
ACCV2020国际细粒度识别比赛季军方案解读及Tricks汇总
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
一、大赛介绍及挑战

55万的训练数据集中存在有大量的噪声数据
训练集中存在较多的图片标签错误
训练集与测试集不属于同一分布,且存在较大差异
训练集各类别图片数量呈长尾分布
细粒度挑战,类间差异小
二、解决方案



mixcut
随机颜色抖动
随机方向—镜像翻转;4方向随机旋转
随机质量—resize150~190,再放大到380;随机jpeg低质量有损压缩

随机缩放贴图

图片随机网格打乱重组

随机crop
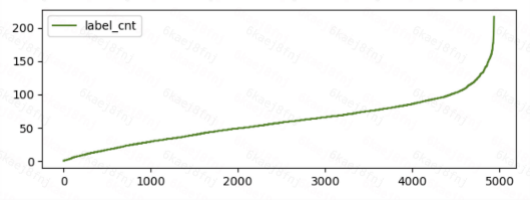
上采样数据均衡,每类数据采样至不少于最大类别图片数量的三分之一。
统计训练数据各类别概率分布,求log后初始化fc层偏置,并在训练过程中不更新fc层偏置。参考论文:Long-tail learning via logit adjustment
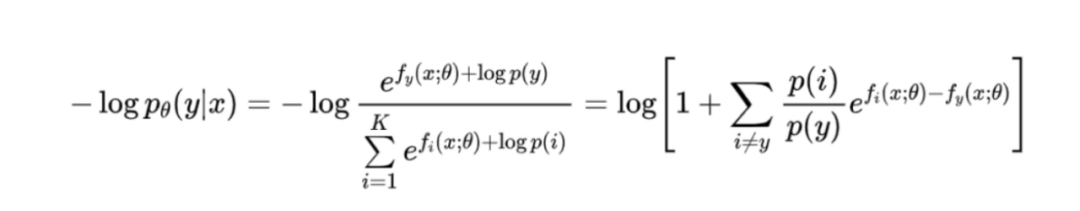
EfficientNet-b4
EfficientNet-b5
label smooth 0.2
base_lr=0.03
radam+sgd
cosine scheduler
分布式超大batch size(25*80=2000)训练
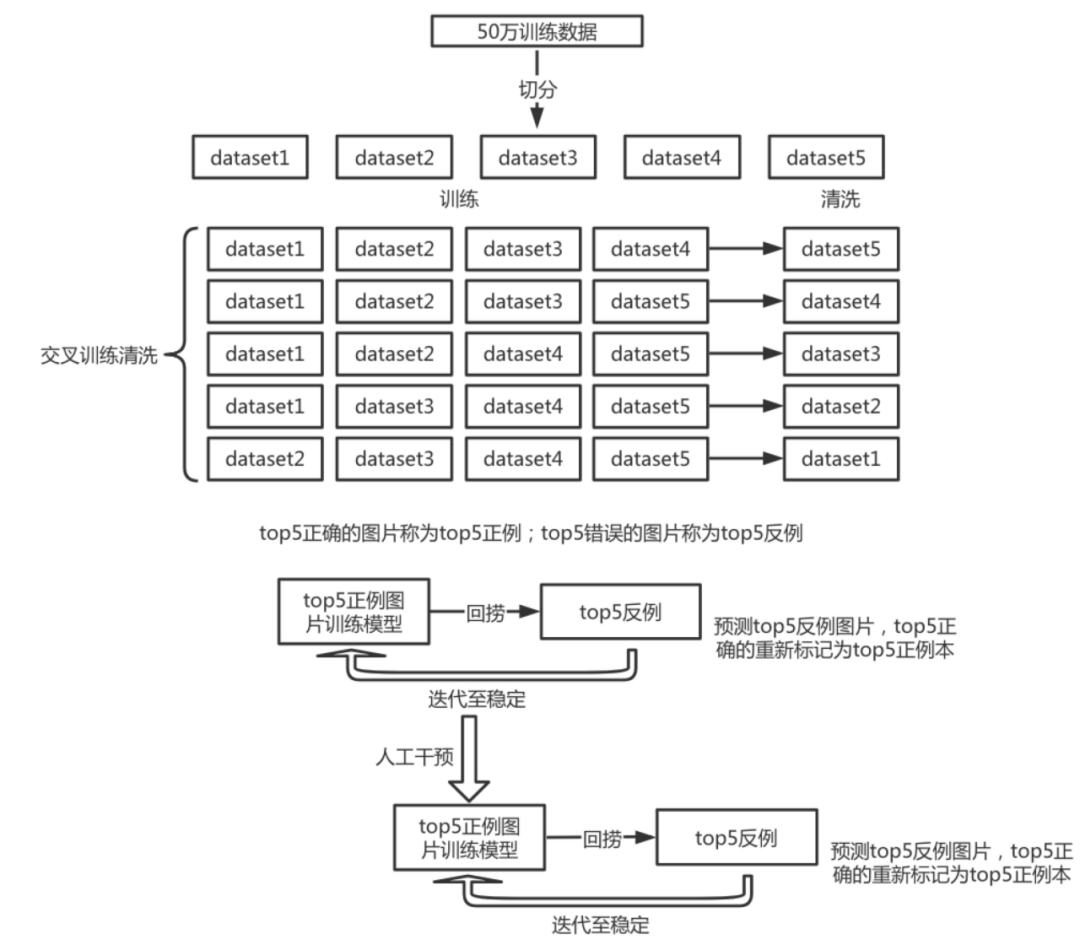
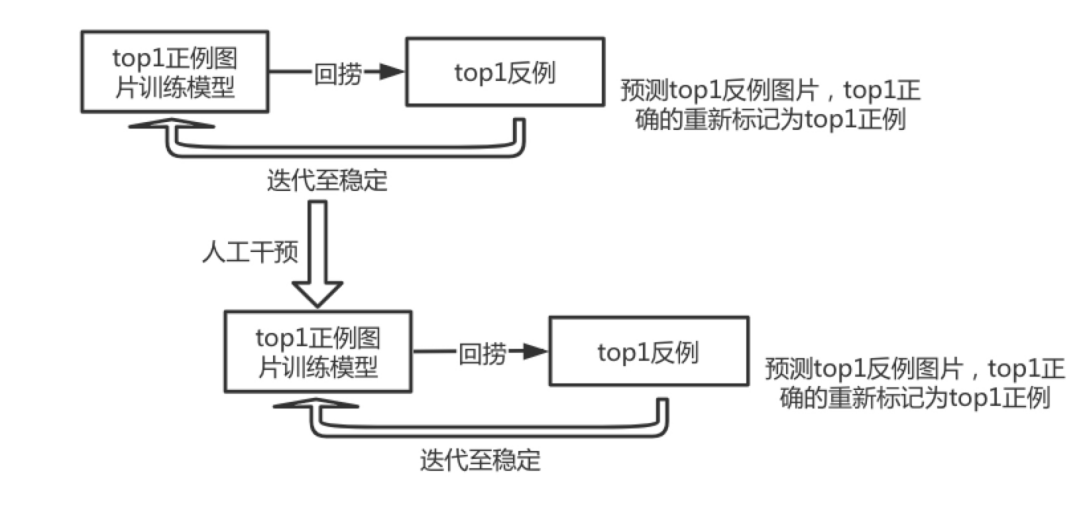
50+w训练集加20w测试集 ,纯模型蒸馏,采用KLDivLoss 损失函数
50+w训练集,模型蒸馏(KLDivLoss)*0.5 +标签(CrossEntropyLoss)* 0.5
取多个(8个)模型fc前一层特征,concat在一起训练一个fc层,训练过程中加随机数据增强
取多个(4个)模型fc前一层特征,concat在一起训练一个fc层,训练过程的数据处理与预测保持一致
取多个(15、9、8、6)模型的softmax,求平均
用以上多个ensemble模型结果投票作为最终结果
在预测测试集标签时,相比训练,中心crop出更小的尺寸。
训练:resize(img_size*1.15)+randomcrop(img_size);
测试:resize(img_size*1.35)+centercrop(img_size)
根据10万验证集,5000类,每类只有20张图片的先验,提交结果时,根据预测分值排序,每个类别最多只选取top25的预测,平衡后的提交可以提高0.5~1%精度。
三、总结
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
团队介绍:

下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:leetcode 开源书
在「AI算法与图像处理」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!
下载3 CVPR2020
在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

觉得不错就点亮在看吧
