
从顶会论文看多模态预训练研究进展

本文约4000字,建议阅读5分钟 本文主要从以下几个方面对近期多模态预训练模型的工作进行介绍:预训练模型、多模态prompt、多模态预训练分析、知识迁移和知识蒸馏。
本文简化了多模态预训练模型图片编码器,提出一种很简单的多模态模型,在保证效果的前提下大大减小了模型复杂度和运行时间。
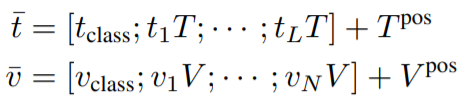
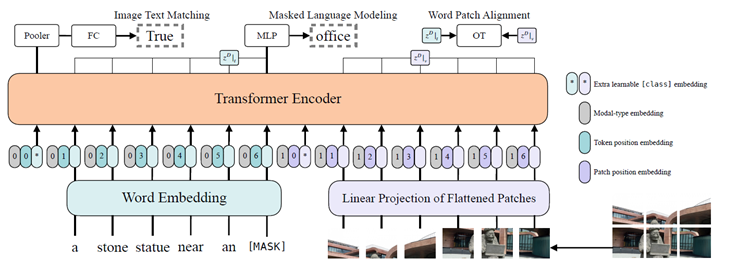
Image Text Matching Masked Language Modeling
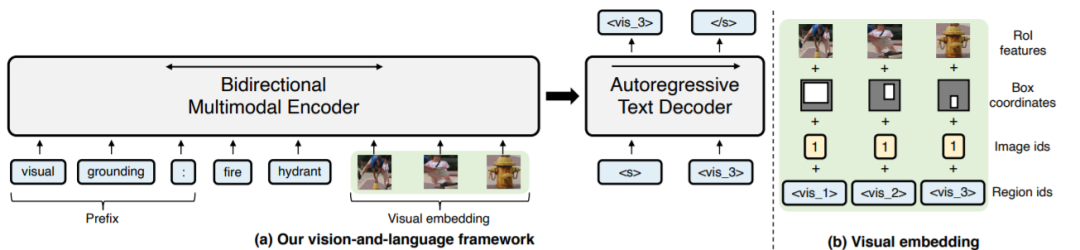
Multimodal language modeling: T5和BART各自沿用了其预训练的语言模型任务,只是在encoder输入的时候不止输入文本,还输入图片; Visual question answering: 给定图片和问题,直接生成答案; Image-text matching Visual grounding: 输入一个object的描述以及一张图片,输出图中正确object所对应的visual token; Grounded captioning: 与上一个任务相反,输入图片和一个object的visual token,输出对这个object的描述。
纯文本语料上的预训练能够帮助模型提升多模态任务上的性能; 图片和多模态数据上的预训练能够帮助模型更好地完成NLU任务。
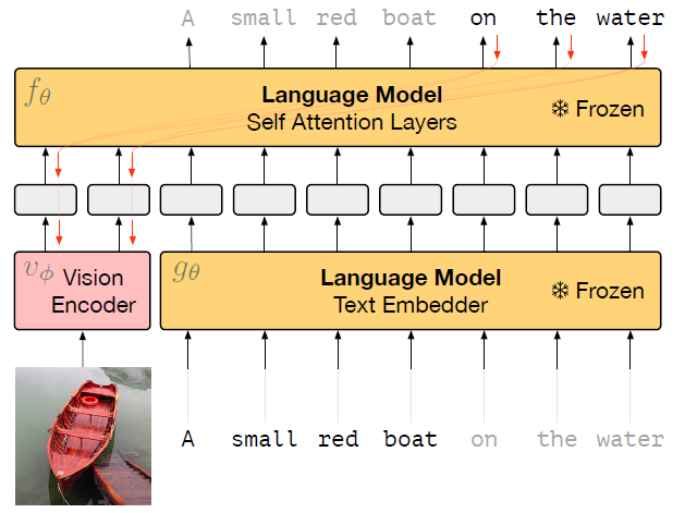
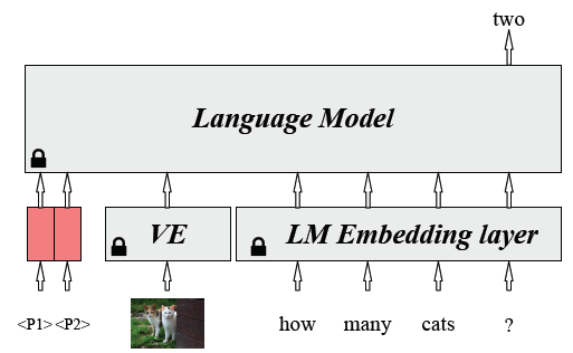
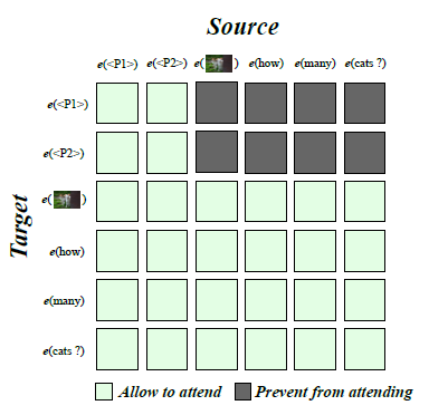
不管是单流还是双流,多模态的预训练模型都比预训练语言模型在NLU任务上表现更差,单流模型比双流模型略好; 上述NLU任务上性能的下降主要是由预训练任务造成的,而不是模型结构; 论文研究了多模态预训练模型的参数是如何在预训练语言模型的基础上变动的,并研究了每一个预训练模型能解决的任务; 多模态的任务最好采用单流的架构,并精心设计预训练任务来保持预训练语言模型的知识。
MLM:在image caption上进行MLM,相当于进行了domain adaptive的预训练; Text Contrastive Learning (TCL): 采用和SimCSE一样的方式,进行对比学习。
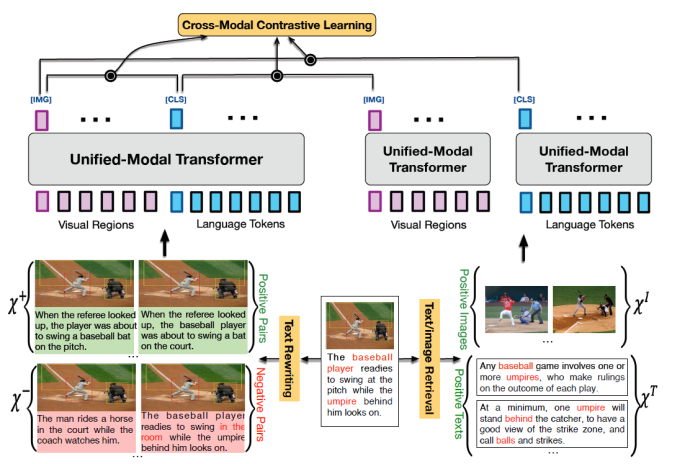
Voken Classification: voken[4]采用token层面的text2image检索来迁移视觉知识,它假设每一个token都有一个视觉域的voken与其对应,训练目标就是在所有预先设定好的voken中将正确的voken检索出来; Masked Language Modeling with Visual Clues: 给定图片作为线索,预测mask掉的token,比MLM多了图片作为输入,目标函数是一样的; Cross-Modal Contrastive Learning (CMCL): 和CLIP一样,是跨模态的对比学习; Cross-Modal Knowledge Distillation (CMKD): 将在MSCOCO数据集上进行对比学习的多模态模型作为teacher model,将一个语言模型作为student,在纯文本语料Wiki103上进行知识蒸馏。
Text-Text Distance Minimization (TTDM): 最小化BART编码器和CLIP文本编码器得到的text embedding之间的距离; Image-Text Contrastive Learning (ITCL): 在BART编码的文本和CLIP编码的图片表示之间进行跨模态的对比学习; Image-Conditioned Text Infilling (ITCL): 上面两个目标只是对BART的编码器进行了更新,没有动解码器。此处在(image, text) pair数据集上将CLIP的视觉表示和BART编码器的文本表示投影到与BART解码器相同的维度上,然后进行conditional text generation,使得BART的编码器也能理解视觉表示。
参考文献
[1] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
[2] Language Models are Few-shot Learners
[3] Prefix-Tuning: Optimizing Continuous Prompts for Generation
[4] Vokenization: Improving Language Understanding with Contextualized, Visual-Grounded Supervision
[5] Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
评论