推荐系统通用用户表征预训练研究进展
随着NLP和CV领域的发展,涌现出了以BERT,GPT为代表的大规模语言模型和以ImageNet为代表的各种经典视觉模型,如resnet和visual transformer,在各自领域都产生了很大的成功,而且实现了通用语言/视觉表征能力,例如BERT学好的语言表征可以被应用到各种各样的下游任务。受到相关技术的启发,推荐系统最近两年也出现了一些学习用户通用表征的算法和深度模型,也就是,通过对用户行为进行某种程度预训练,然后adapt到一些下游任务中,这些下游任务包括,跨域推荐和用户画像预测,本文简要介绍几种代表性工作, 优先并重点介绍了有代码和数据集的论文,以便大家更好的follow。本帖子参考了一些相关技术帖。
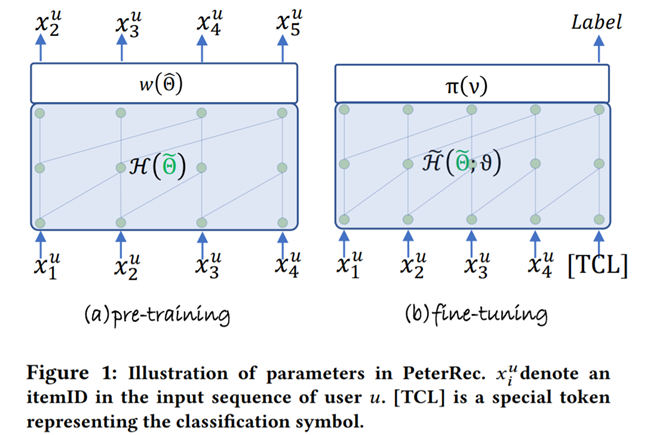
Parameter-Efficient Transfer from Sequential Behaviors for User Modeling and Recommendation. SIGIR2020
作者来自腾讯和谷歌
代码+数据集:https://github.com/fajieyuan/SIGIR2020_peterrec
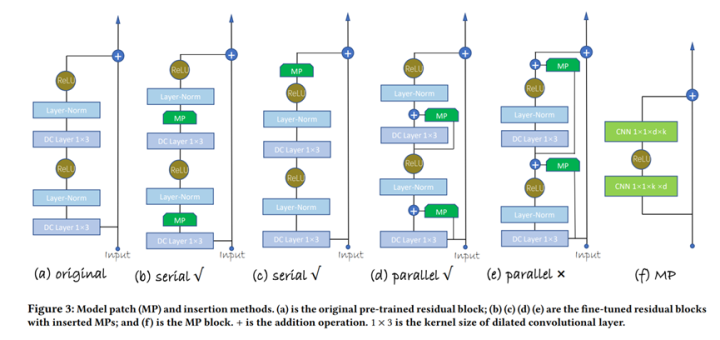
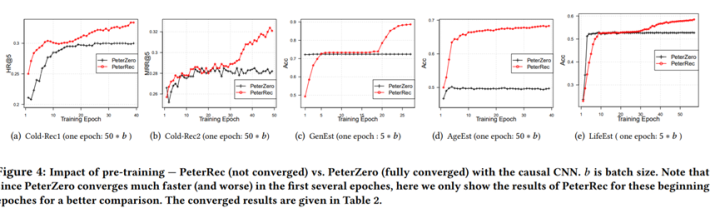
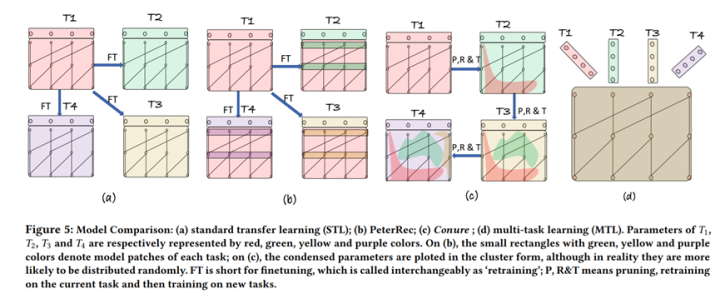
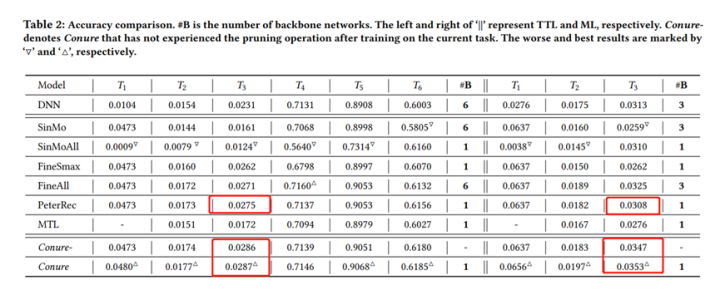
One Person, One Model, One World: Learning Continual User Representation without Forgetting. SIGIR2021.
作者来自腾讯和谷歌
代码+数据集:https://github.com/fajieyuan/SIGIR2021_Conure

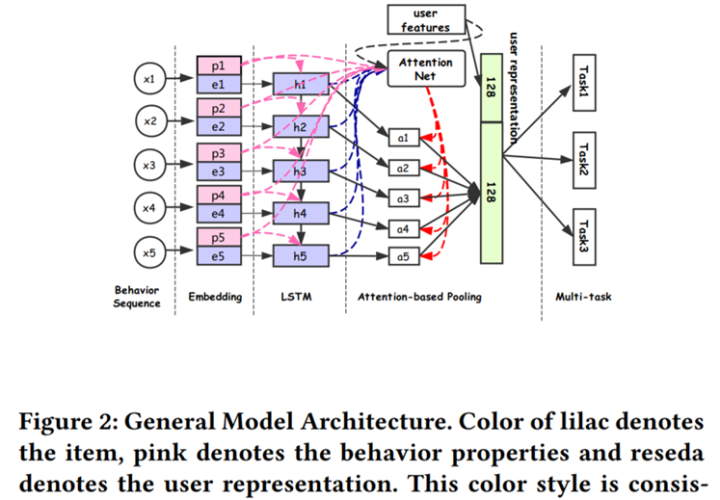
Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks. KDD2018.
作者来自Alibaba团队。
Github上暂未找到代码和数据集。

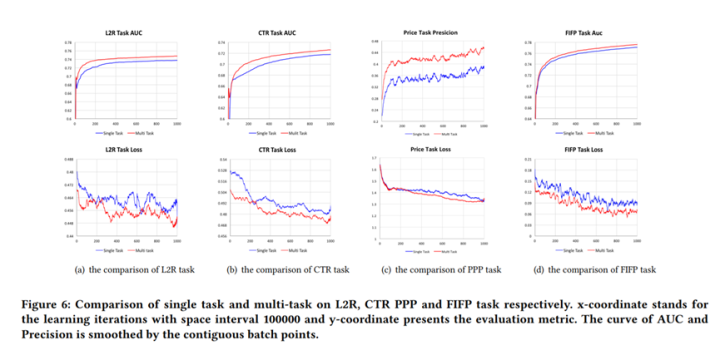
One4all User Representation for Recommender Systems in E-commerce. 2021年arxiv
论文动机也是认为学习general-purpose的表征能力在机器学习社区已经取得了很大的成功,同时指出在电商场景下,学习one4all的表征,可以用来做很多下游任务,例如用户画像预测、推送和推荐系统。为此,作者们系统的比较了电商场景下通用用户表征的建模方式和迁移效果,提出ShopperBERT模型,论文数据规模相当庞大,达到8亿点击行为(PeterRec数据接近1亿的行为),论文结果展示出预训练在多个下游任务上可以取得SOTA效果,该论文比较精彩的地方是做了非常广泛的分析实验,很有参考价值。
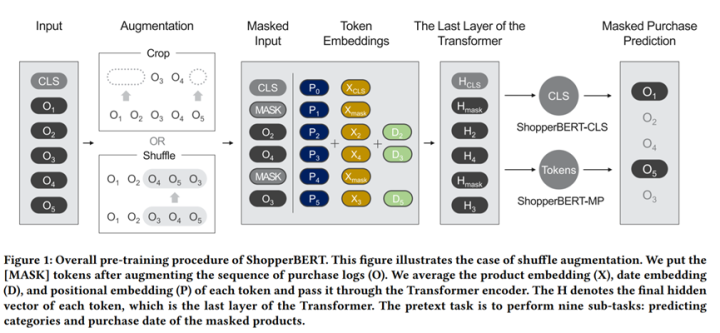
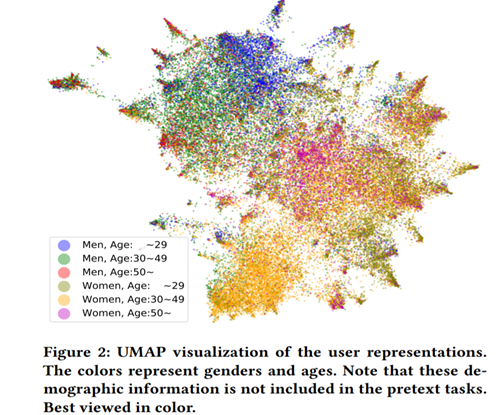
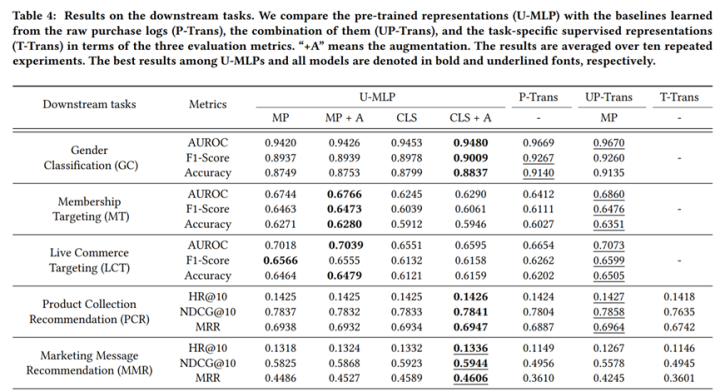
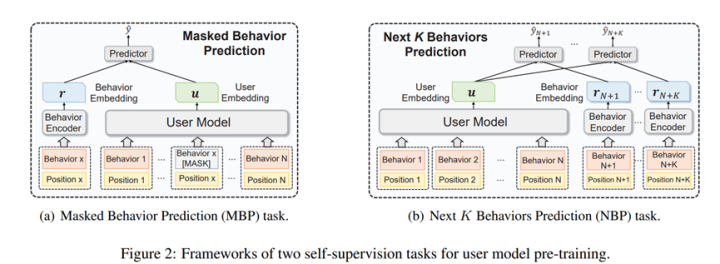
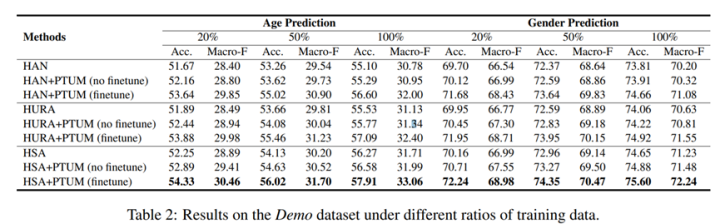
TUM: Pre-training User Model from Unlabeled User Behaviors via Self-supervision. 2020.findings EMNLP
作者来自清华和微软
用户专注用户建模任务,指出传统的用户建模需要label数据,然而,推荐系统大量的用户行为可以用来建立自监督学习机制,论文提出mask行为预测和next K行为预测学习用户表征模型,类似的,作者也是在下游任务(包括CTR预测和画像预测)中检测了表征的迁移能力,论文来自一个搜索引擎,具体不详。

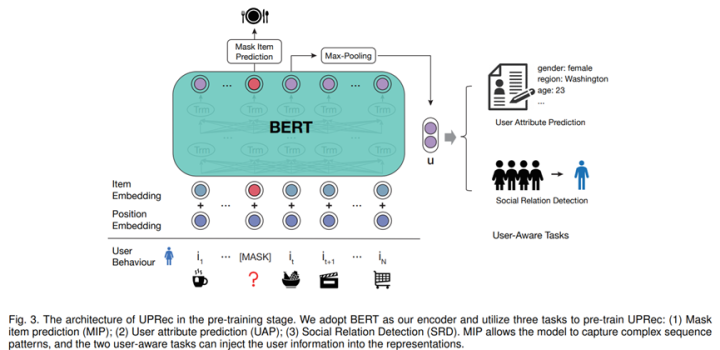
UPRec: User-Aware Pre-training for Recommender Systems. TKDE2021投稿
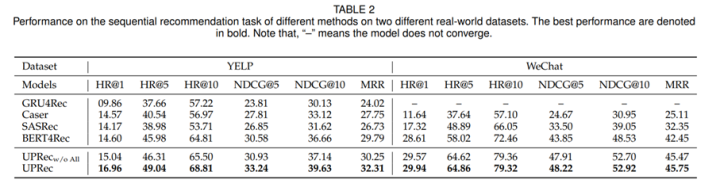
User-specific Adaptive Fine-tuning for Cross-domain Recommendations. TKDE2021,
作者来自中科院
本文作者动机与以上几篇论文类似,也是想尝试通过迁移学习解决用户冷启动问题,但是不同以上文章,论文提出了一种personalized微调方式,针对不同的用户采用不同的policy微调机制,作者强调pre-training的残差块不一定需要微调,有些用户的兴趣偏好(尤其是行为比较少的用户)可能会跟pre-training场景更加相似,那么这种情况大可不需要微调,直接使用pretraining自带的残差块即可。论文通过强化学习手段实现user-specific微调技术。效果展示出这种自适应微调效果好于常规的各种finetune技术。
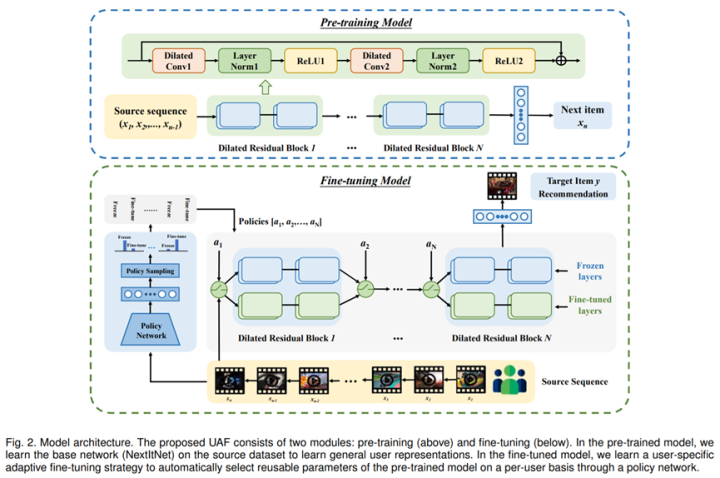
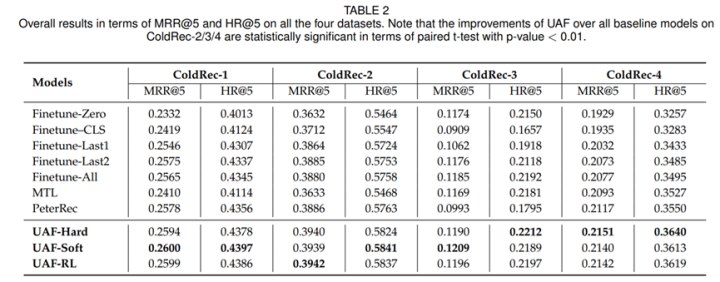
Scaling Law for Recommendation Models: Towards General-purpose User Representations.
动机就不多说了,还是general-purpose用户表征的迁移学习,不过个人感觉这篇论文写的非常漂亮,阅读起来感觉也是非常舒服,论文主要关注scale效果,大有效仿GPT的感觉,论文提出CLUE算法,基于最新的比较学习(contrastive learning),多目标学习用户表征,然后探索表征的迁移能力,论文用到的用户行为达到惊人的500亿(七个下游任务),是PeterRec训练样本的大概500倍,ShopperBERT的60倍以上,有望成为推荐系统领域大模型预训练的里程碑工作。

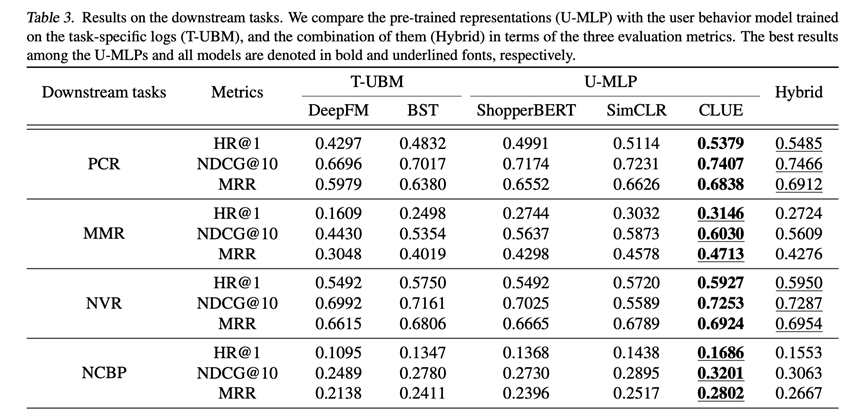
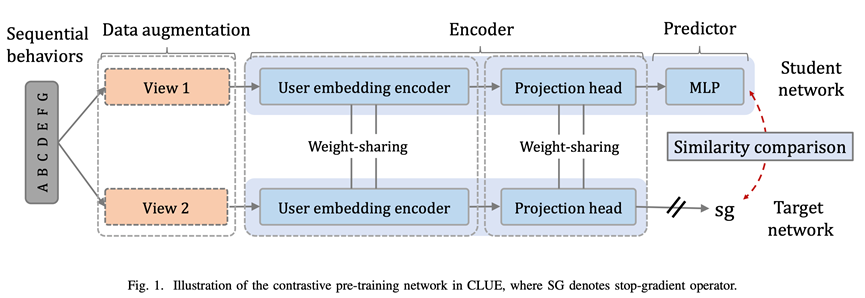
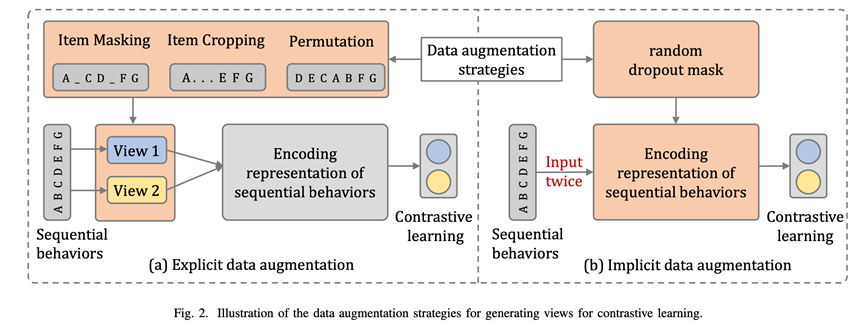
Learning Transferable User Representations with Sequential Behaviors via Contrastive Pre-training.ICDM2021
动机不多提了,很有意思的一点,这篇论文的名字也叫CLUE,与(8)相同,好像NLP里面也有这个名字,论文也是探索性质,指出PeterRec这种基于item level的训练方式容易破坏用户表征,或者是一种次优的表征,既然是用户表征就应该基于user level,对用户行为直接做比较学习,论文尝试了常见的显式数据提升方式和隐式的dropout方式,证实方法的有效性。
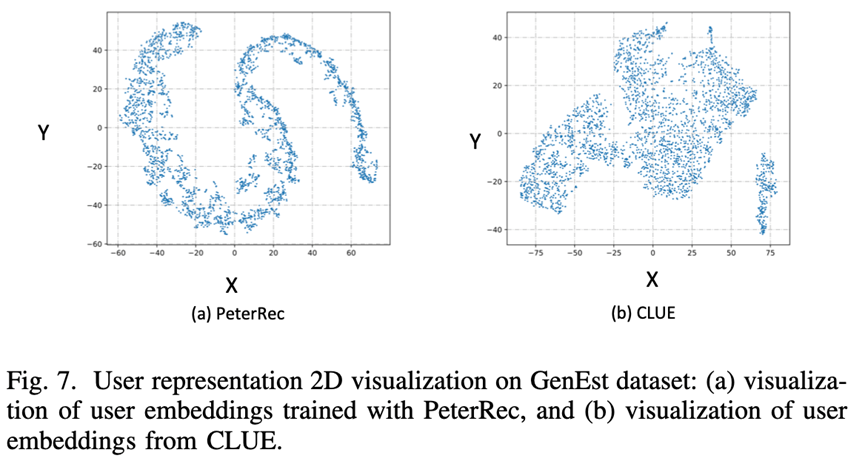
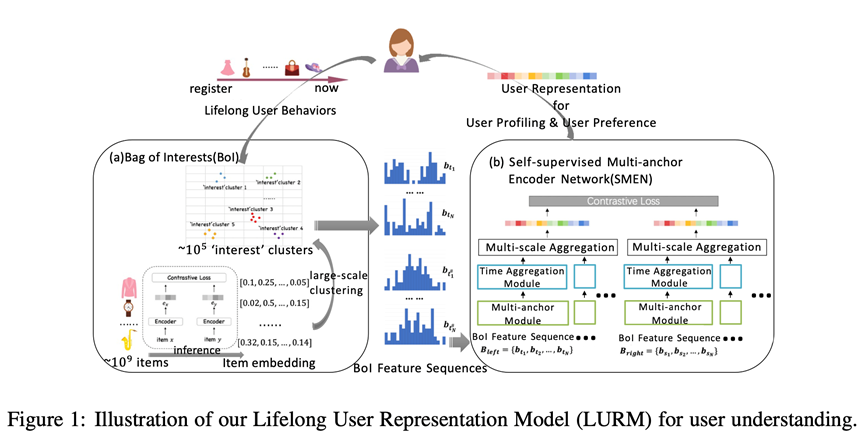
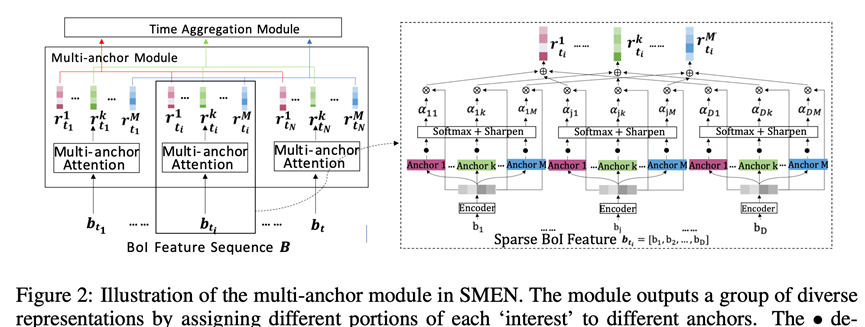
Learning Universal User Representations via Self-Supervised Lifelong Behaviors Modeling. 投稿ICLR2022,
作者来自阿里巴巴,暂未找到代码和数据。
该论文也是提出了一种通用的用户表征终生学习机制,起名LURM,LURM包含了几个重要的组件(BoI和SMEN),通过比较学习学习用户通用表征能力,论文提出了首个具有建模lifelong行为序列的通用表征算法,论文还没读完,看起来比较干,论文呈现比较浓厚的阿里风格。不过看openreview审稿意见,论文本次被ICLR2022接受概率可能不太大,被指出实验部分缺少一些近期相关baselines的比较(如PTUM和PeterRec),其他评论意见不在此罗列,感兴趣的也可以参考openreview官网学习。整体上讲,论文水平感觉还是挺不错的,做了一些有意义的探索,值得学习。