
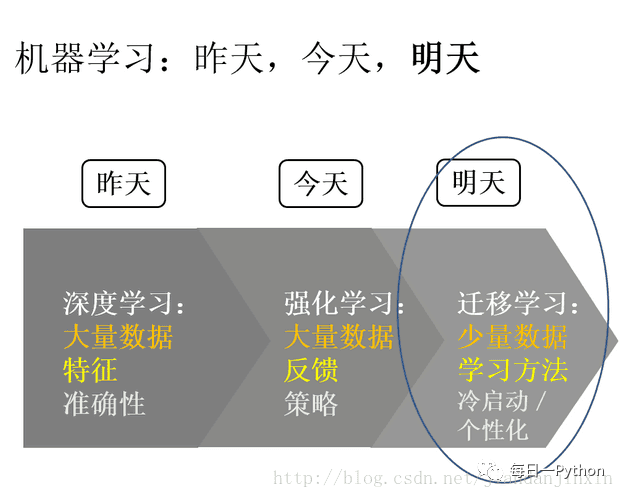
深度学习,强化学习 ,迁移学习
本文转自csdn,原文链接:https://blog.csdn.net/jiandanjinxin/article/details/54133521
深度学习的局限
表达能力的限制。因为一个模型毕竟是一种现实的反映,等于是现实的镜像,它能够描述现实的能力越强就越准确,而机器学习都是用变量来描述世界的,它的变量数是有限的,深度学习的深度也是有限的。另外它对数据的需求量随着模型的增大而增大,但现实中有那么多高质量数据的情况还不多。所以一方面是数据量,一方面是数据里面的变量、数据的复杂度,深度学习来描述数据的复杂度还不够复杂。
缺乏反馈机制。目前深度学习对图像识别、语音识别等问题来说是最好的,但是对其他的问题并不是最好的,特别是有延迟反馈的问题,例如机器人的行动,AlphaGo下围棋也不是深度学习包打所有的,它还有强化学习的一部分,反馈是直到最后那一步才知道你的输赢。还有很多其他的学习任务都不一定是深度学习才能来完成的。
针对深度学习的局限性,或许强化学习和迁移学习能够解决相应的问题。

强化学习是什么?
强化学习(Reinforcement Learning),就是智能系统从环境到行为映射的学习,以使奖励信号(强化信号)函数值最大。
强化学习不同于连接主义学习中的监督学习,主要表现在教师信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统RLS(reinforcement learning system)如何去产生正确的动作。由于外部环境提供的信息很少,RLS必须靠自身的经历进行学习。
通过这种方式,RLS在行动-评价的环境中获得知识,改进行动方案以适应环境。
之前ALPHGO 大战 李世石 4:1
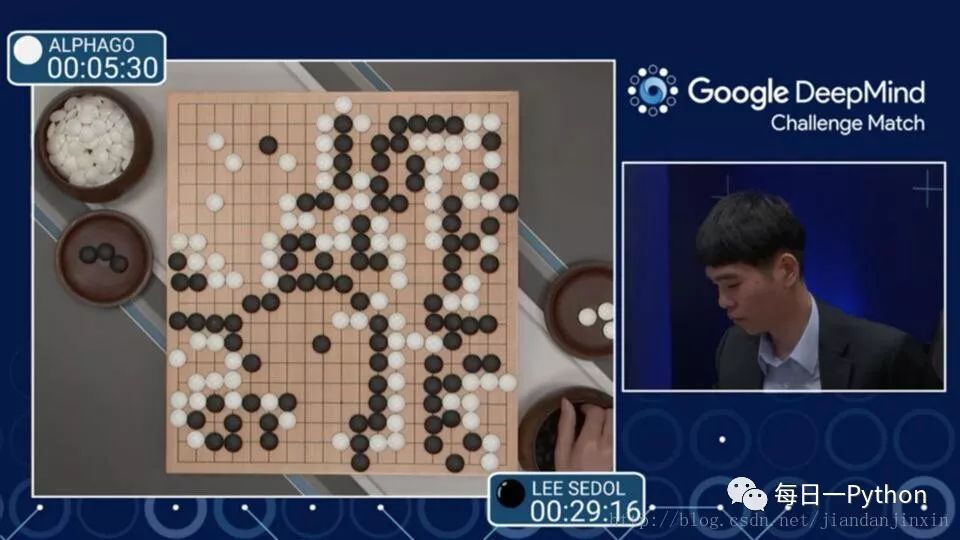
目前的 Master 大战中日韩围棋世界冠军 60:0
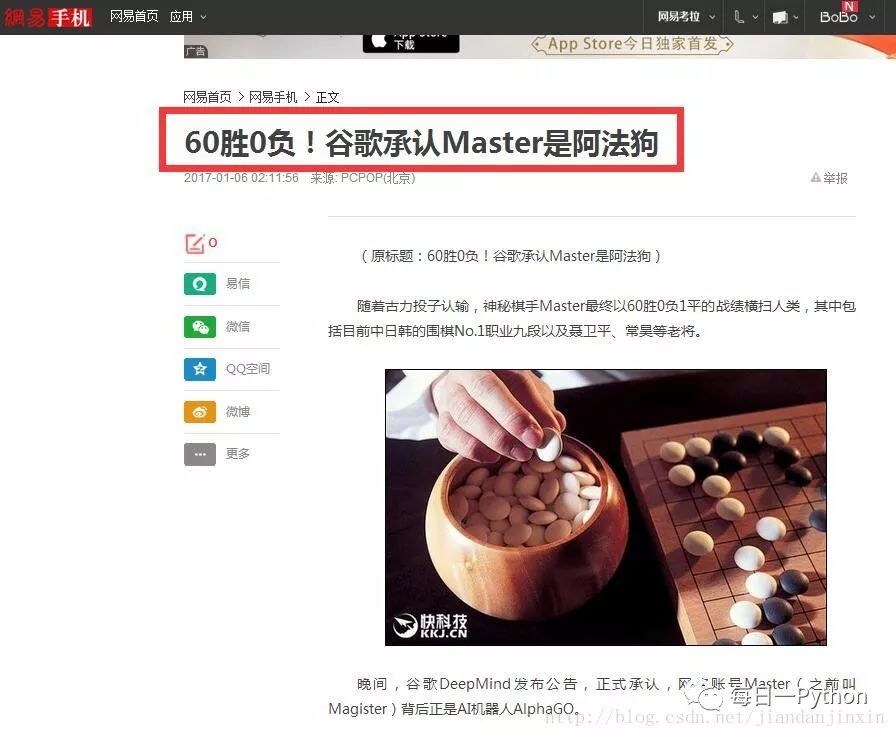
背后的 DeepMind 就是将深度学习应用到强化学习中去的范例。
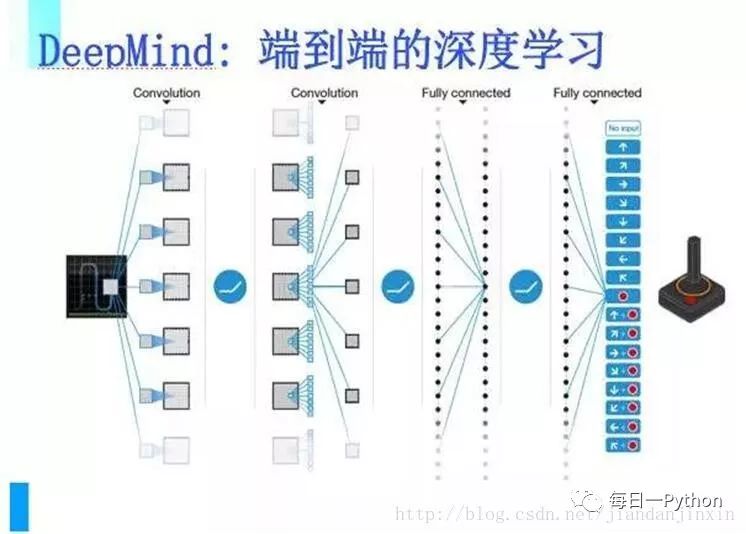
DeepMind把端到端的深度学习应用在强化学习上,使得强化学习能够应付大数据,因此能在围棋上把人类完全击倒,它做到这样是通过完全的自学习、自我修炼、自我改正,然后一个一个迭代。
深度学习是一种端到端的学习方式,整个学习过程中不需要中间的和显著的人类参与。直接把海量数据投放到算法中,让数据自己说话,系统会自动从数据中学习。从输入到输出是一个完全自动的过程。
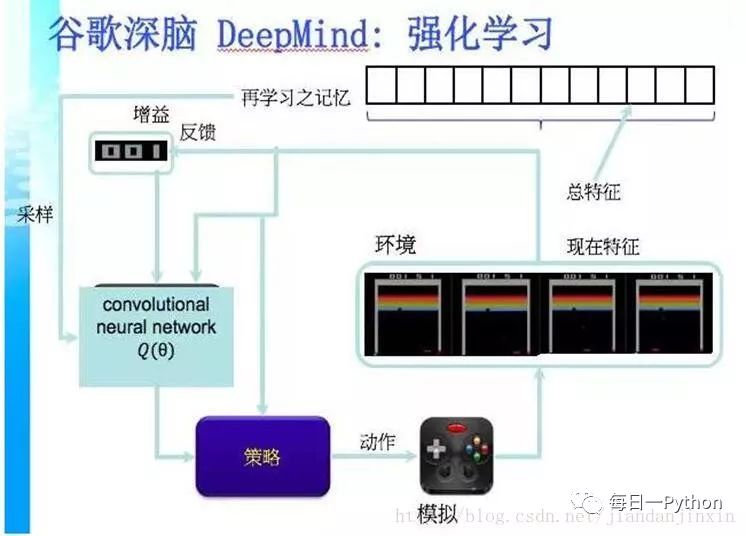
永动机器学习
CMU大学的例子,用中文来说是永动机器学习,这个机器不断在网上扒一些网页,在每个网页里面都学到一些知识,把这些知识综合起来,变成几千万条知识,这些知识又会衍生新的知识。那么我们看到从下到上是随着时间,知识量在增长。但是它到了某一个程度实际上是不能再往上走了,因为知识会自我矛盾。这个时候就需要人来进行一部分的调节,把一部分不正确的知识去掉,让它继续能成长。这个过程为什么会发生呢?
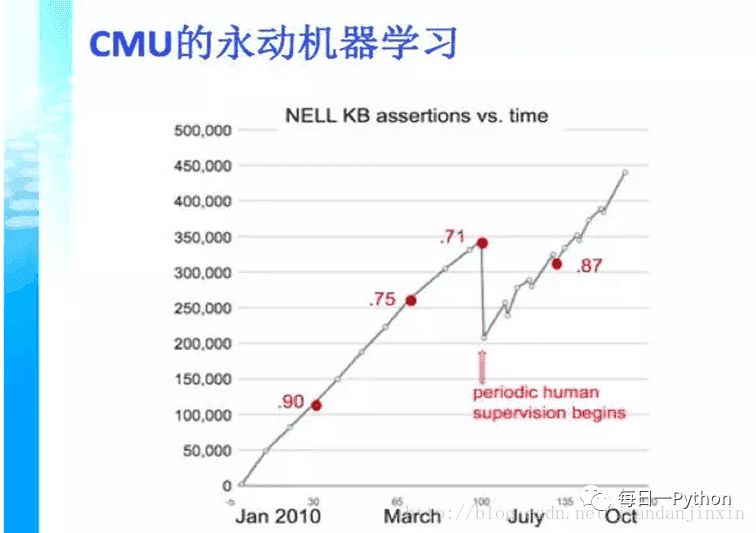
是因为机器学习有一个很严重的现象,就是自我偏差,这种偏差可以体现在统计学的一个重要概念中,就是我们获得的数据也许是一个有偏数据,我们可能建了一个模型,对大部分的数据都有用,但其中有一些特例。我们如何来处理这些特例,如何来处理我们训练数据和应用数据之间的偏差,这是我们下一步要研究的内容。
两个问题:数据量大,有偏数据;数据量少。

为了解决以上问题,下面我们来看几个示例




以上示例都是人类的迁移学习的能力。
迁移学习是什么?
所谓迁移学习,或者领域适应Domain Adaptation,一般就是要将从源领域(Source Domain)学习到的东西应用到目标领域(Target Domain)上去。源领域和目标领域之间往往有gap/domain discrepancy(源领域的数据和目标领域的数据遵循不同的分布)。
迁移学习能够将适用于大数据的模型迁移到小数据上,实现个性化迁移。
迁移什么,怎么迁移,什么时候能迁移,这是迁移学习要解决的主要问题。
迁移学习能解决那些问题?
小数据的问题。比方说新开一个网店,卖一种新的糕点,没有任何的数据,就无法建立模型对用户进行推荐。但用户买一个东西会反映到用户可能还会买另外一个东西,所以如果知道用户在另外一个领域,比方说卖饮料,已经有了很多很多的数据,利用这些数据建一个模型,结合用户买饮料的习惯和买糕点的习惯的关联,就可以把饮料的推荐模型给成功地迁移到糕点的领域,这样,在数据不多的情况下可以成功推荐一些用户可能喜欢的糕点。这个例子就说明,有两个领域,一个领域已经有很多的数据,能成功地建一个模型,有一个领域数据不多,但是和前面那个领域是关联的,就可以把那个模型给迁移过来。
个性化的问题。比如每个人都希望自己的手机能够记住一些习惯,这样不用每次都去设定它,怎么才能让手机记住这一点呢?其实可以通过迁移学习把一个通用的用户使用手机的模型迁移到个性化的数据上面。
迁移学习四种实现方法
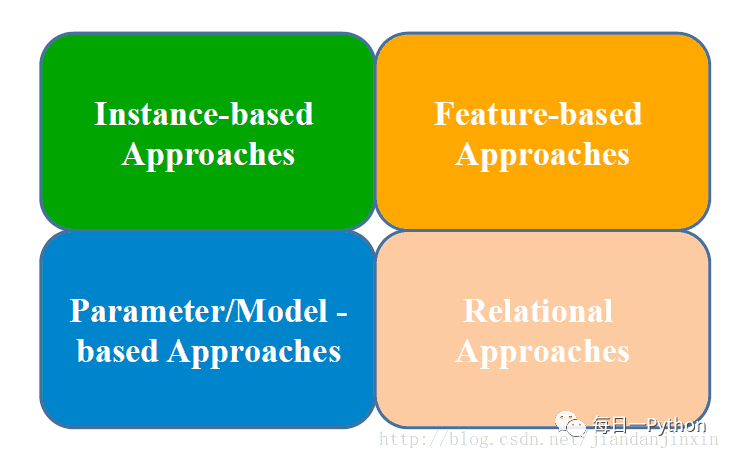
1. 样本迁移 Instance-based Transfer Learning

一般是对样本进行加权,给比较重要的样本较大的权重。
样本迁移即在数据集(源领域)中找到与目标领域相似的数据,把这个数据放大多倍,与目标领域的数据进行匹配。其特点是:需要对不同例子加权;需要用数据进行训练。
2. 特征迁移 Feature-based Transfer Learning

在特征空间进行迁移,一般需要把源领域和目标领域的特征投影到同一个特征空间里进行。
特征迁移是通过观察源领域图像与目标域图像之间的共同特征,然后利用观察所得的共同特征在不同层级的特征间进行自动迁移。
3. 模型迁移 Model-based Transfer Learning

整个模型应用到目标领域去,比如目前常用的对预训练好的深度网络做微调,也可以叫做参数迁移。
模型迁移利用上千万的图象训练一个图象识别的系统,当我们遇到一个新的图象领域,就不用再去找几千万个图象来训练了,可以原来的图像识别系统迁移到新的领域,所以在新的领域只用几万张图片同样能够获取相同的效果。模型迁移的一个好处是可以和深度学习结合起来,我们可以区分不同层次可迁移的度,相似度比较高的那些层次他们被迁移的可能性就大一些
4. 关系迁移 Relational Transfer Learning
社会网络,社交网络之间的迁移。

前沿的迁移学习方向
Reinforcement Transfer Learning
怎么迁移智能体学习到的知识:比如我学会了一个游戏,那么我在另一个相似的游戏里面也是可以应用一些类似的策略的
Transitive Transfer Learning
传递性迁移学习,两个domain之间如果相隔得太远,那么我们就插入一些intermediate domains,一步步做迁移
Source-Free Transfer Learning
不知道是哪个源领域
最后用一张图总结一下深度学习、强化学习、迁移学习的趋势
参考资料:
https://mp.weixin.qq.com/s?__biz=MzAwMjM2Njg2Nw==&mid=2653144126&idx=1&sn=d9633d71ed89590100422c85f6bdb845
http://mp.weixin.qq.com/s?__biz=MzI3MTA0MTk1MA==&mid=2651982064&idx=1&sn=92e65d423db5aa79d8c8c782afc19111&scene=1&srcid=0426Sj6blqQWPuyUb8qCswf3&from=singlemessage&isappinstalled=0#wechat_redirect
http://geek.csdn.net/news/detail/92051
http://www.leiphone.com/news/201612/hF1AX5yNwcxtf005.html
https://zhuanlan.zhihu.com/p/22023097
版权声明:本文为CSDN博主「帅气的弟八哥」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/jiandanjinxin/article/details/54133521
《数据科学与人工智能》公众号推荐朋友们学习和使用Python语言,需要加入Python语言群的,请扫码加我个人微信,备注【姓名-Python群】,我诚邀你入群,大家学习和分享。