
从OpenAI VPT,看视频预训练
程序化任务,比如存活多少天、打败多少敌人,这种目标模拟器里很好计算结果,直接作为奖励即可。
创造性任务,比如骑着猪跑,这类就很不容易了,没法一个个用规则去写奖励函数。
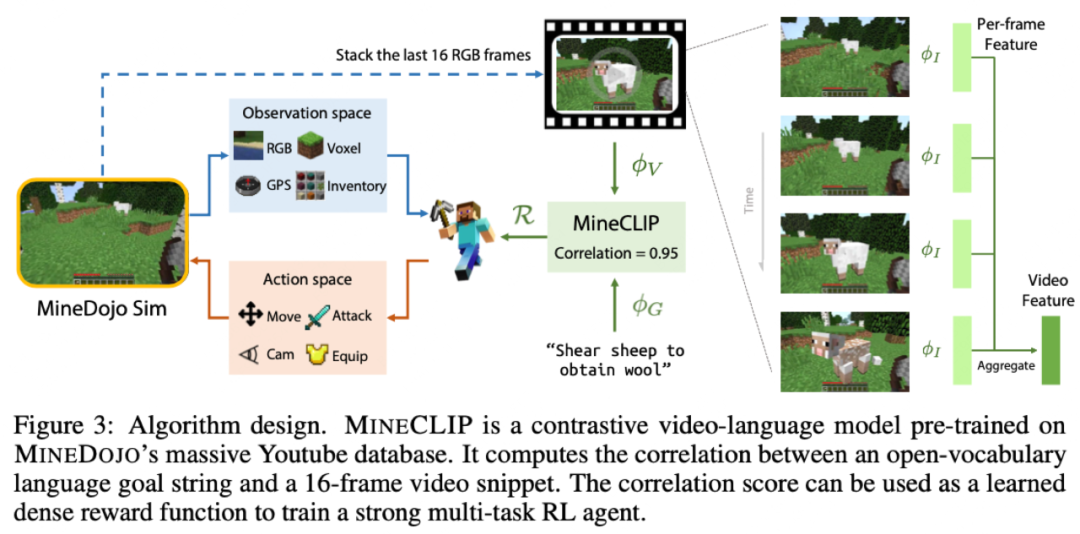
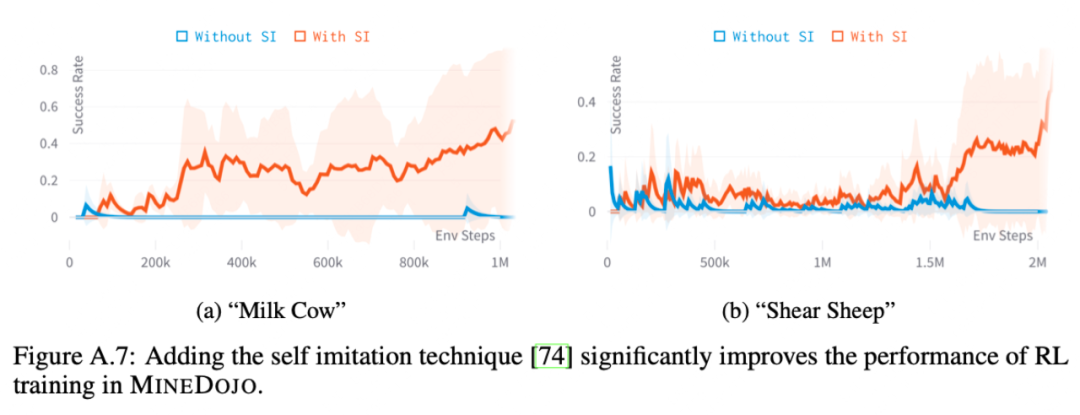

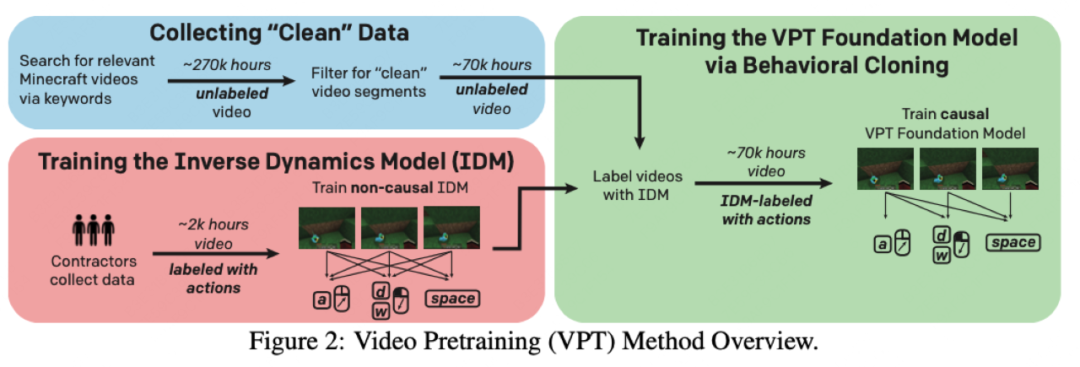
图像与文本的预训练数据不兼容:目前互联网的语料都是图像或者文字一方占主导,所以后续大概率是和现在一样,两种模态分别预训练,再通过少量数据融合。
VPT的方法不够通用:像NLP一样进行通用领域的视频预训练还有很长的路要走。首先VPT在准备训练语料时,需要定义标签的动作空间,目前只局限在鼠标和键盘,但真实世界中的动作太多了;另外很多领域的监督数据也不一定好获取,比如需要真人出镜的视频成本会很高。
参考资料
[1]Video-Pre-Training: https://cdn.openai.com/vpt/Paper.pdf
[2]MineDojo: https://minedojo.org/
评论