
【系统回顾】深度强化学习预训练
机器之心专栏 机器之心编辑部
本文中,来自上海交通大学和腾讯的研究者系统地回顾了现有深度强化学习预训练研究,并提供了这些方法的分类,同时对每个子领域进行了探讨。
近年来,强化学习 (RL) 在深度学习的带动下发展迅速,从游戏到机器人领域的各种突破,激发了人们对设计复杂、大规模 RL 算法和系统的兴趣。然而,现有 RL 研究普遍让智能体在面对新的任务时只能从零开始学习,难以利用预先获取的先验知识来辅助决策,导致很大的计算开销。
而在监督学习领域,预训练范式已经被验证为有效的获得可迁移先验知识的方式,通过在大规模数据集上进行预训练,网络模型能够快速适应不同的下游任务上。相似的思路同样在 RL 中有所尝试,尤其是近段时间关于 “通才” 智能体 [1, 2] 的研究,让人不禁思考是否在 RL 领域也能诞生如 GPT-3 [3] 那样的通用预训练模型。
然而,预训练在 RL 领域的应用面临着诸多挑战,例如上下游任务之间的显著差异、预训练数据如何高效获取与利用、先验知识如何有效迁移等问题都阻碍了预训练范式在 RL 中的成功应用。同时,过往研究考虑的实验设定和方法存在很大差异,这令研究者很难在现实场景下设计合适的预训练模型。
为了梳理预训练在 RL 领域的发展以及未来可能的发展方向,来自上海交通大学和腾讯的研究者撰文综述,讨论现有 RL 预训练在不同设定下的细分方法和待解决的问题。

论文地址:https://arxiv.org/pdf/2211.03959.pdf
RL 预训练简介
强化学习(RL)为顺序决策提供了一个通用的数学形式。通过 RL 算法和深度神经网络,在不同领域的各种应用上实现了以数据驱动的方式、优化指定奖励函数学习到的智能体取得了超越人类的表现。然而,虽然 RL 已被证明可以有效地解决指定任务,但样本效率和泛化能力仍然是阻碍 RL 在现实世界应用中的两大障碍。在 RL 研究中,一个标准的范式是让智能体从自己或他人收集的经验中学习,针对单一任务,通过随机初始化来优化神经网络。与之相反,对人类来说,世界先验知识对决策过程有很大的帮助。如果任务与以前看到的任务有关,人类倾向于复用已经学到的知识来快速适应新的任务,而不需要从头开始学习。因此,与人类相比, RL 智能体存在数据效率低下问题,而且容易出现过拟合现象。
然而,机器学习其他领域的最新进展积极倡导利用从大规模预训练中构建的先验知识。通过对广泛的数据进行大规模训练,大型基础模型 (foundation models) 可以快速适应各种下游任务。这种预训练 - 微调范式在计算机视觉和自然语言处理等领域已被证明有效。然而,预训练还没有对 RL 领域产生重大影响。尽管这种方法很有前景,但设计大规模 RL 预训练的原则面临诸多挑战。1)领域和任务的多样性;2)有限的数据源;3)快速适应解决下游任务的难度。这些因素源于 RL 的内在特征,需要研究者加以特别考虑。
预训练对 RL 有很大的潜力,这项研究可以作为对这一方向感兴趣的人的起点。本文中,研究者试图对现有深度强化学习的预训练工作进行系统的回顾。
近年来,深度强化学习预训练经历了几次突破性进展。首先,基于专家示范的预训练使用监督学习来预测专家所采取的行动,已经在 AlphaGo 上得到应用。为了追求更少监督的大规模预训练,无监督 RL 领域发展迅速,它允许智能体在没有奖励信号的情况下从与环境的互动中学习。此外,离线强化学习 (offline RL) 发展迅猛,又促使研究人员进一步考虑如何利用无标签和次优的离线数据进行预训练。最后,基于多任务和多模态数据的离线训练方法进一步为通用的预训练范式铺平了道路。
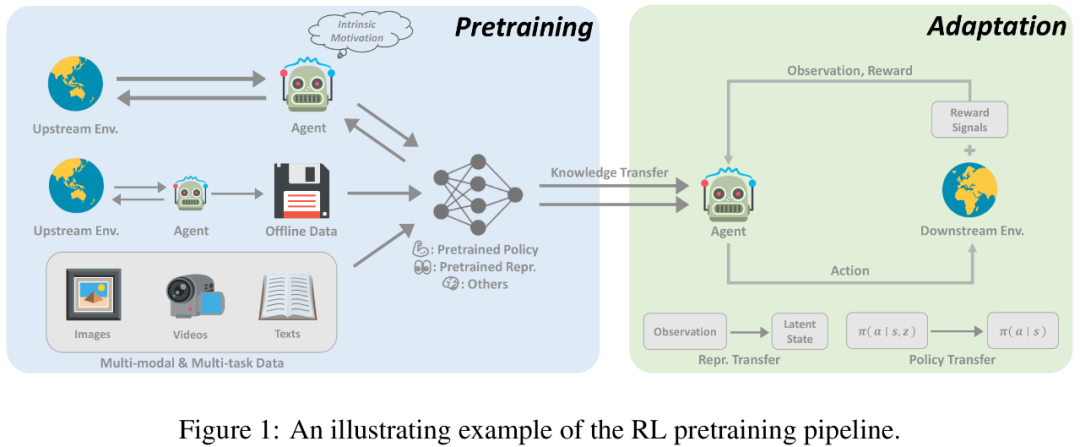
在线预训练
以往 RL 的成功都是在密集和设计良好的奖励函数下实现的。在诸多领域取得巨大进展的传统 RL 范式,在扩展到大规模预训练时面临两个关键挑战。首先,RL 智能体很容易过拟合,用复杂的任务奖励预训练得到的智能体很难在从未见过的任务上取得很好的性能。此外,设计奖励函数通常十分昂贵,需要大量专家知识,这在实际中无疑是个很大的挑战。
无奖励信号的在线预训练可能会成为学习通用先验知识的可用解决方案,并且是无需人工参与的监督信号。在线预训练旨在在没有人类监督的情况下,通过与环境的交互来获得先验知识。在预训练阶段,智能体被允许与环境进行长时间的交互,但不能获得外在奖励。这种解决方案,也被称为无监督 RL,近年来研究者一直在积极研究。
为了激励智能体在没有任何监督信号的情况下从环境中获取先验知识,一种成熟的方法是为智能体设计内在奖励 (intrinsic reward) ,鼓励智能体通过收集多样的经验或掌握可迁移的技能,相应地设计奖励机制。先前研究已经表明,通过内在奖励和标准 RL 算法进行在线预训练,智能体能够快速适应下游任务。

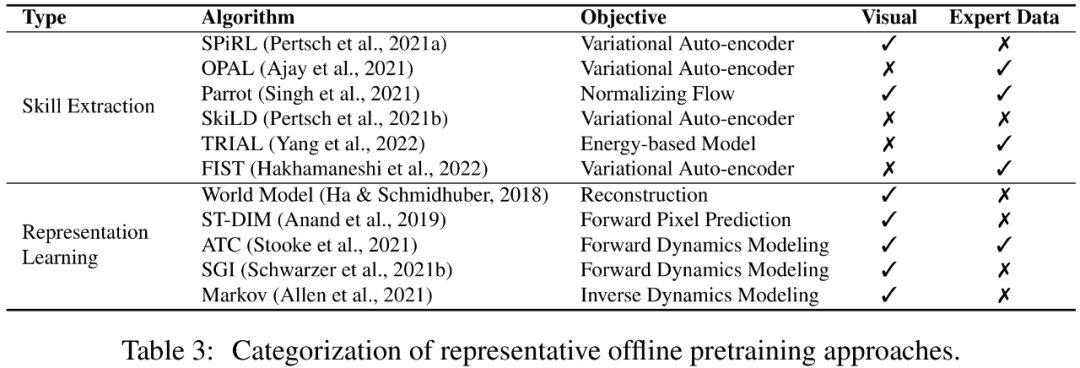
离线预训练
尽管在线预训练在无需人类监督的情况下能够取得很好的预训练效果,但对于大规模应用来说,在线预训练仍然是有限的。毕竟,在线的交互与在大型和多样化的数据集上进行训练的需求在一定程度上是互斥的。为了解决这个问题,人们往往希望将数据收集和预训练环节脱钩,直接利用从其他智能体或人类收集的历史数据进行预训练。
一个可行的解决方案是离线强化学习。离线强化学习的目的是从离线数据中获得一个奖励最大化的 RL 策略。其所面临的一个基本挑战是分布偏移问题,即训练数据和测试期间看到的数据之间的分布差异。现有的离线强化学习方法关注如何在使用函数近似时解决这一挑战。例如,策略约束方法明确要求学到的策略避免采取数据集中未见的动作,价值正则化方法则通过将价值函数拟合到某种形式的下限,缓解了价值函数的高估问题。然而,离线训练的策略是否能泛化到离线数据集中未见的新环境中,仍然没有得到充分的探索。
或许,我们可以避开 RL 策略的学习,而是利用离线数据学习有利于下游任务的收敛速度或最终性能的先验知识。更有趣的是,如果我们的模型能够在没有人类监督的情况下利用离线数据,它就有可能从海量的数据中获益。本文中,研究者把这种设定称为离线预训练,智能体可以从离线数据中提取重要的信息(例如,良好的表征和行为先验)。
迈向通用智能体
在单一环境和单一模态下的预训练方法主要集中于以上提到的在线预训练和离线预训练设定,而在最近,领域内的研究者对建立一个单一的通用决策模型的兴趣激增(例如,Gato [1] 和 Multi-game DT [2]),使得同一模型能够处理不同环境中不同模态的任务。为了使智能体能够从各种开放式任务中学习并适应这些任务,该研究希望能够利用不同形式的大量先验知识,如视觉感知和语言理解。更为重要地是,如果研究者能成功地在 RL 和其他领域的机器学习之间架起一座桥梁,将以前的成功经验结合起来,或许可以建立一个能够完成各种任务的通用智能体模型。
[1] Reed, Scott, et al. "A generalist agent." arXiv preprint arXiv:2205.06175 (2022).
[2] Lee, Kuang-Huei, et al. "Multi-Game Decision Transformers." arXiv preprint arXiv:2205.15241 (2022).
[3] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
推荐阅读
全网最全速查表:Python 机器学习 搭建完美的Python 机器学习开发环境 训练集,验证集,测试集,交叉验证