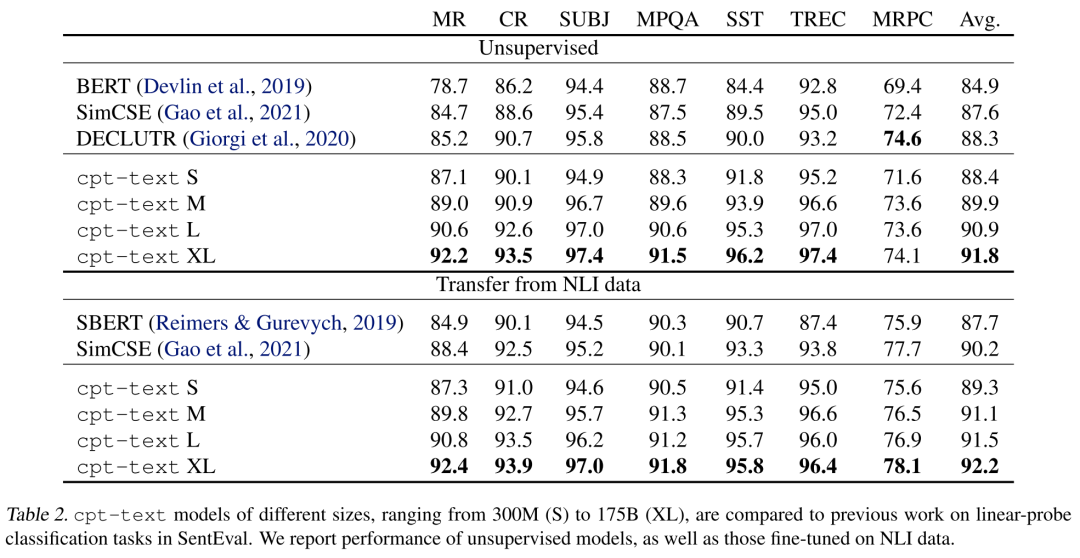
可以看到,直接评估cpt-text(unsupervised)和先在NLI数据集上微调后再评估(Transfer from NLI data)的整体区别并不是很大,cpt-text整体上也超越了SimCSE这种强基线模型,且最大的模型(175B)取得了SOTA结果。
zero-shot classification
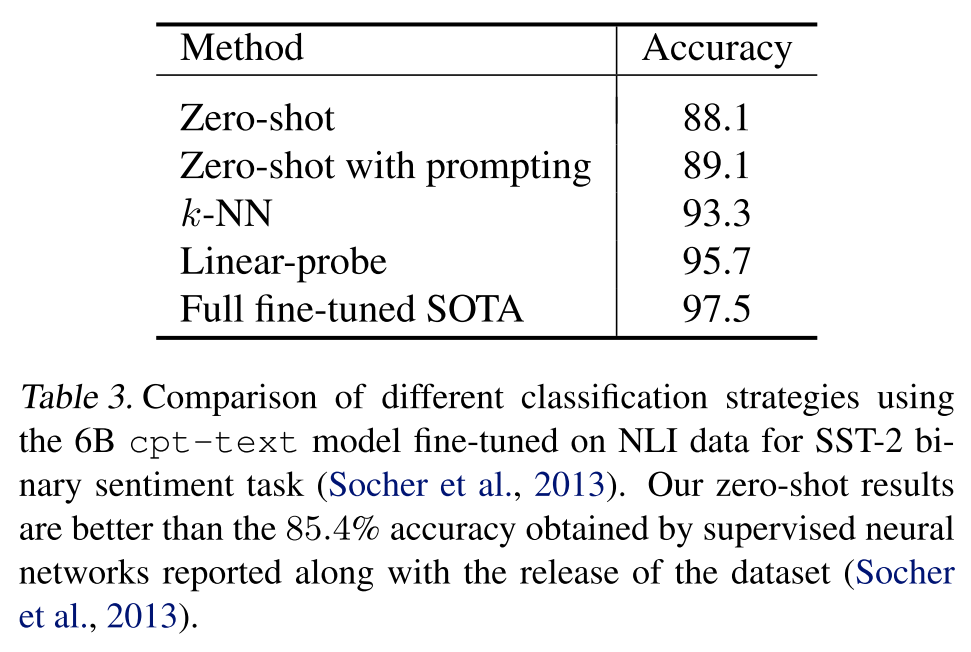
作者在二元情感分类数据集SST-2上进一步评估了embedding的质量,如下表所示,其中zero-shot表示计算输入样本分别和positive和negative这两个词的embedding的距离,并将更近的那个词作为预测标签;zero-shot with prompting表示将上述的单个词positive和negative替换为了一个更完整的句子,比如this is an example of a positive/negative movie review。但zero-shot方法比后续的 -NN()和线性分类都要差不少。
Sentence Similarity
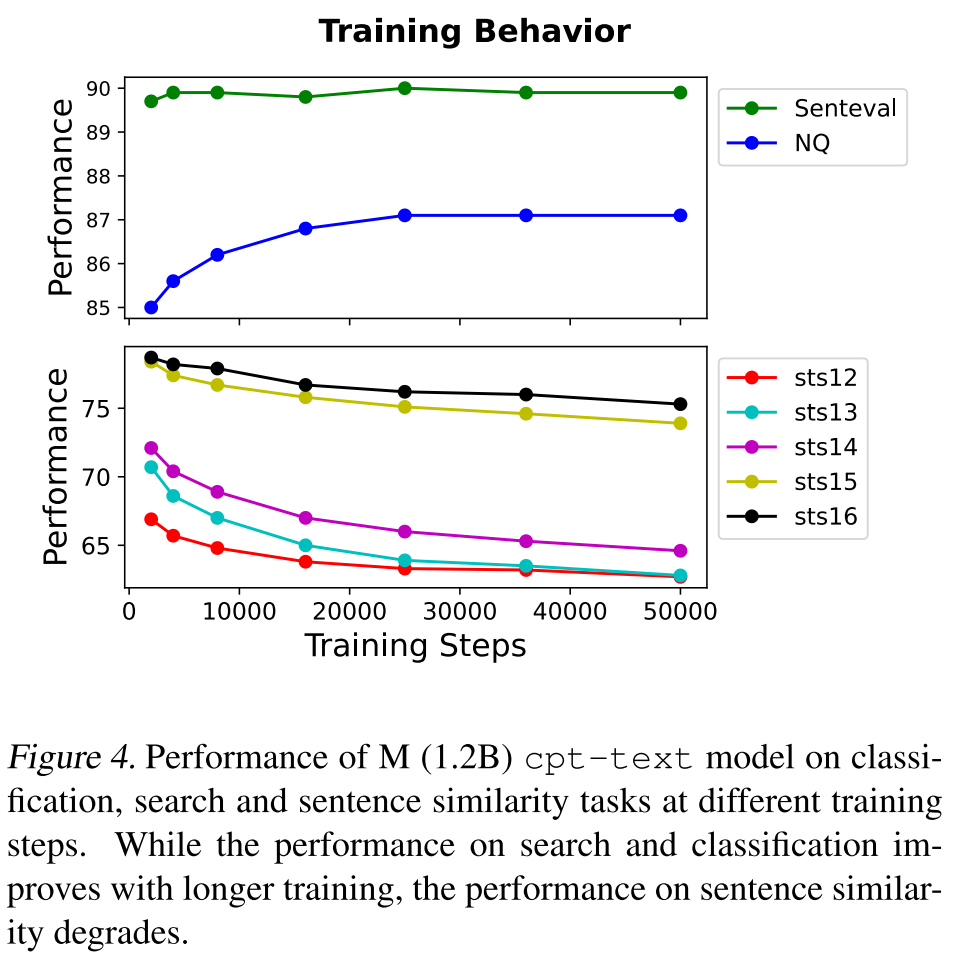
奇怪的是,cpt-text在SentEval基准上要比之前的无监督SOTA差很多,如下表所示,作者认为可能的原因是句子相似度任务的定义本身就不明确,即相同的句子对在不同的人看来相似度可能是不一样的,最典型的一类case就是情感极性不同的样本是否是相似的。
从预训练任务的角度来看,cpt-text的预训练任务是拉近相邻片段的距离,但相邻片段在语义上是相关但不相似的,也就是说该预训练任务实际上更接近于语义搜索的相关性建模,所以作者的模型在句子相似度任务上的表现就不如SimCSE了,因为SimCSE对比损失的构造更接近于句子相似度任务的定义。
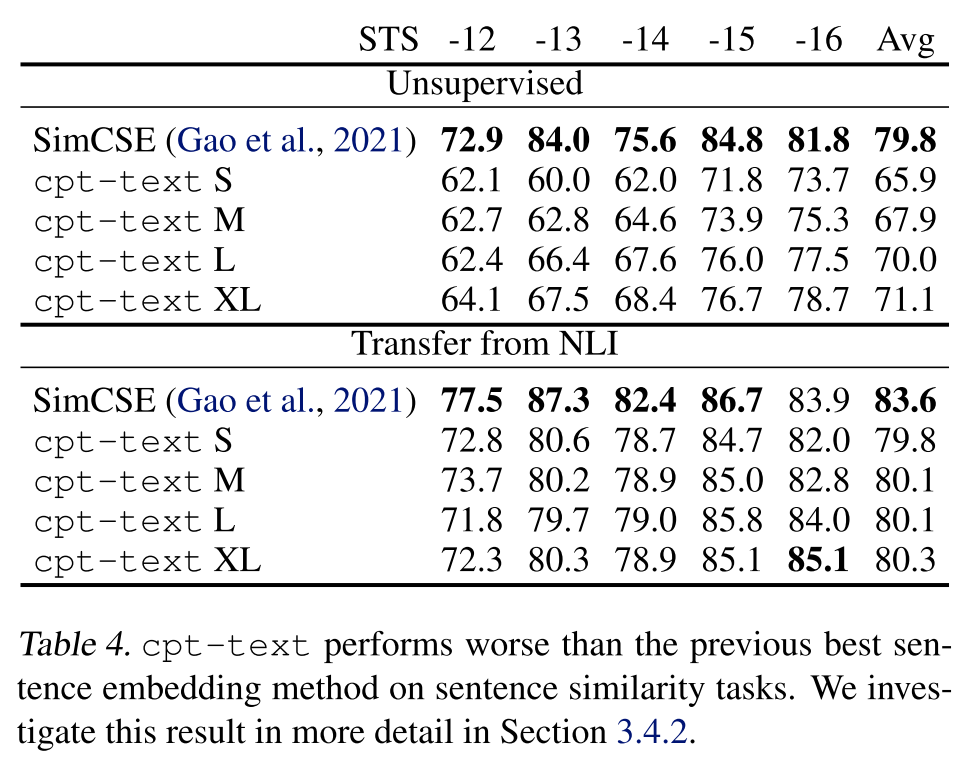
另外,作者发现随着训练的进行,模型在线性探测和语义搜索任务上的表现越来越好,但是在句子相似度任务上的表现却越来越差,这进一步说明句子相似度和语义搜索的确是两个不同的任务,甚至他们的训练目标可能存在一定的冲突,比如针对同一个事物表达肯定的句子和一个表达否定的句子,在语义搜索中可能会被当作正样本,而在句子相似度任务上则会被当作负样本。
Semantic Search
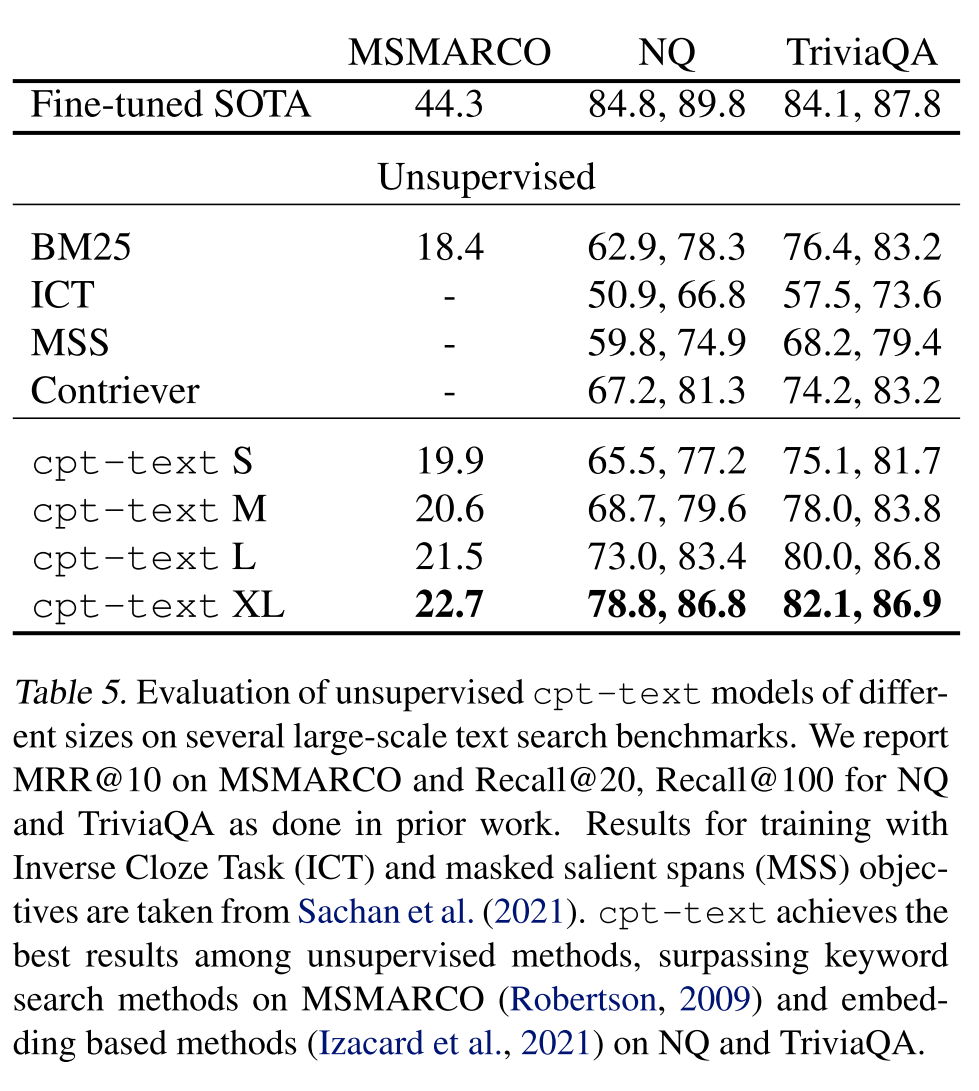
下表展示了cpt-text在语义搜索基准MSMARCO、NQ和TriviaQA上的表现,cpt-text超越了一些经典的无监督方法。
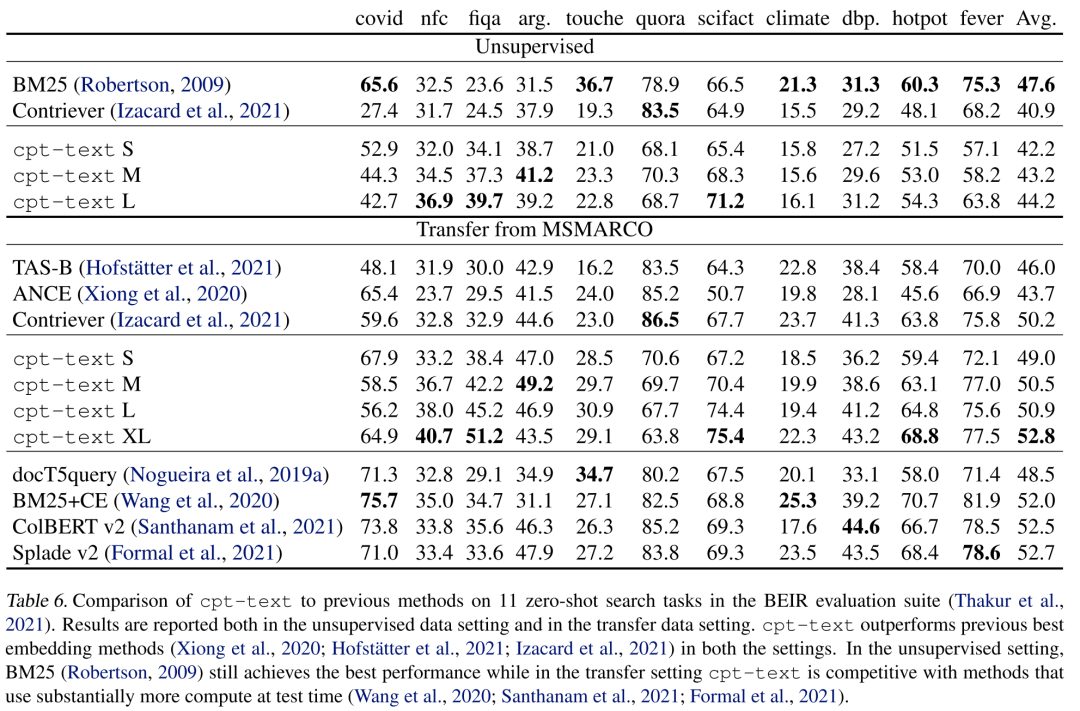
另外作者也评估了cpt-text的zero-shot性能,下表展示了cpt-text在BEIR基准上的表现,在无监督的条件下,cpt-text与BM25还是有一定距离,但在经过MSMARCO微调后,cpt-text超越了BM25,其中175B模型取得了SOTA结果。
Discussion
虽然是OpenAI发表的论文,但读下来感觉更像是一篇面向GPT-3的PR论文。比较有启发的点主要是大规模对比预训练的效果确实很好,之前已经有很多论文证明了这一点,但一味的scaling可能也并没有从本质上解决语义检索模型的泛化问题,提升的那部分指标可能仅仅是模型见得更多,记得更多了而已。
- 点击下方阅读原文加入社区会员 -